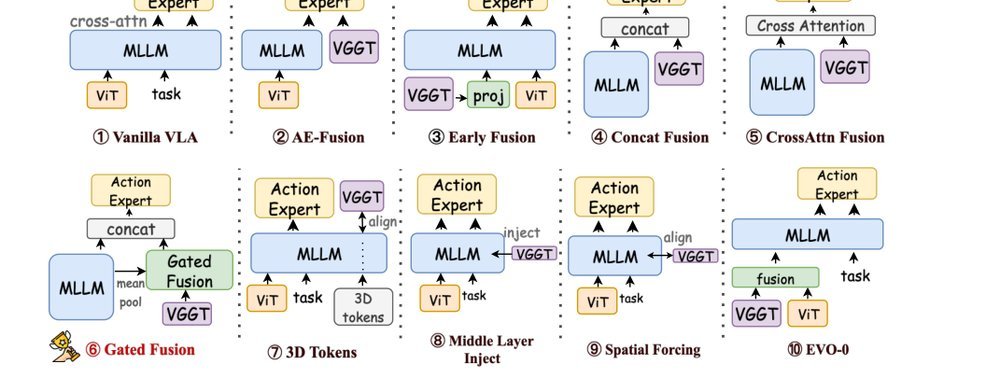
作者:Bin Yu, Shijie Lian, Xiaopeng Lin, Zhaolong Shen, Yuliang Wei, Haishan Liu, Changti Wu, Hang Yuan, Bailing Wang, Cong Huang, Kai Chen, HIT ZGCA ZGCI HUST · 单位:HKUST(GZ) · 会议/期刊:arXiv · 日期:2026-03-25 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 3D Vision Language Action Models