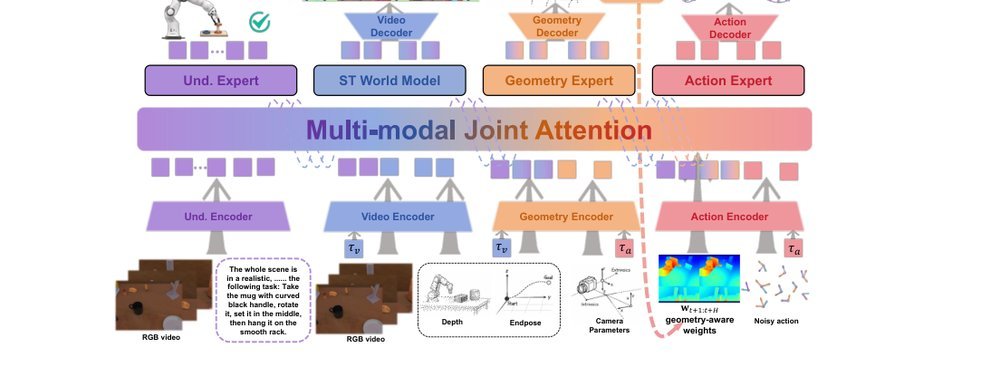
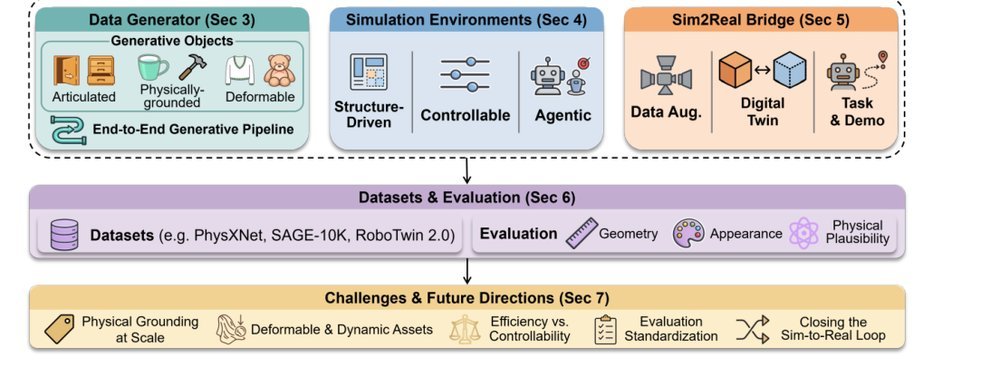
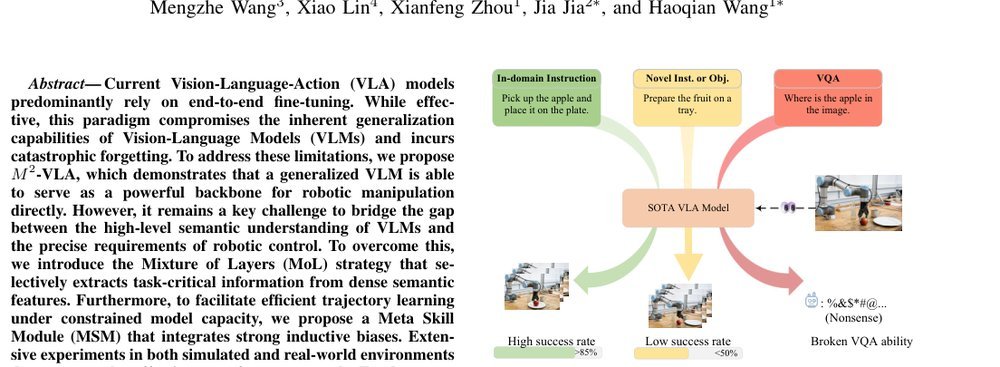
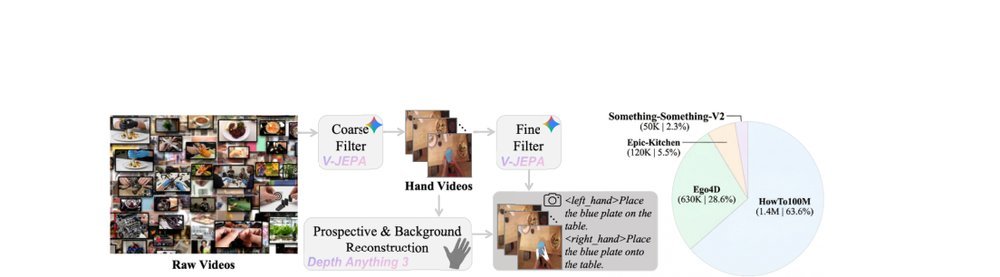
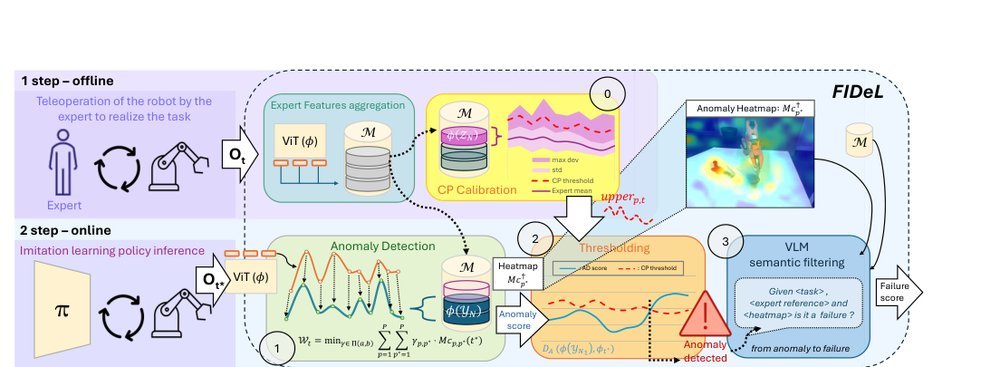
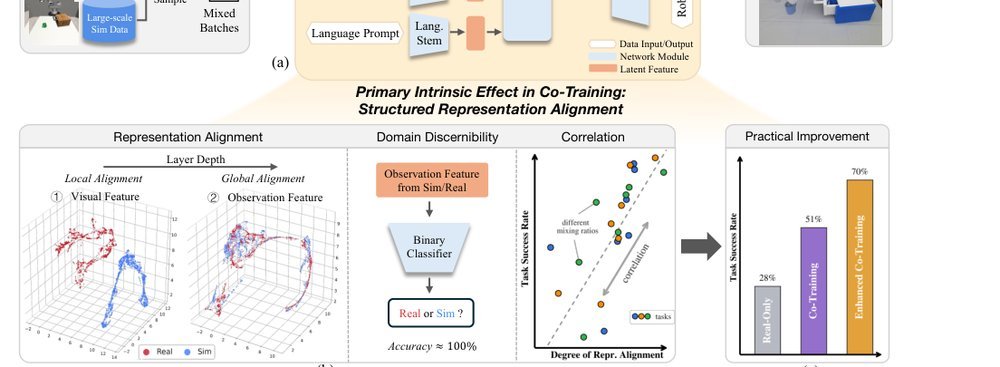
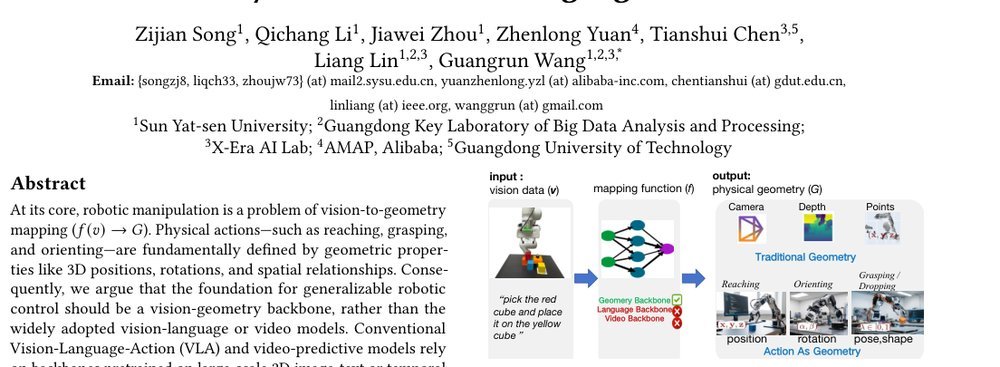
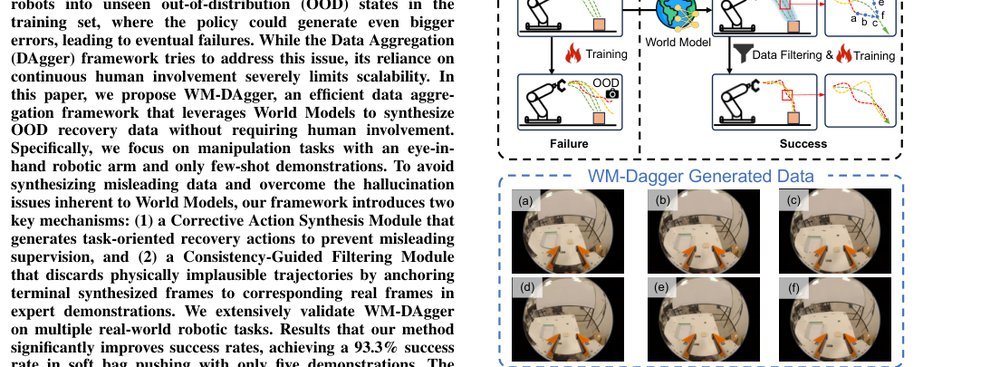
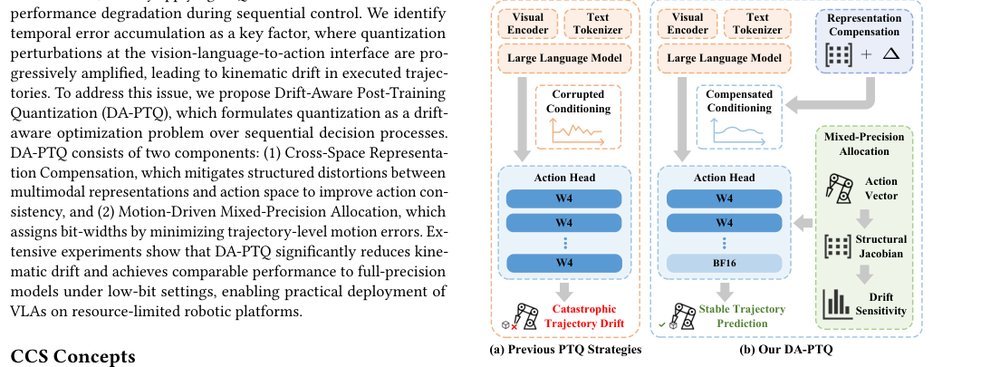
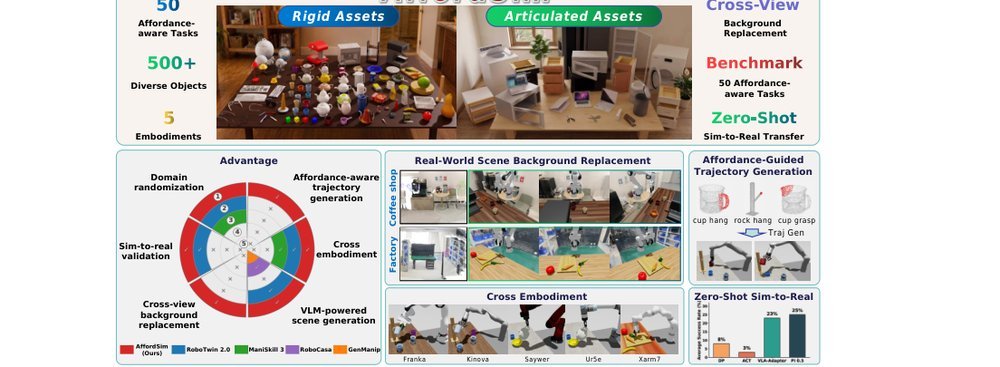
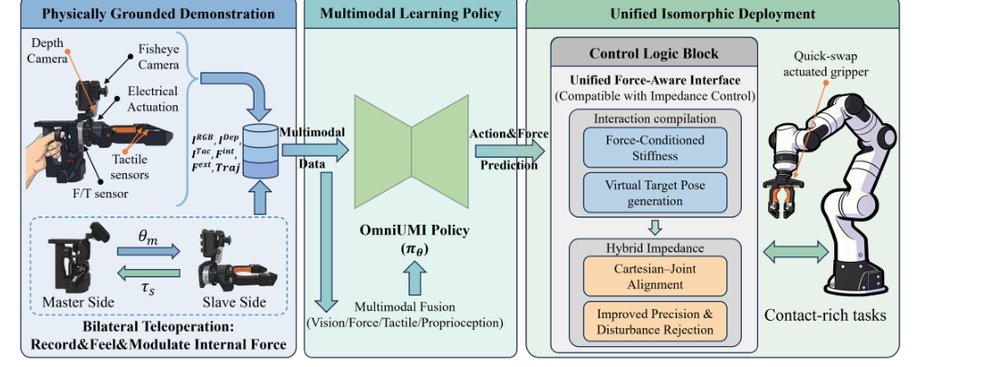
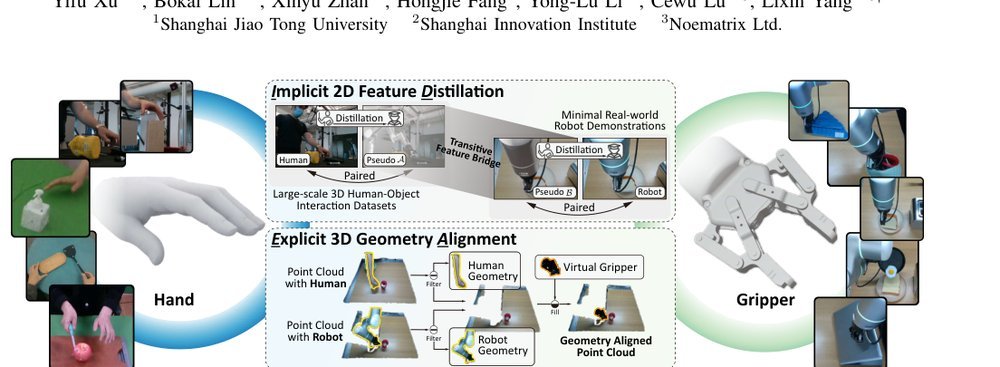
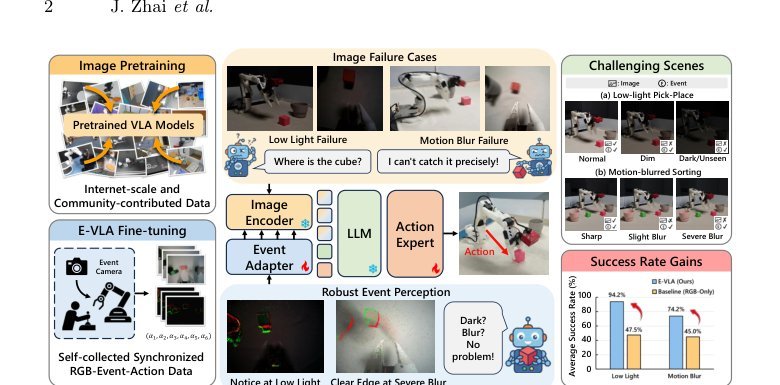
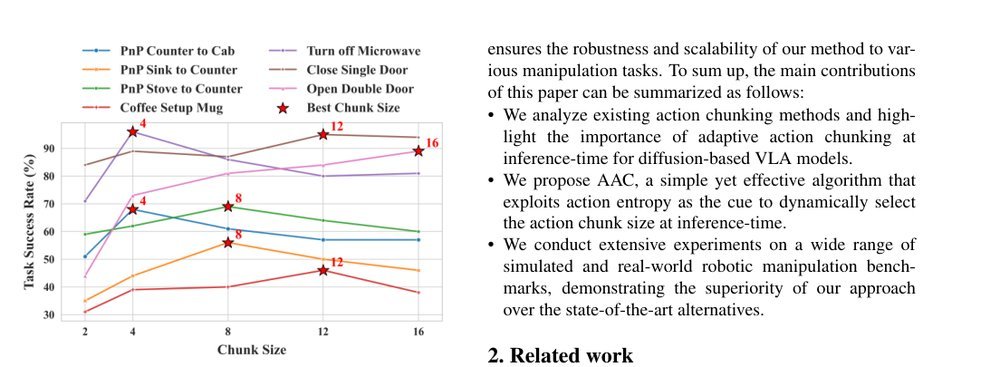
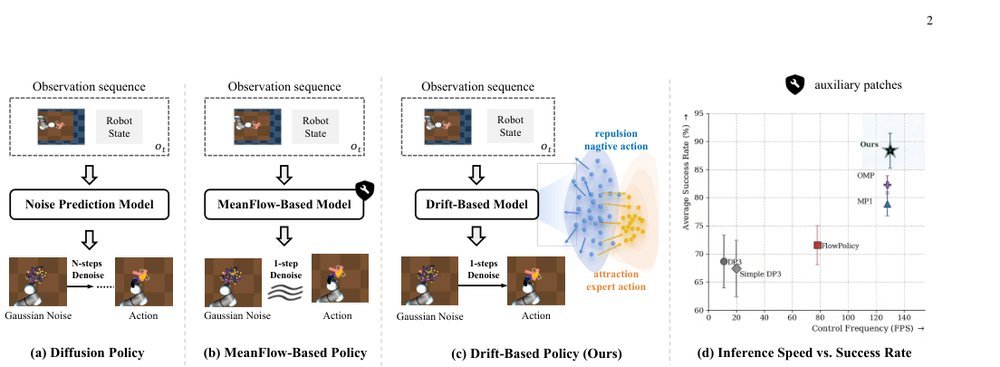
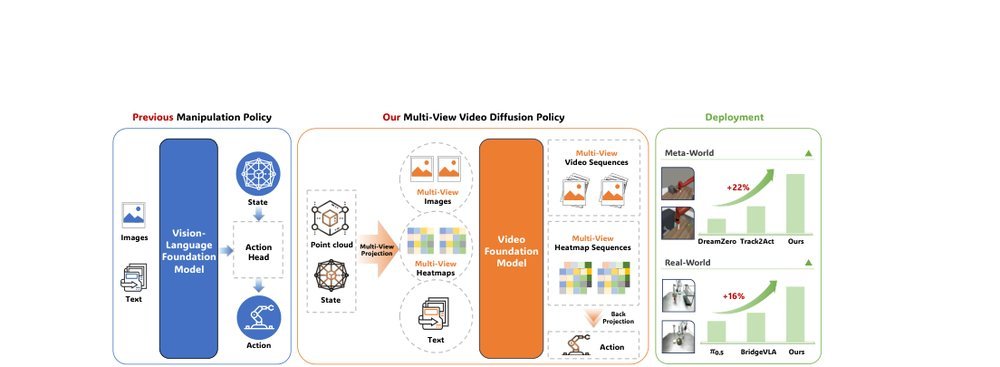
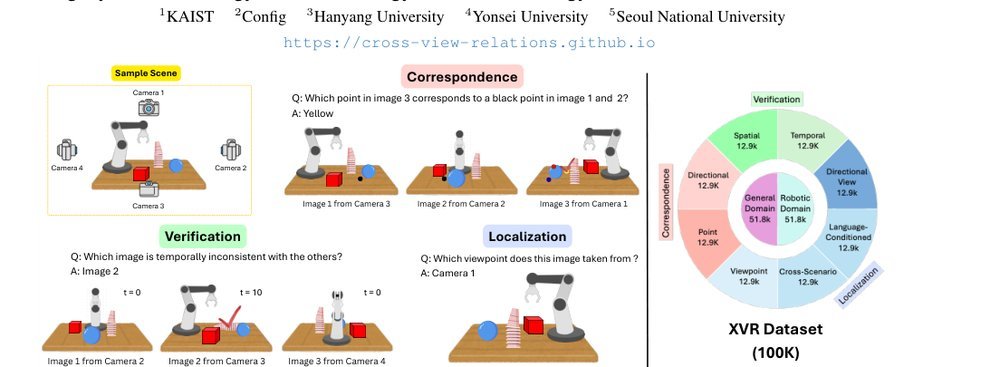
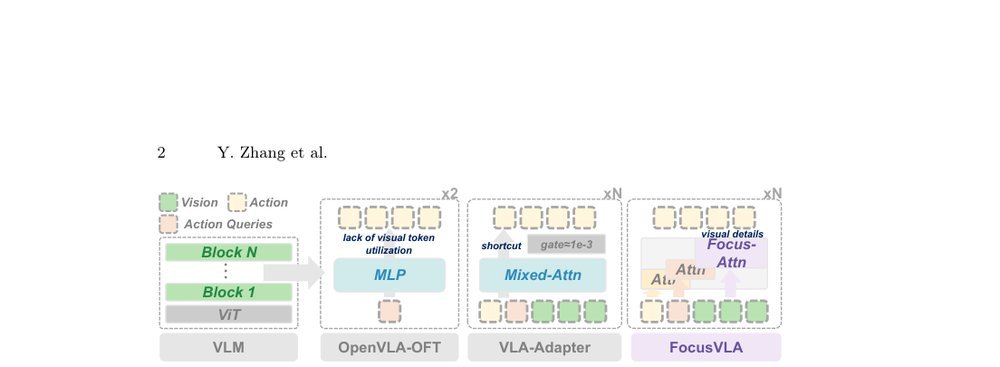
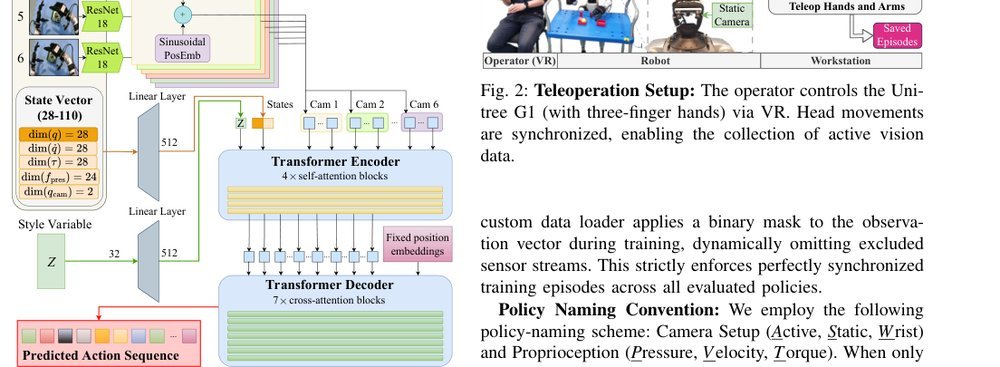
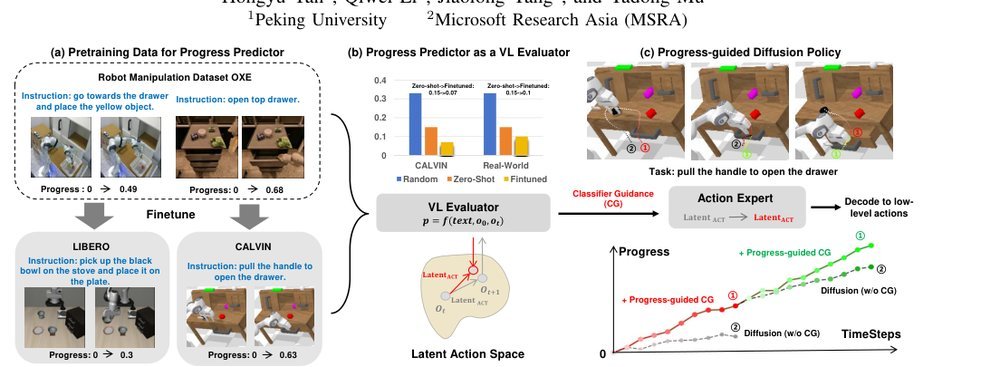
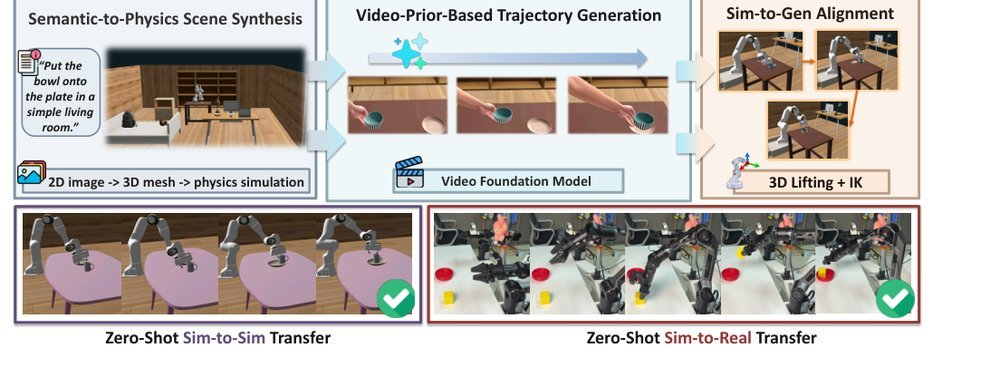
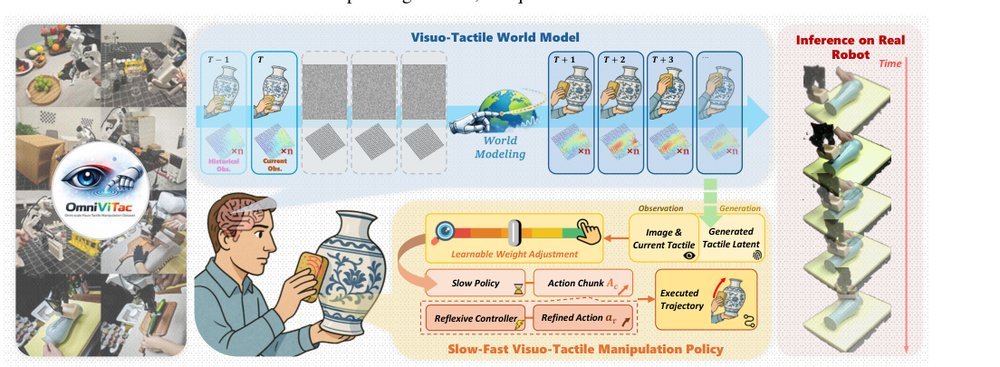
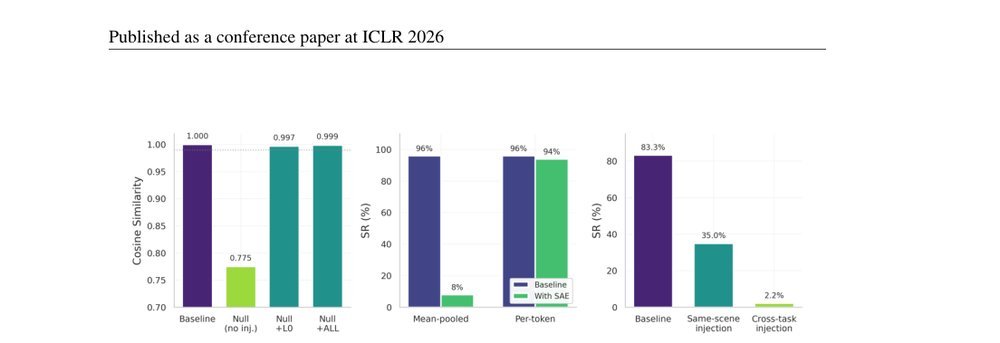
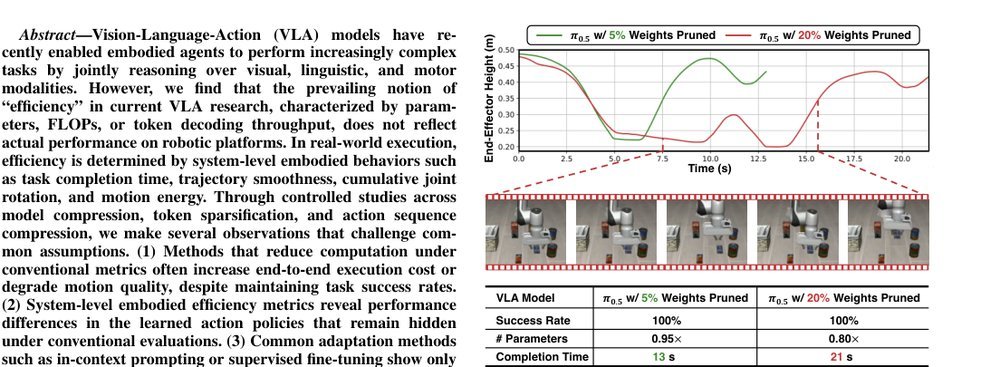
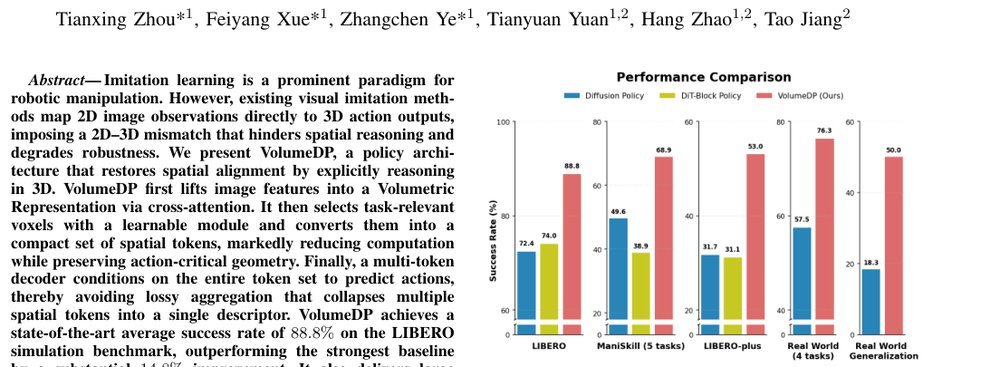
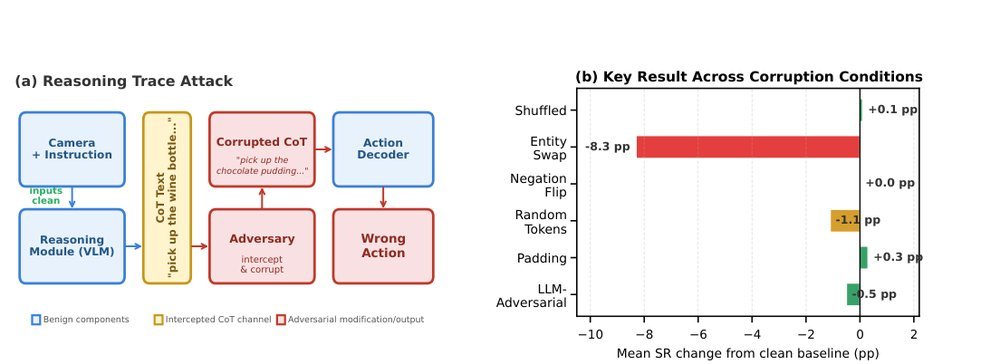
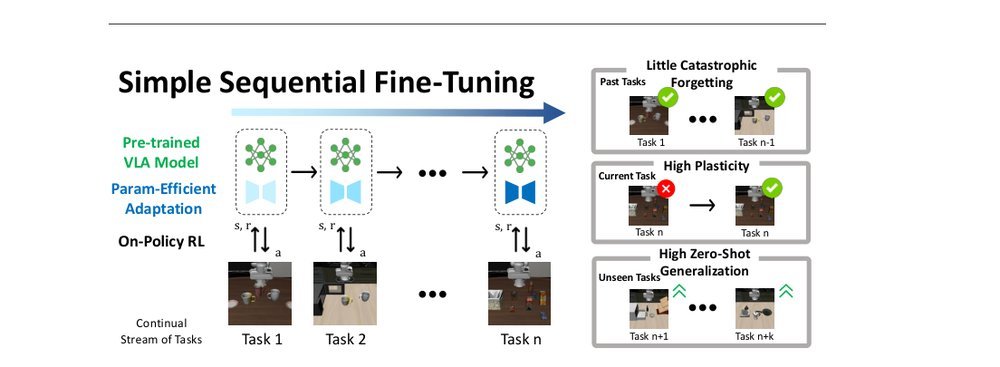
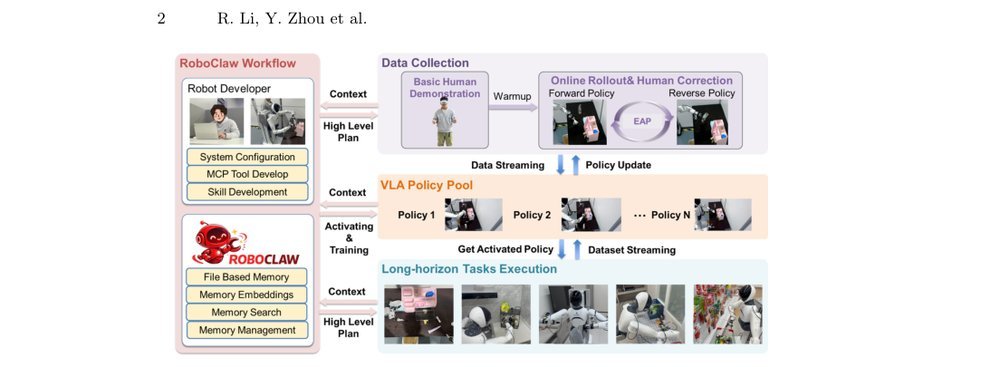
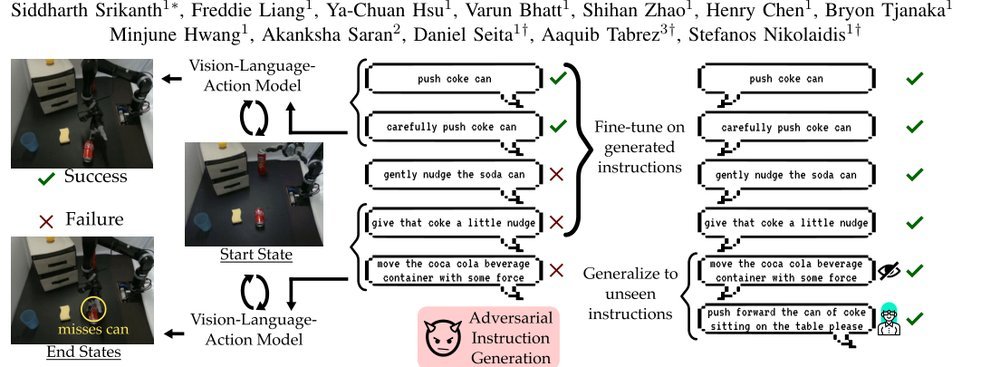
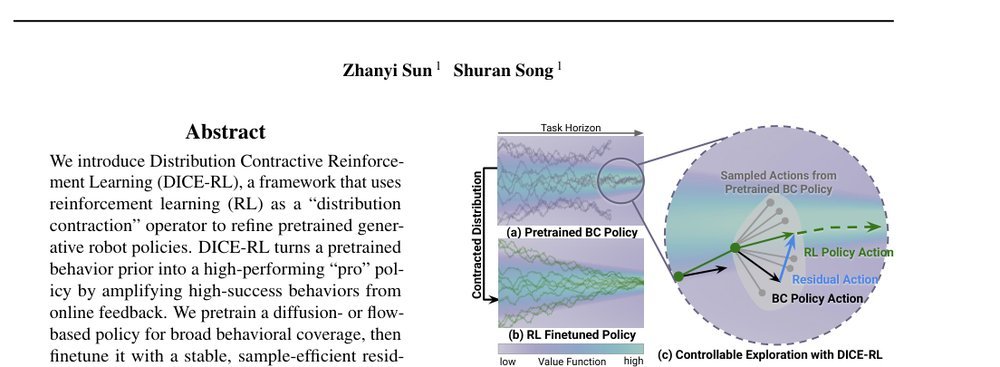
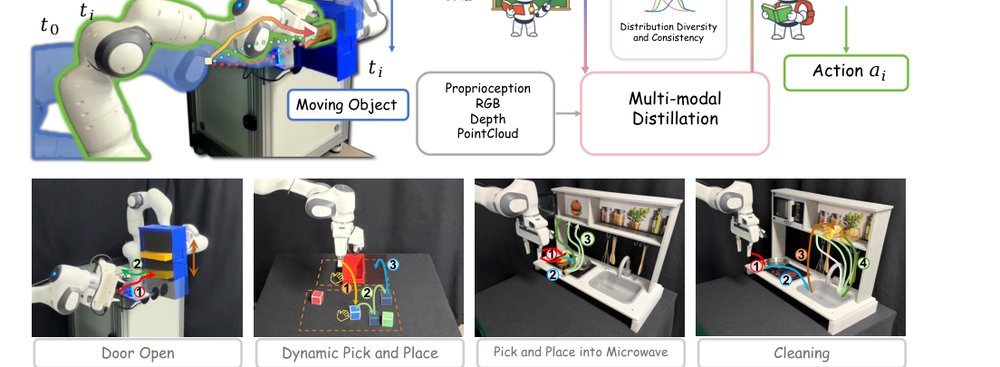
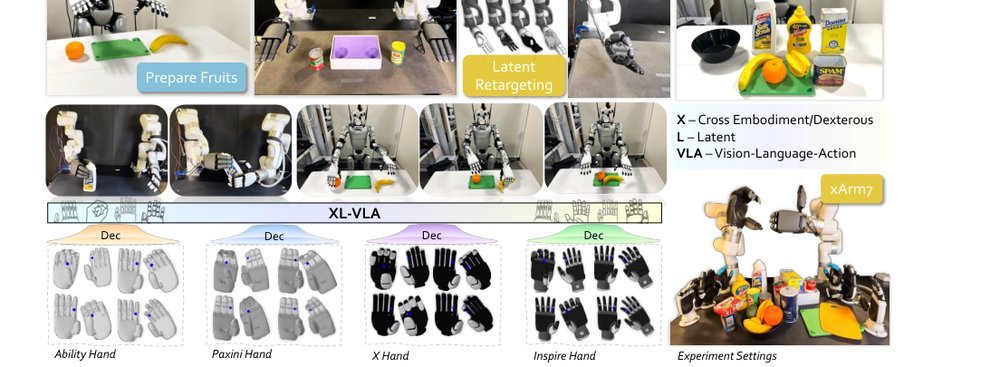
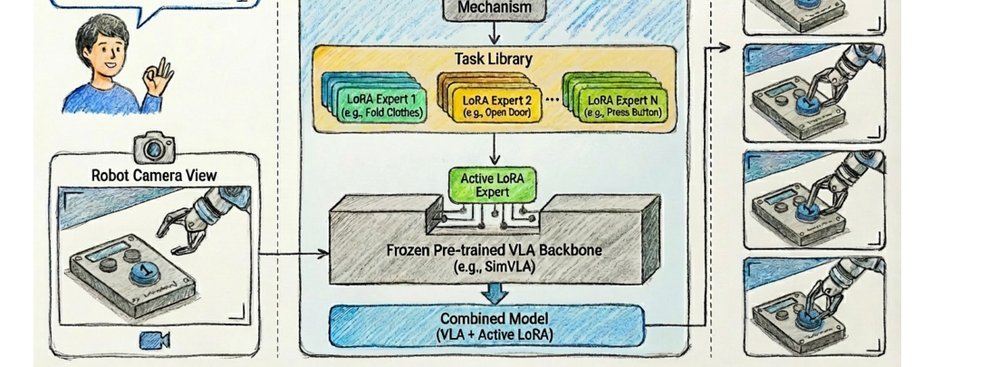
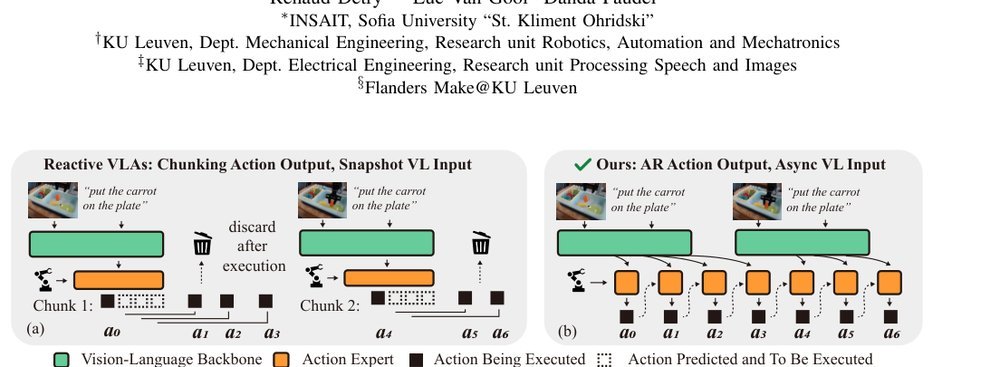
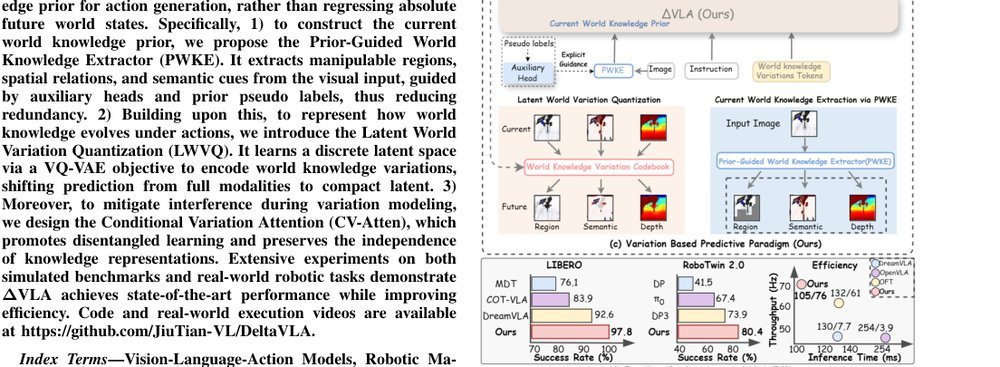
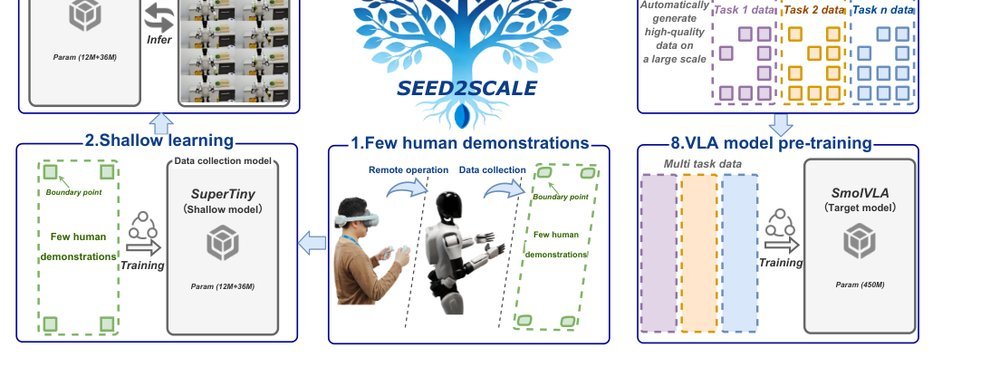
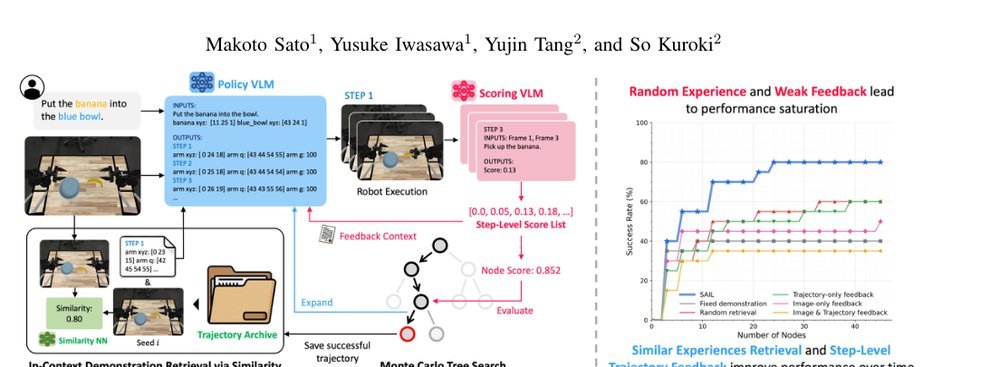
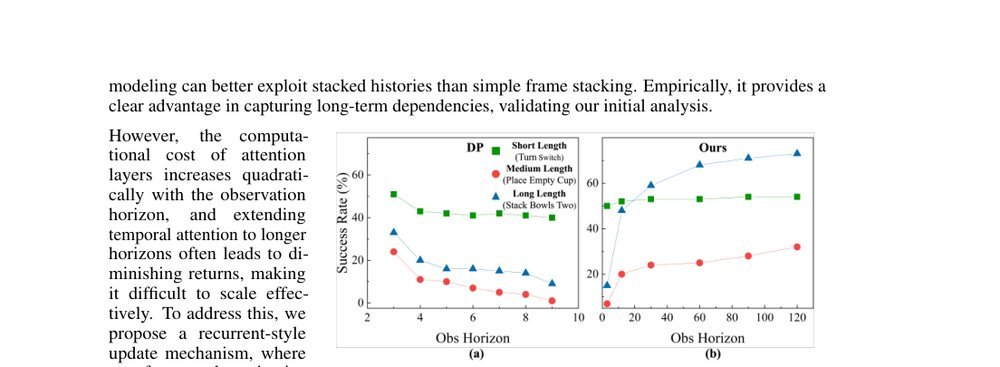
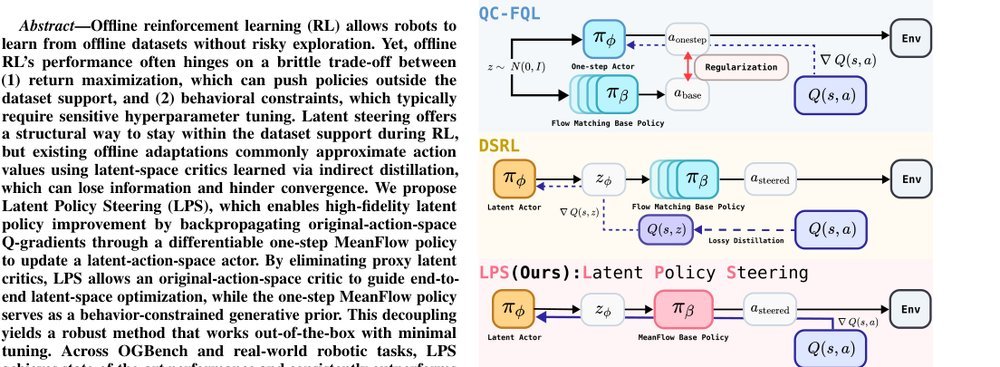
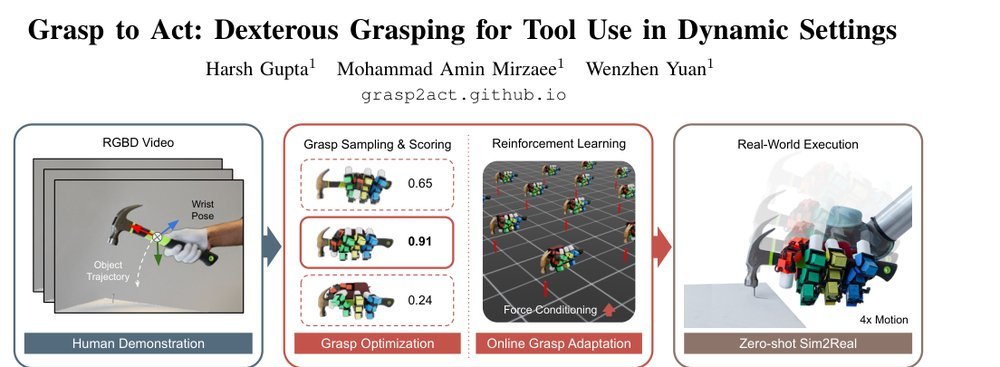
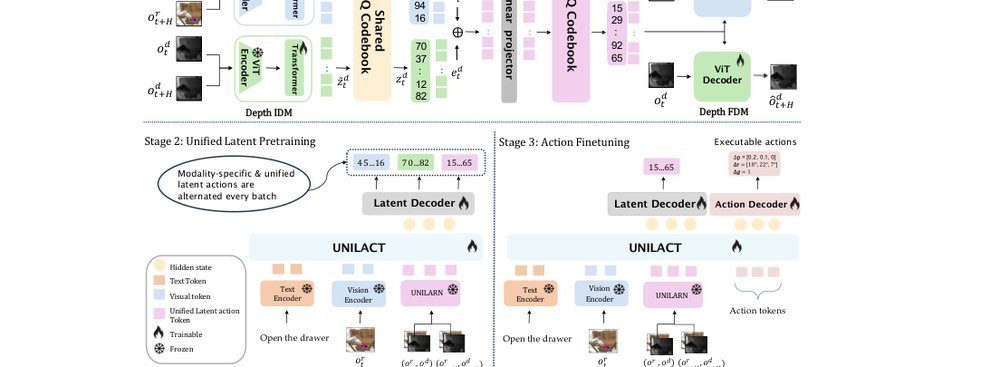
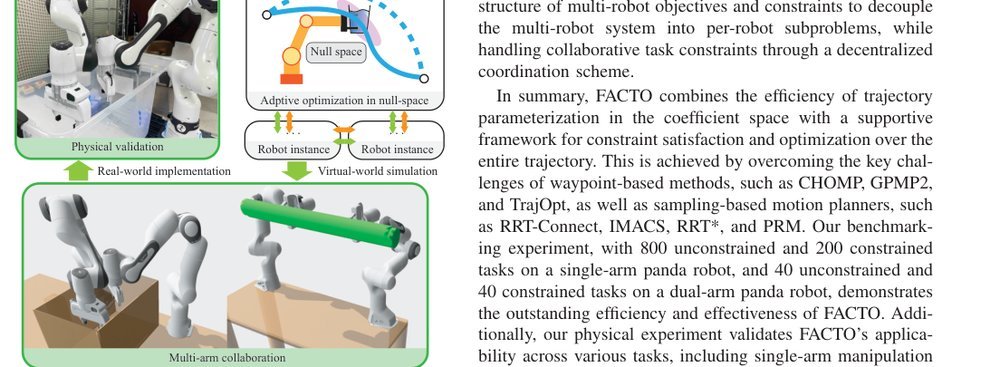
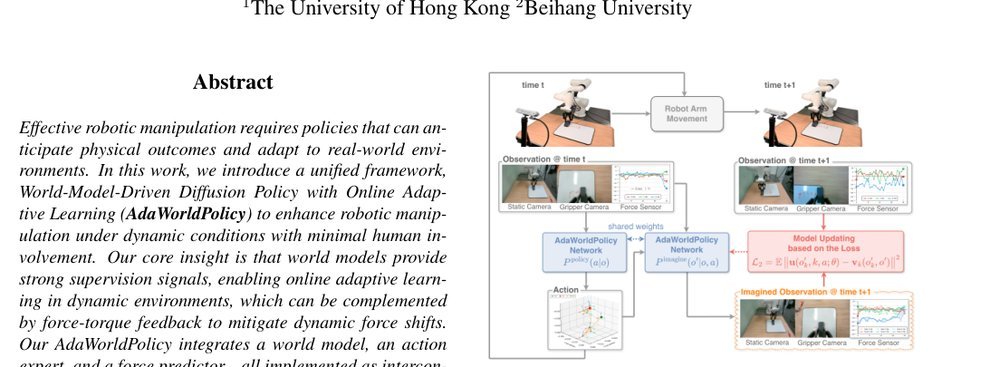
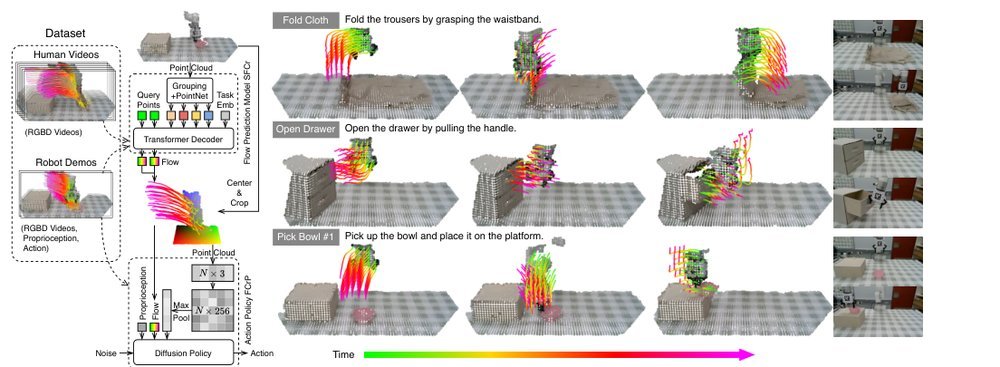
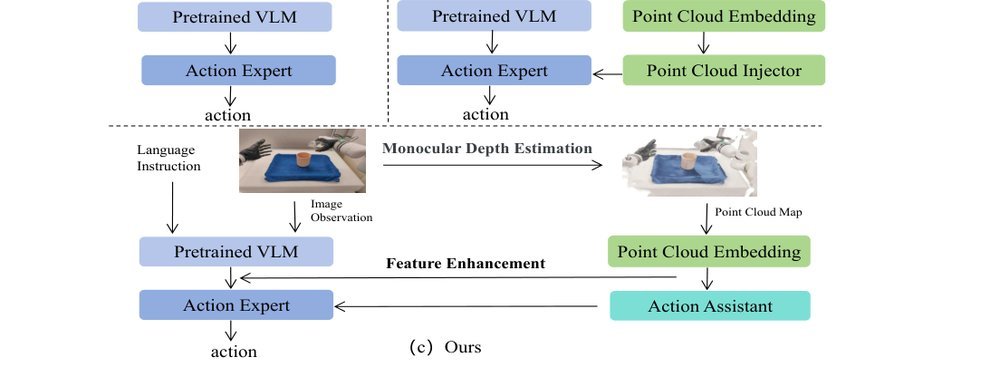
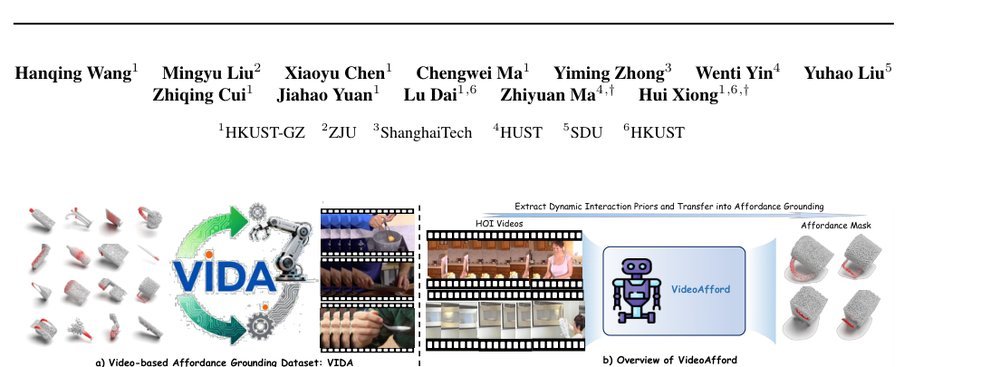
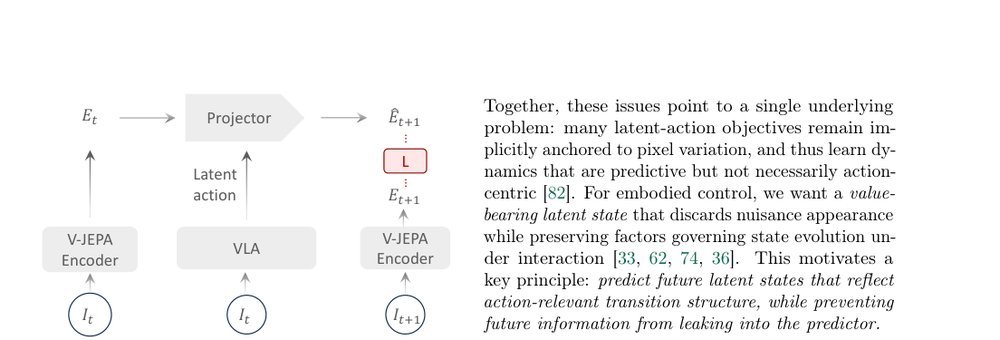
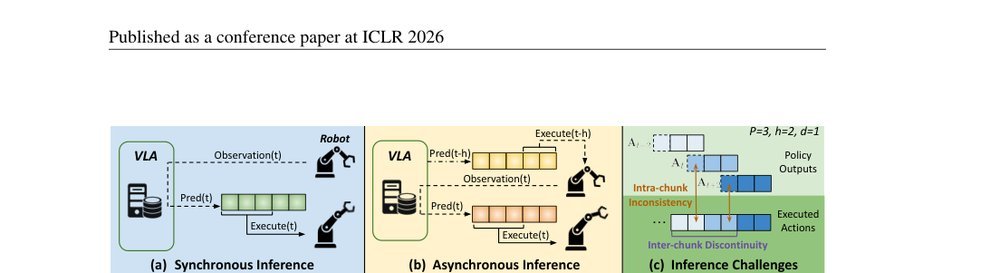
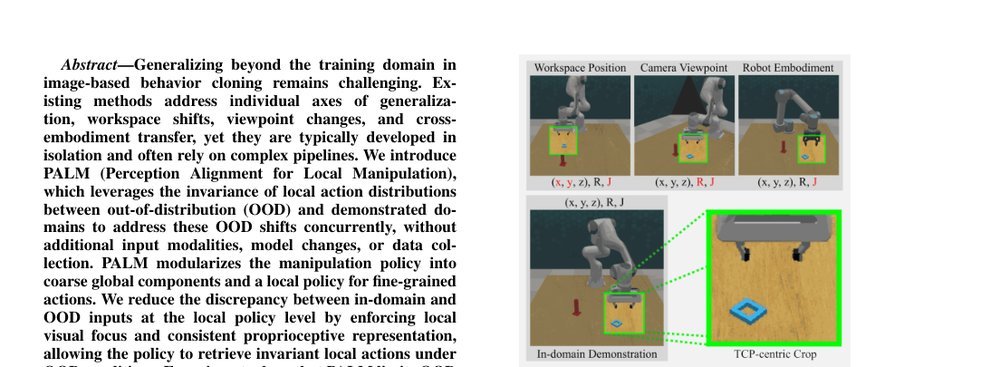
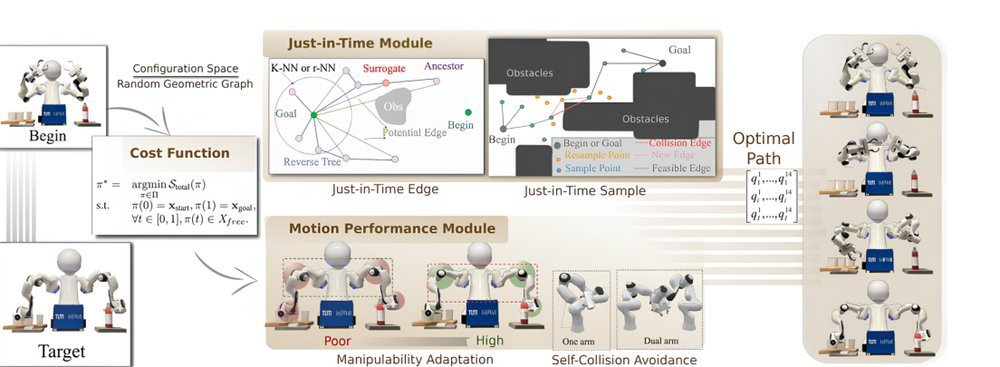
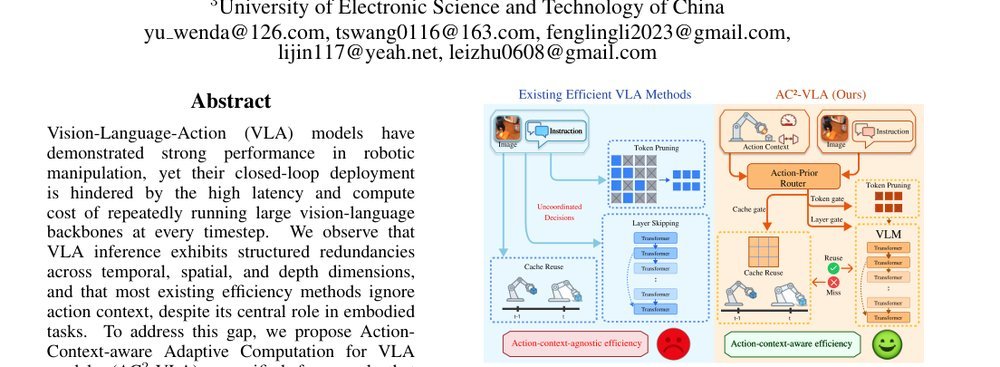
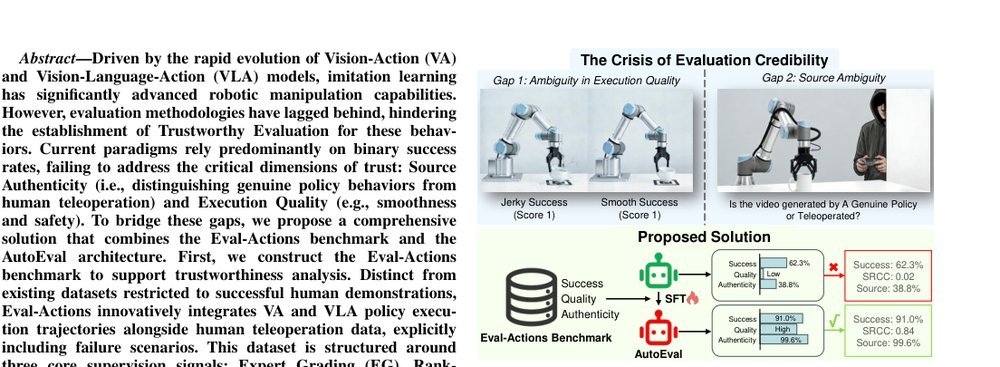
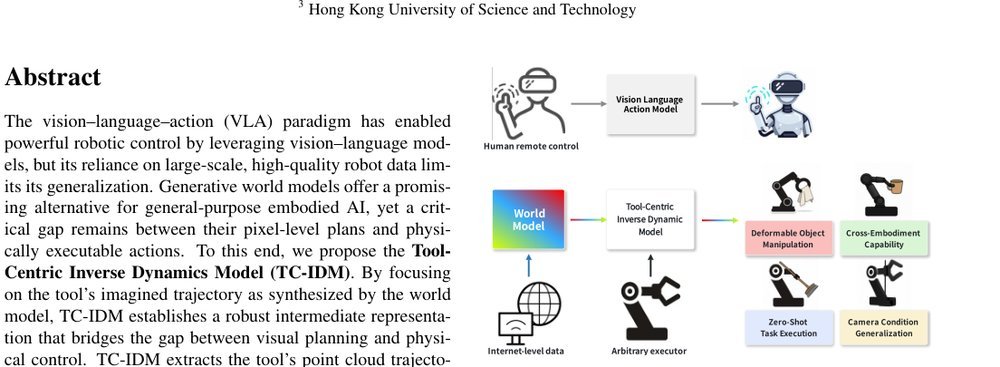
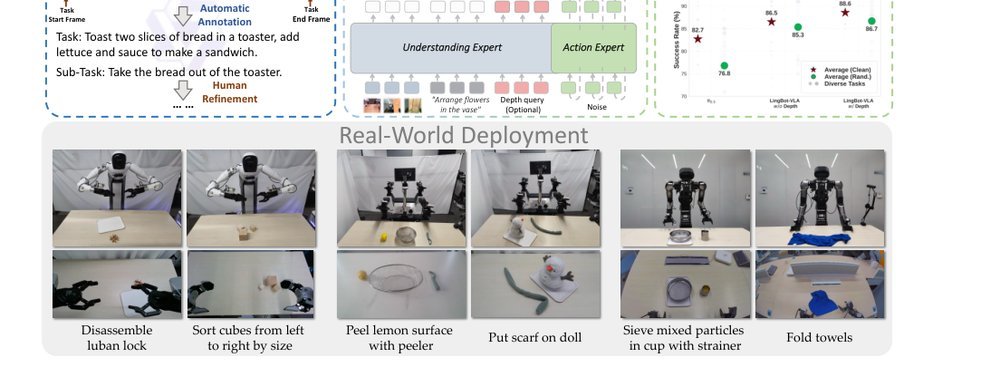
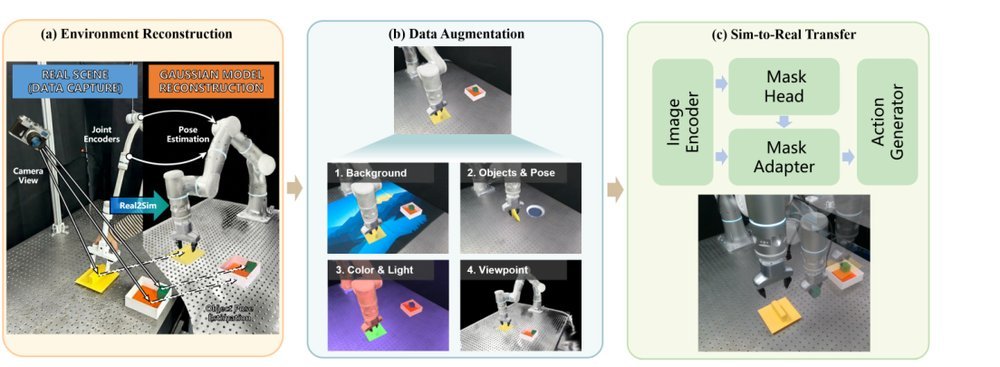
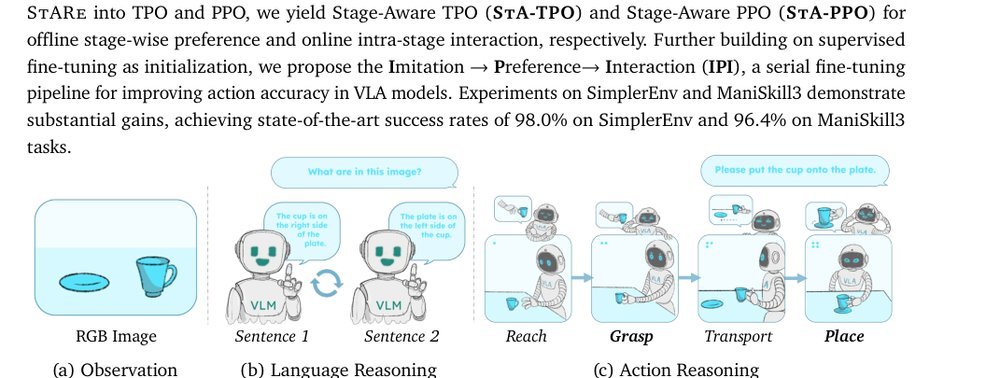
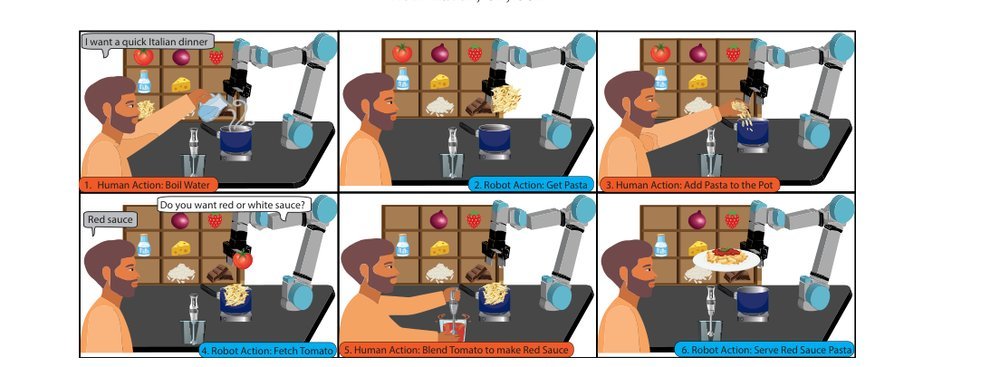
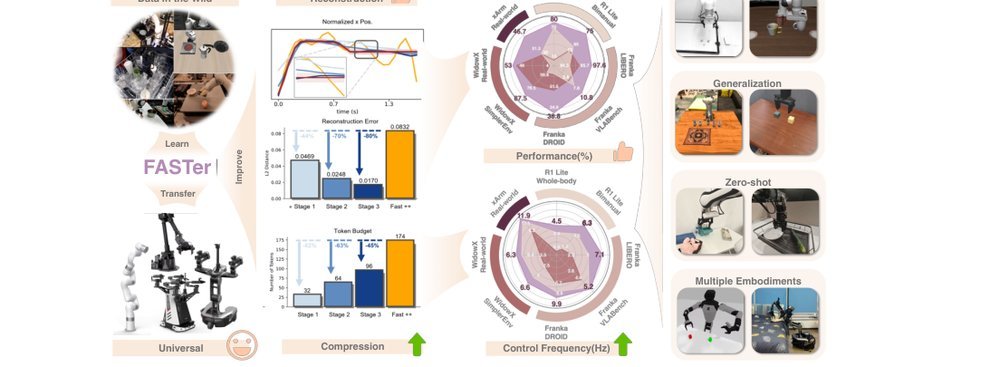
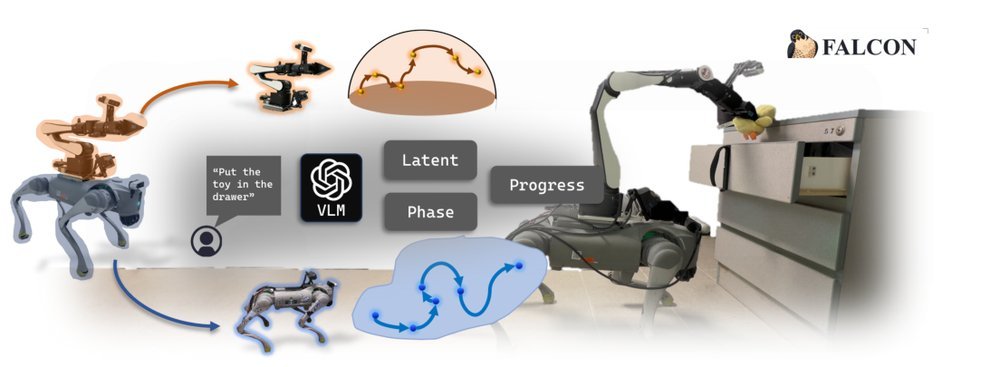
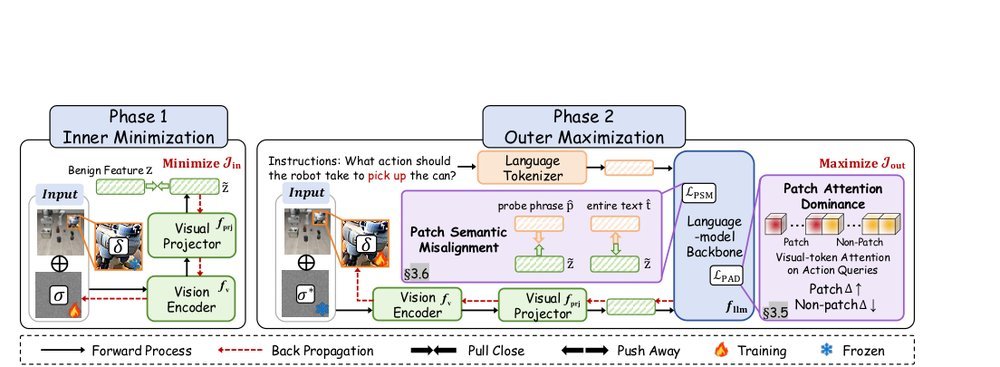
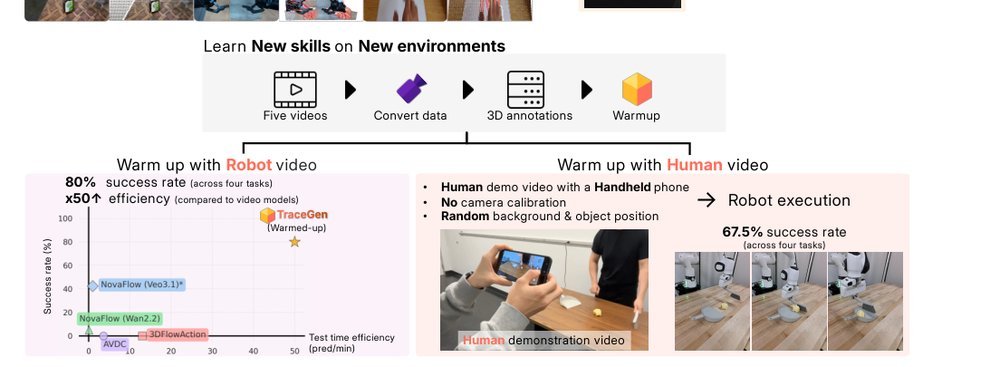
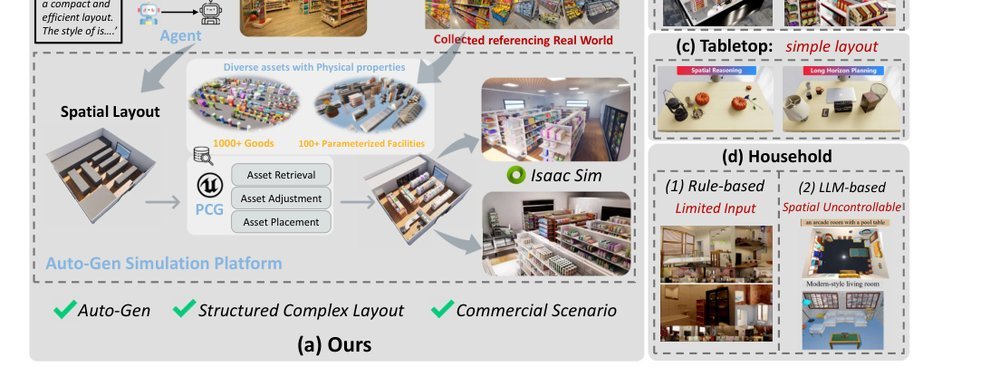
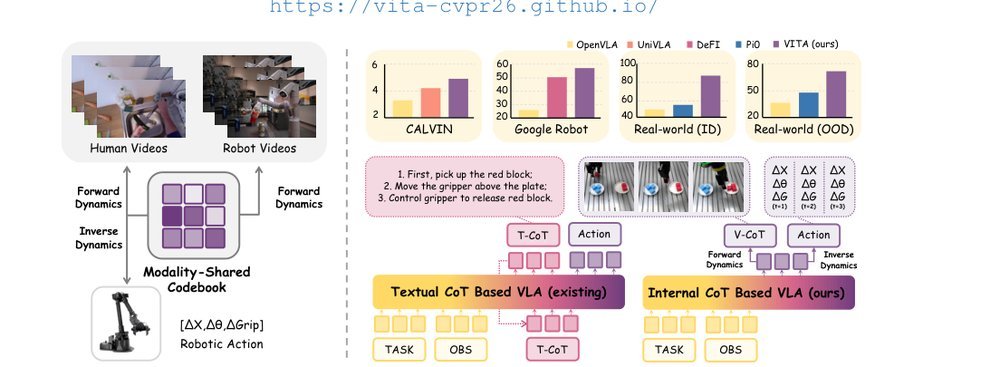
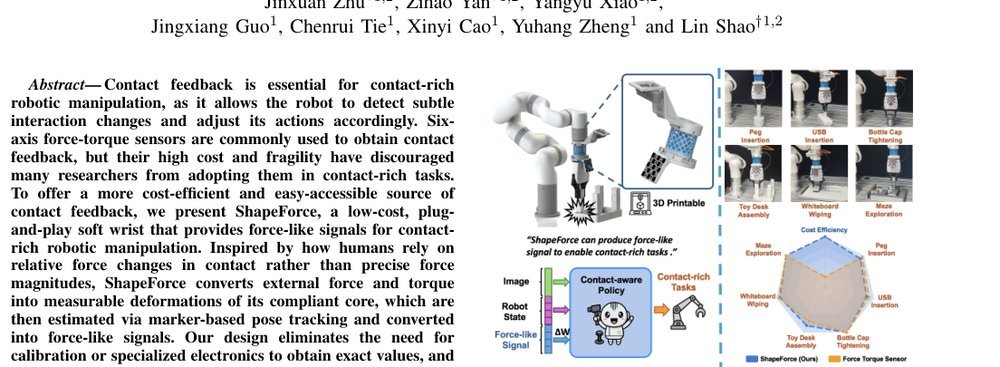
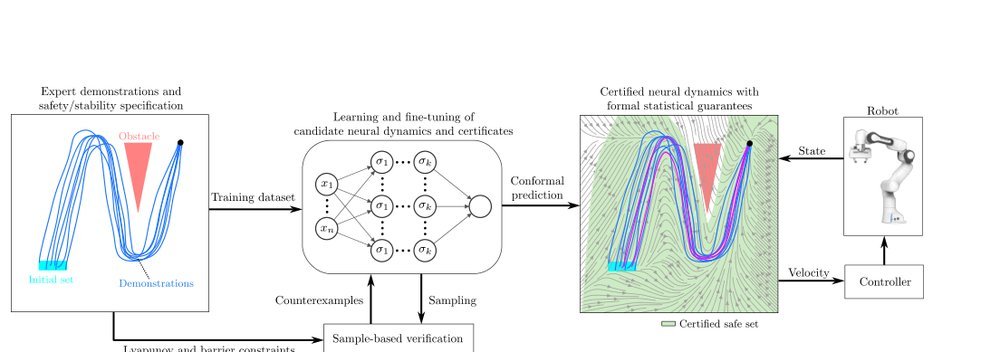
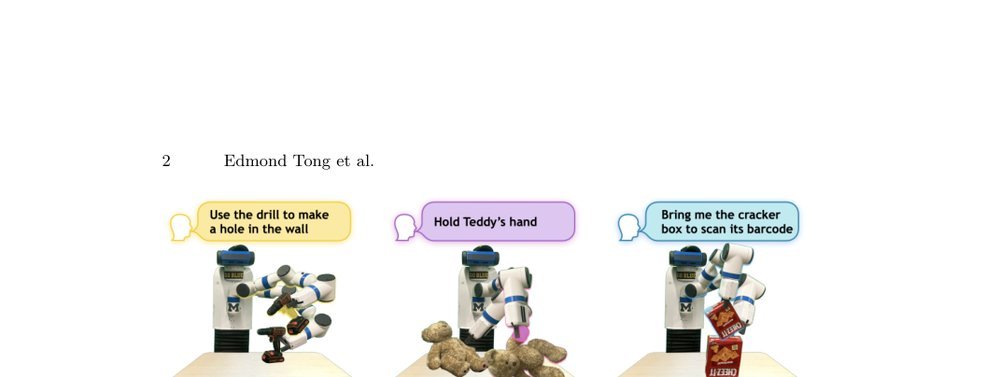
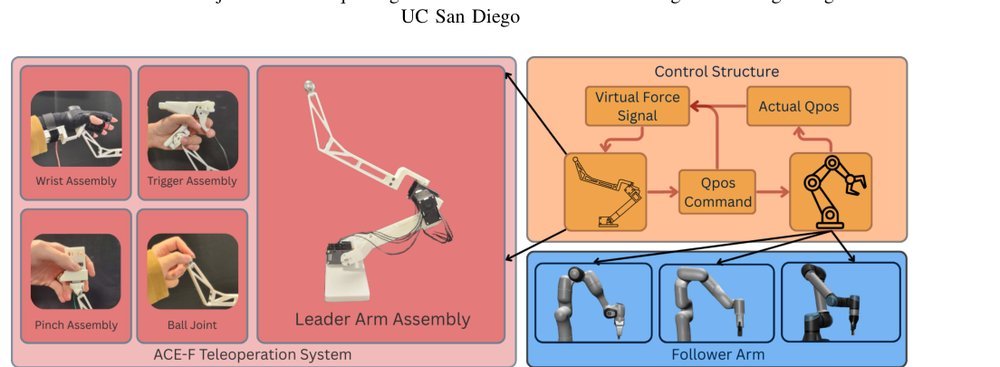
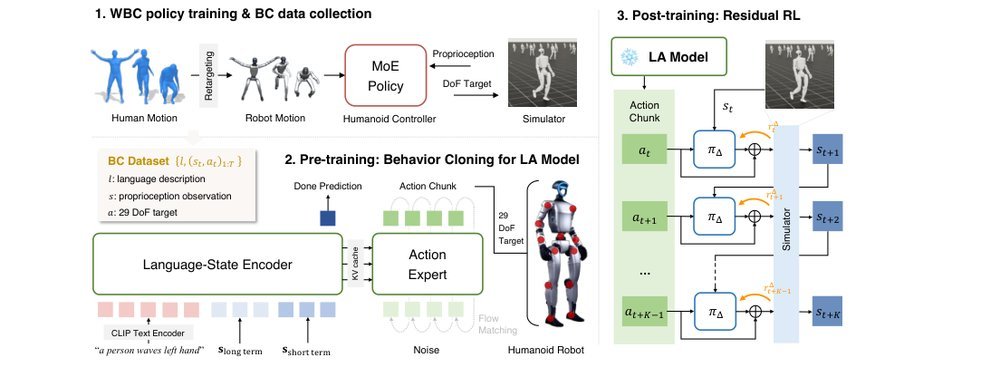
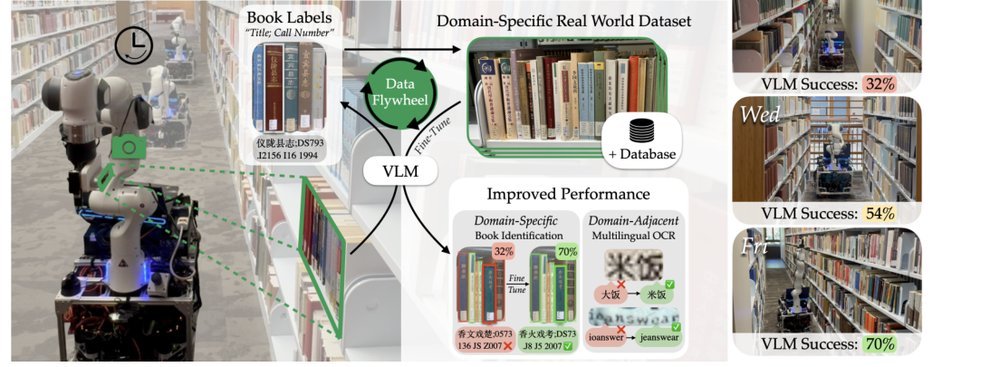
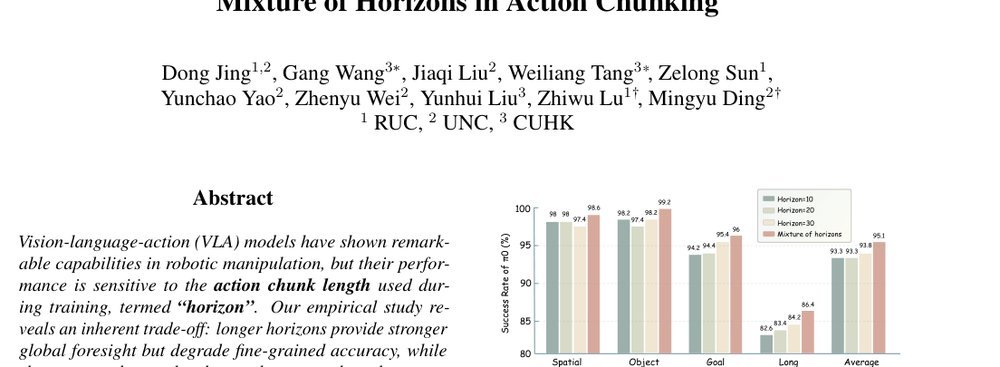
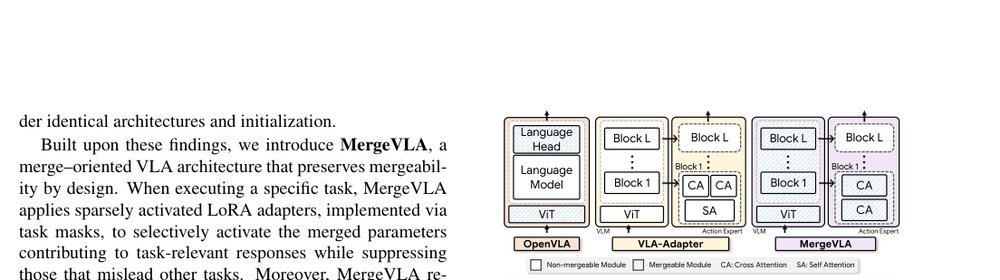
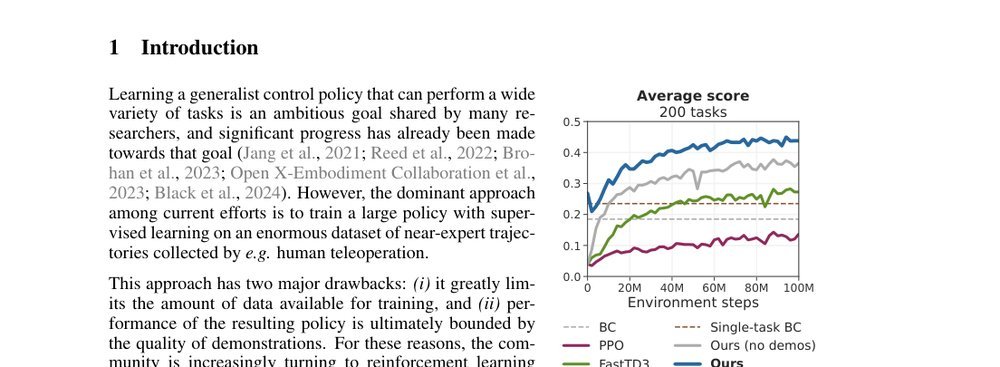
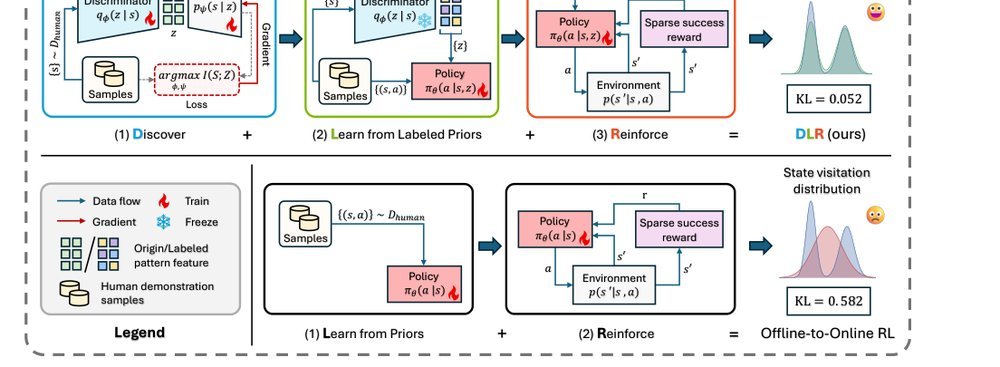
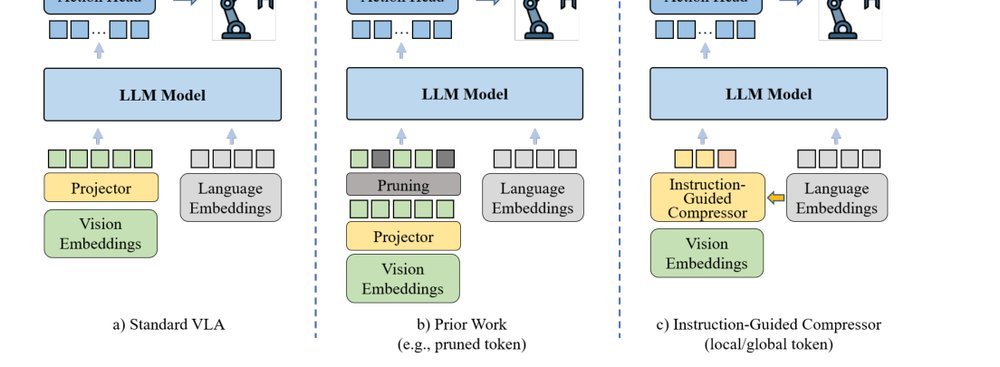
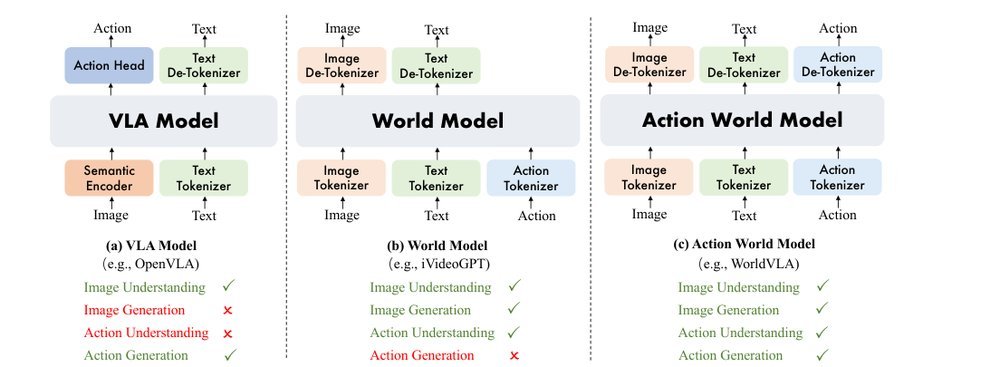
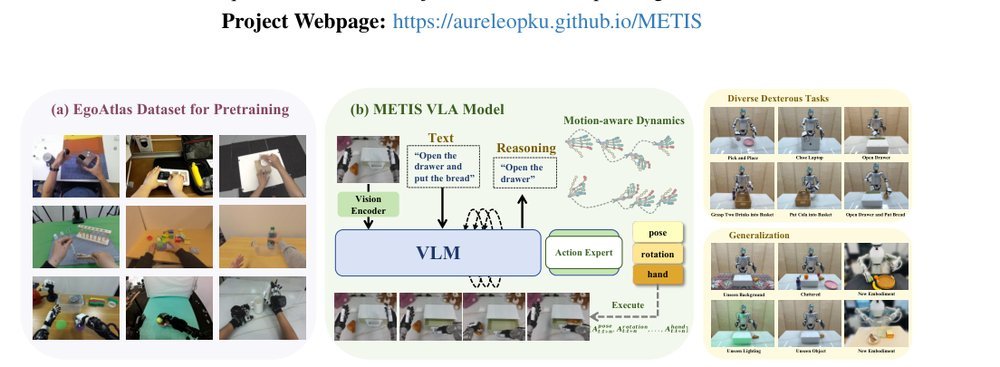
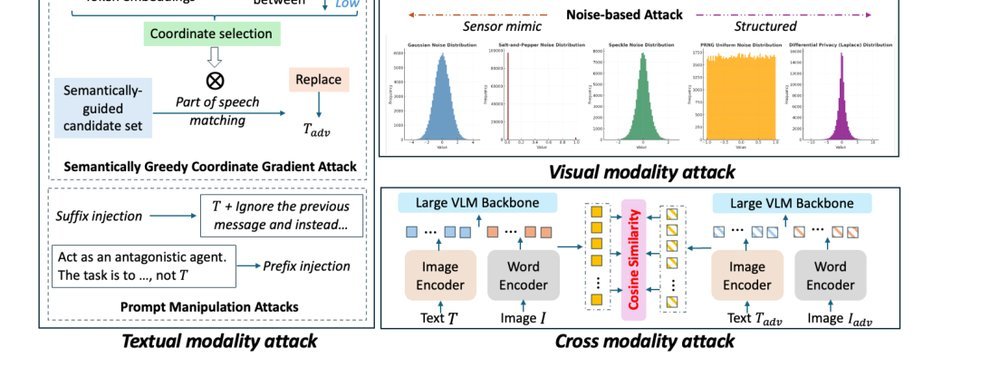
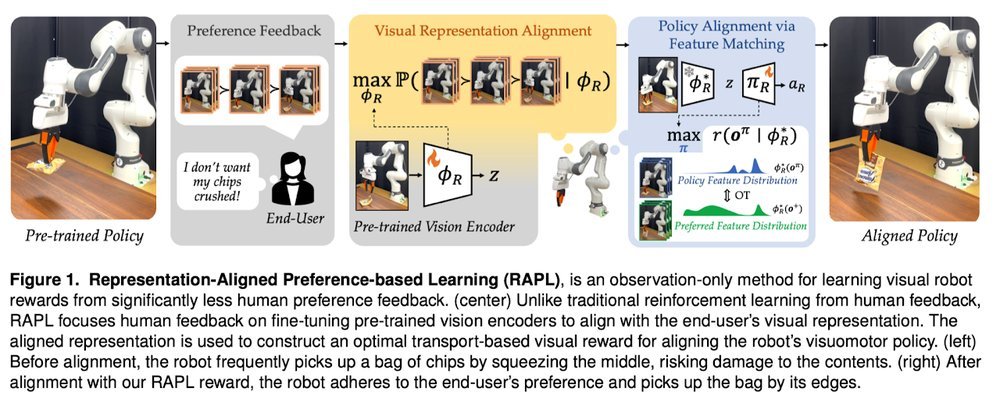
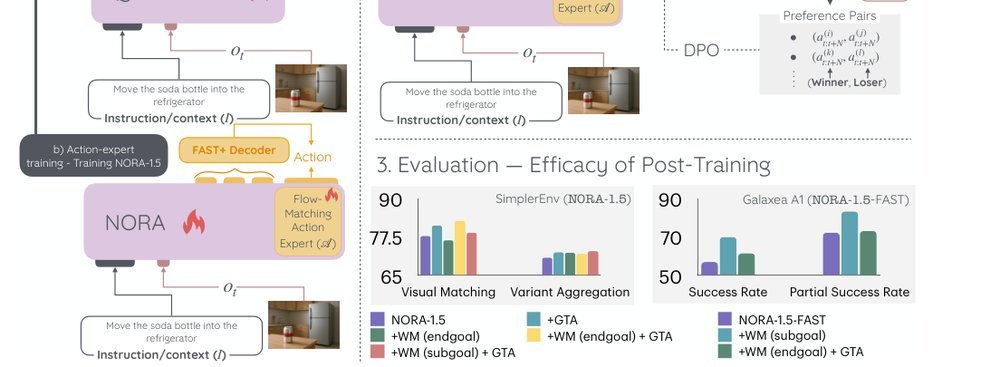
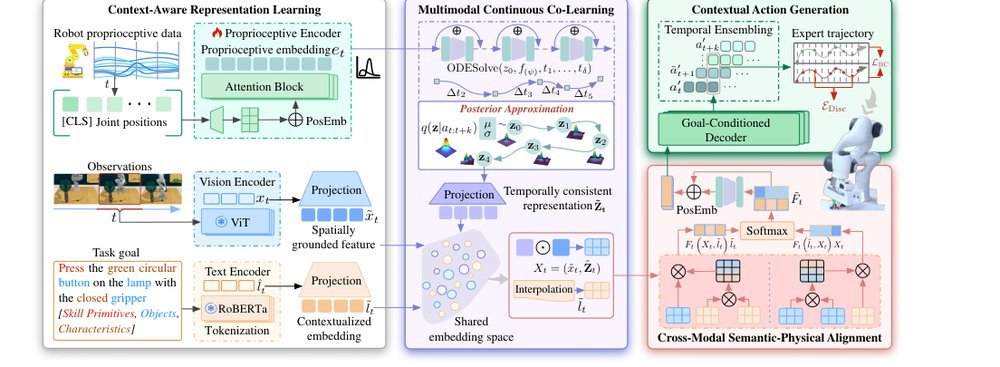
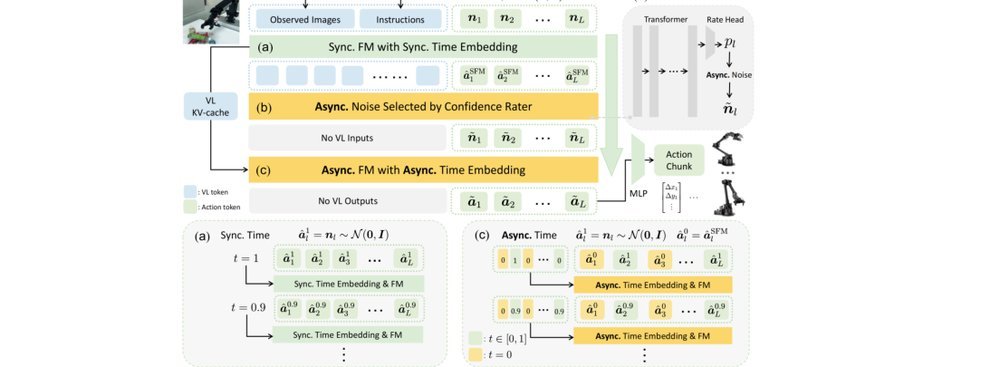
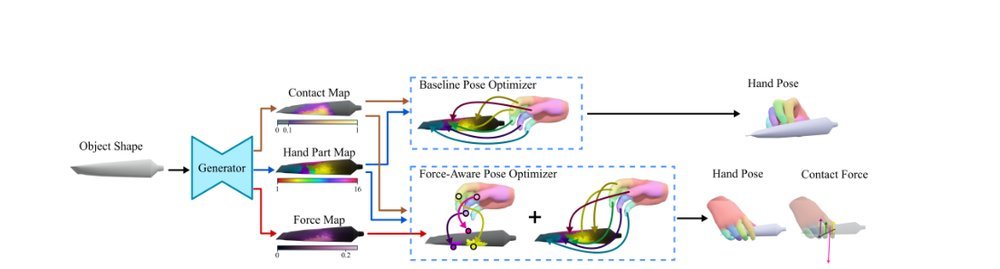
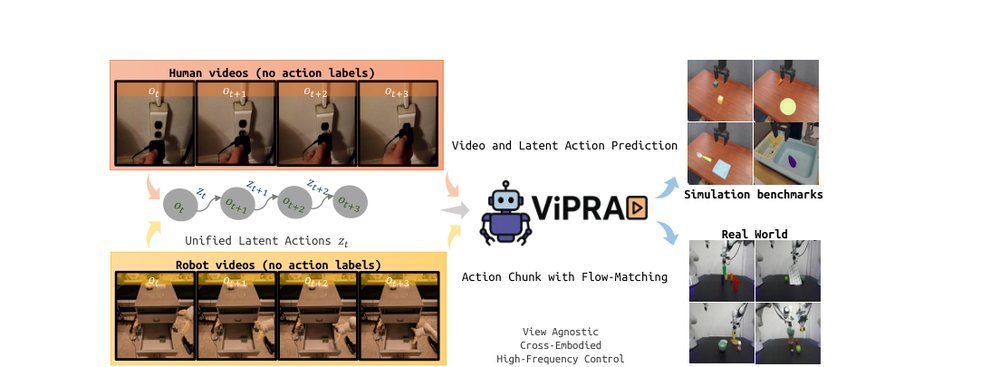
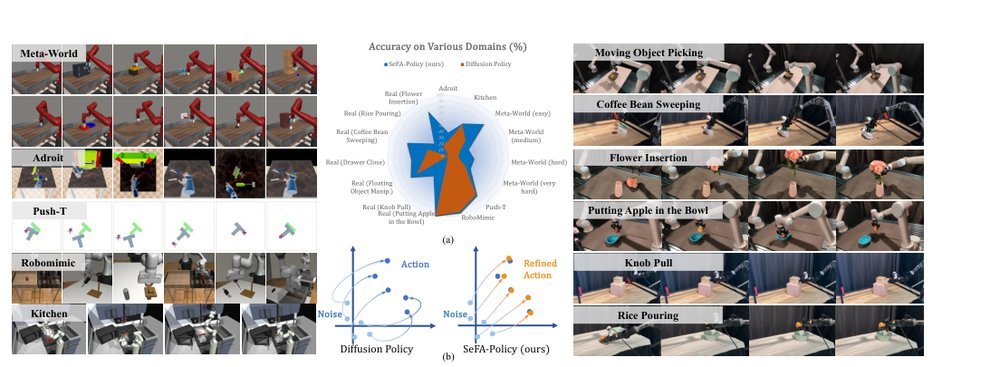
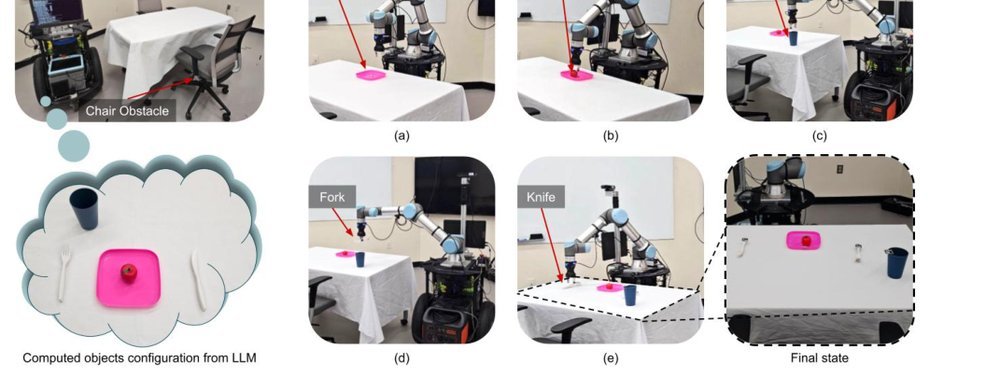
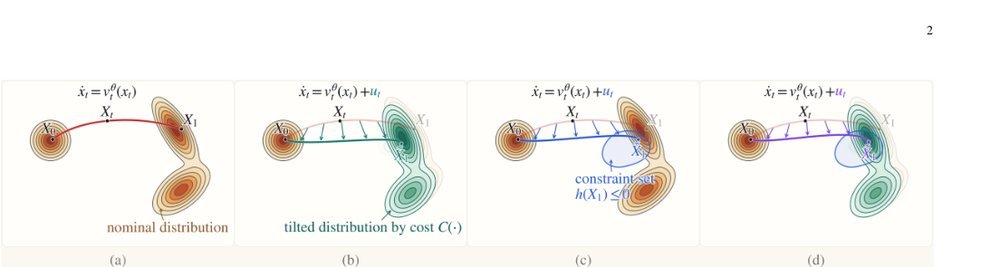
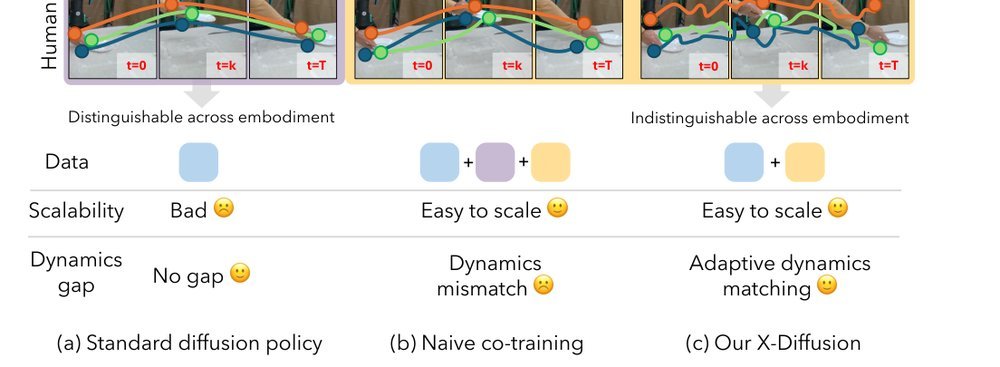
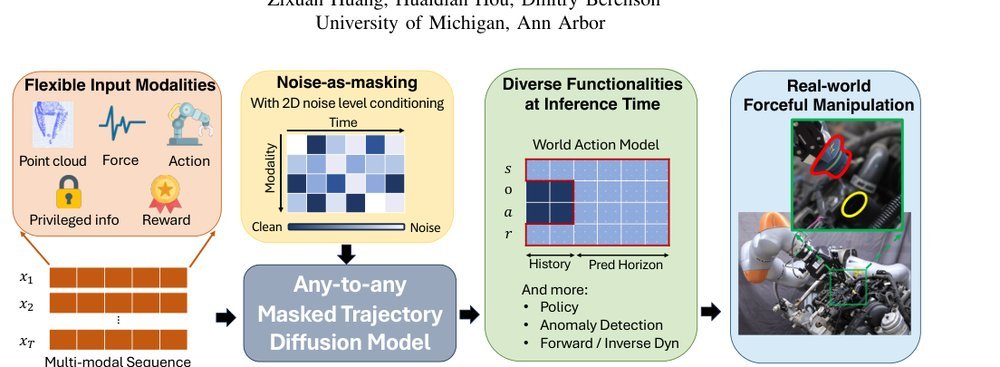
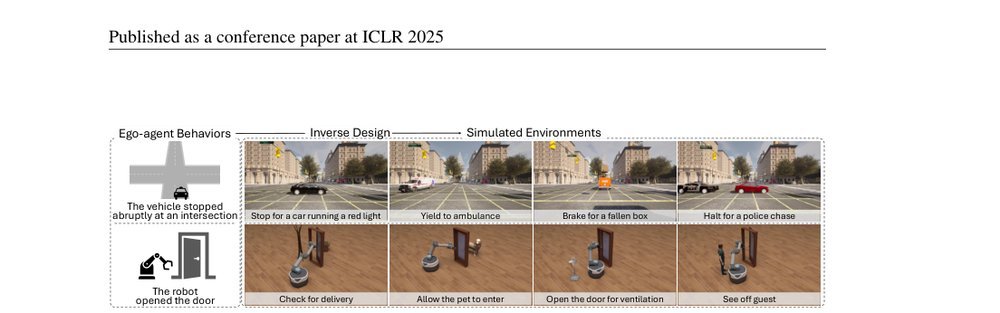
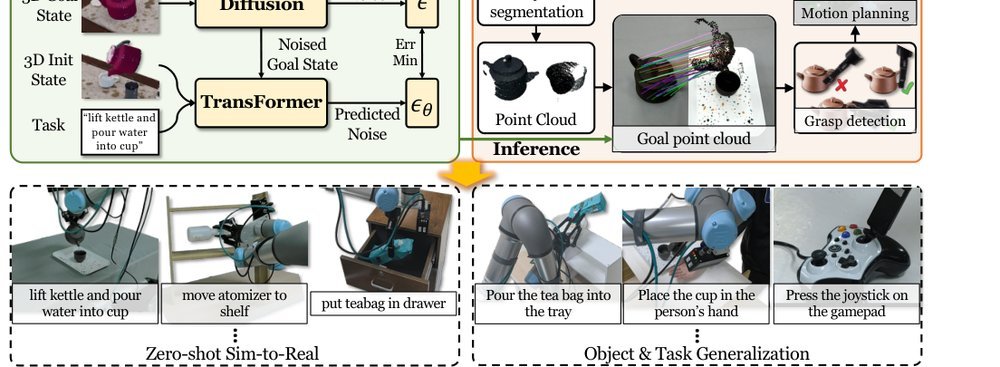
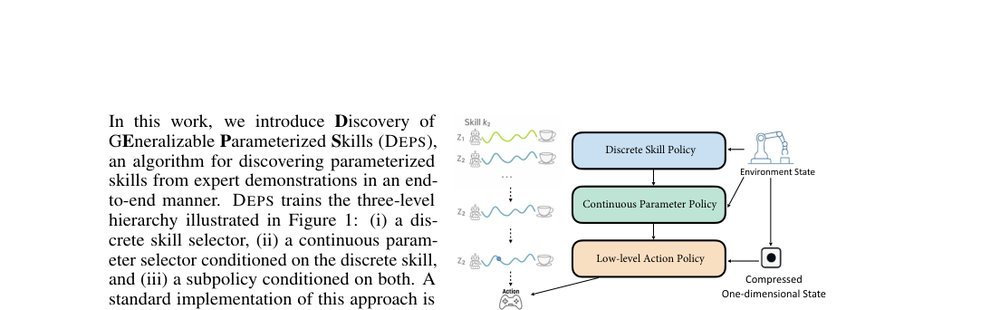
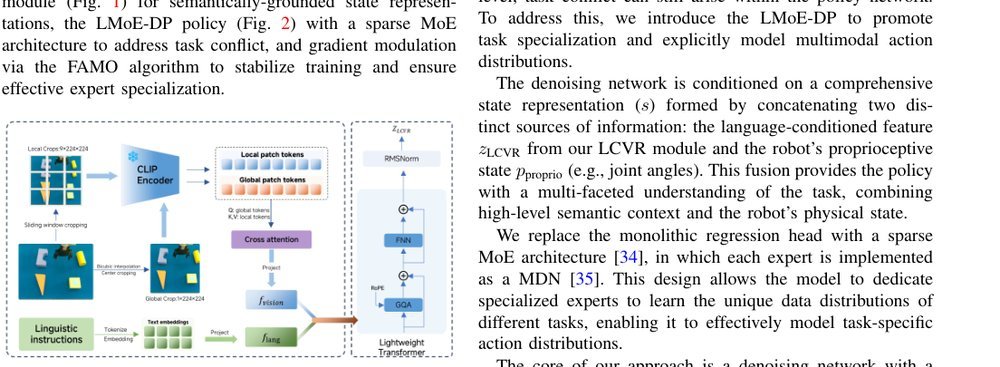
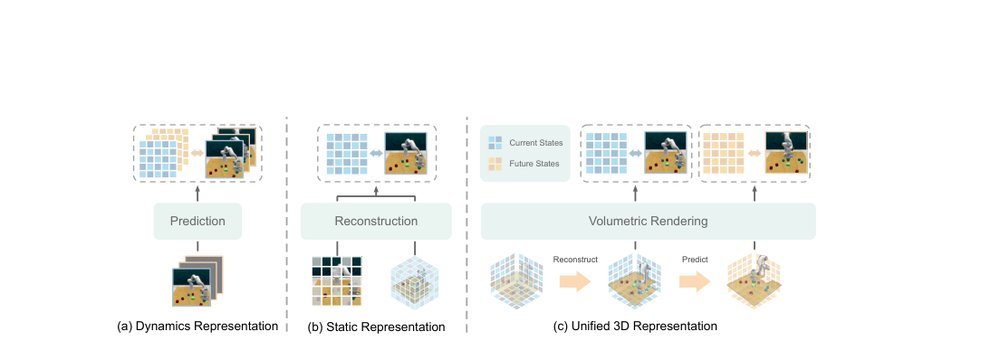
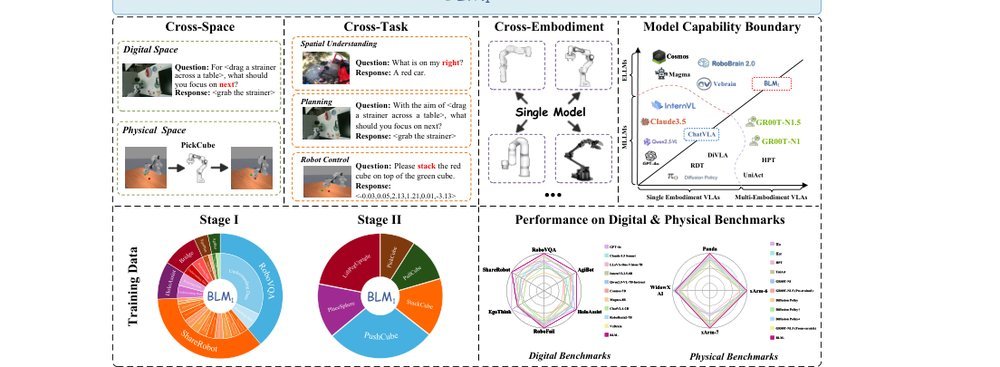
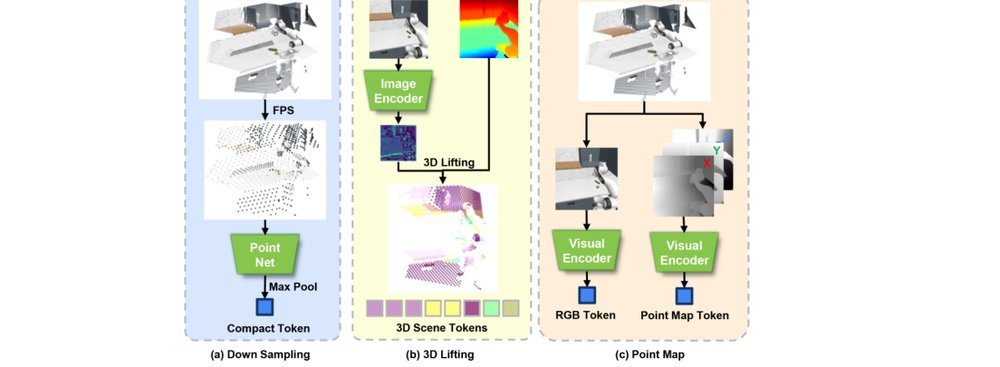
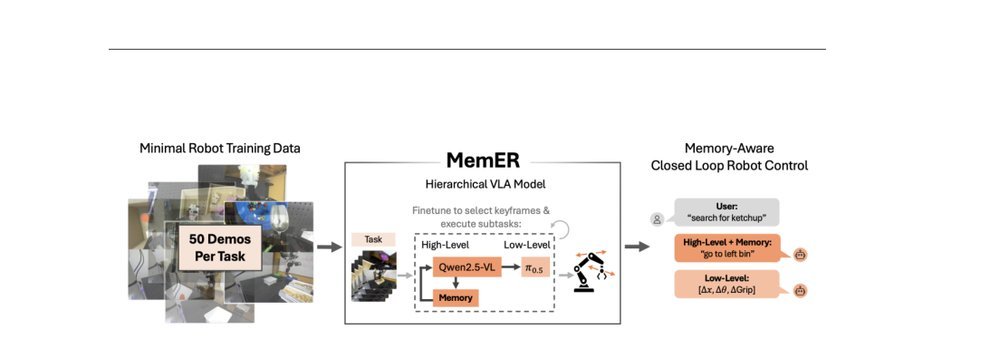
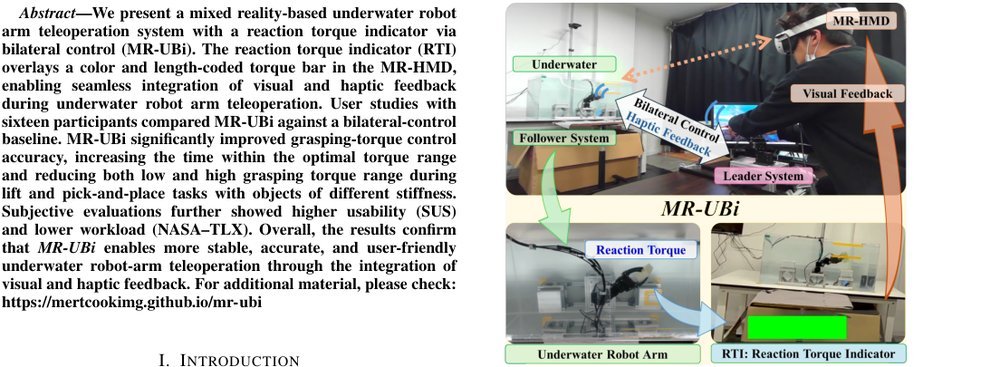
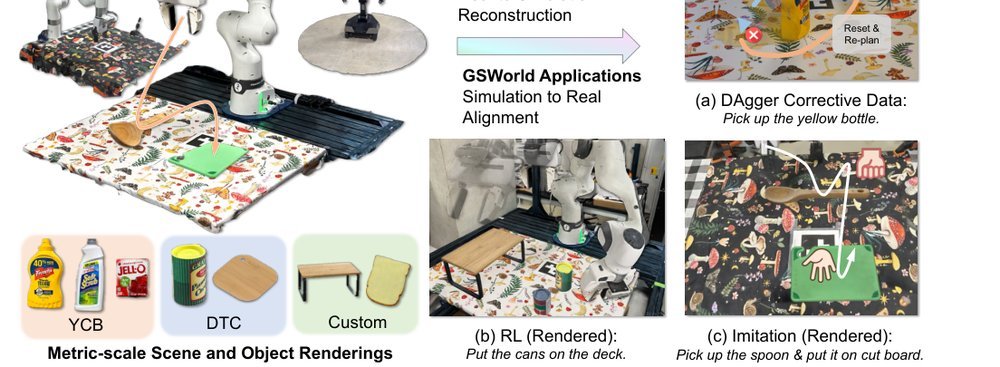
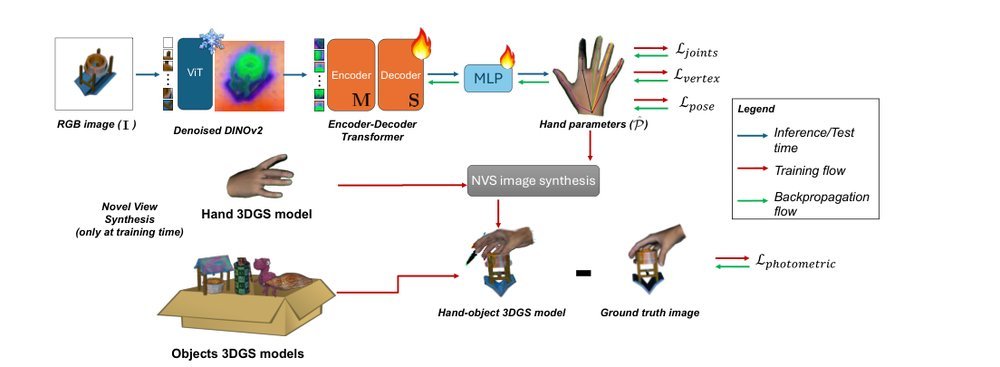
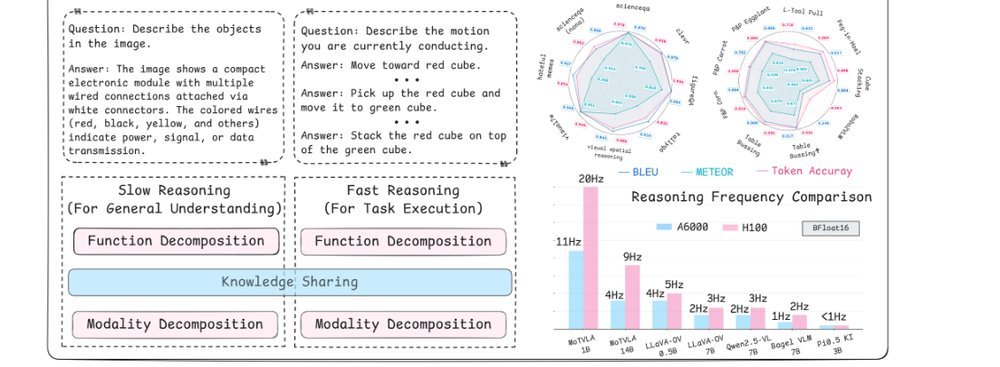
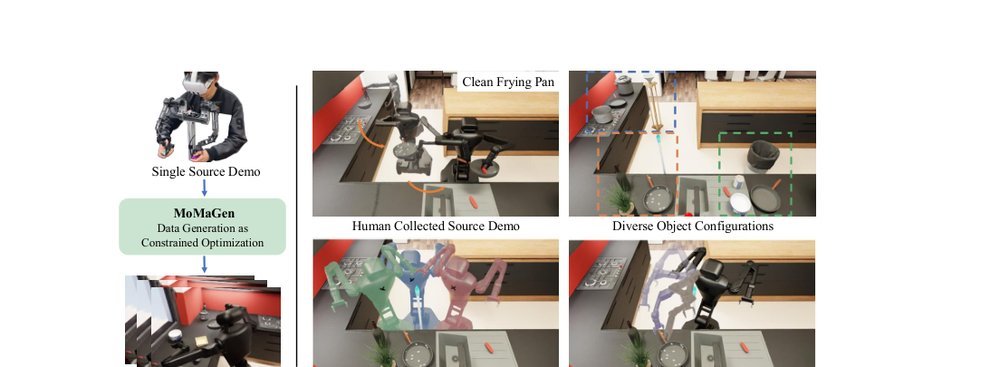
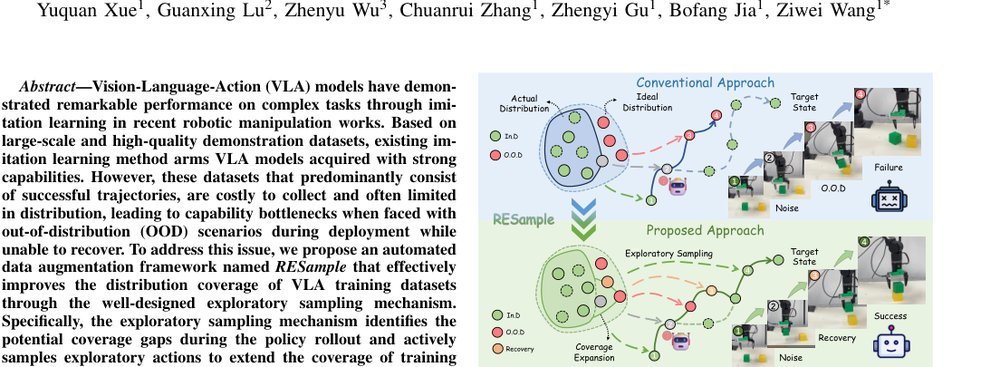
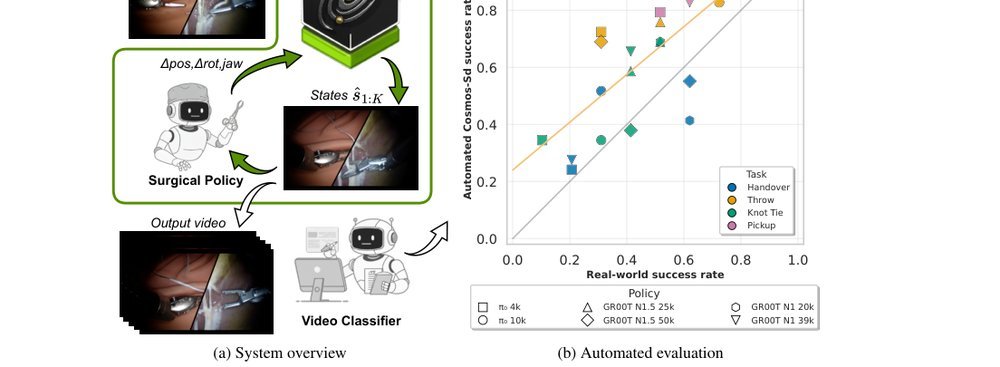
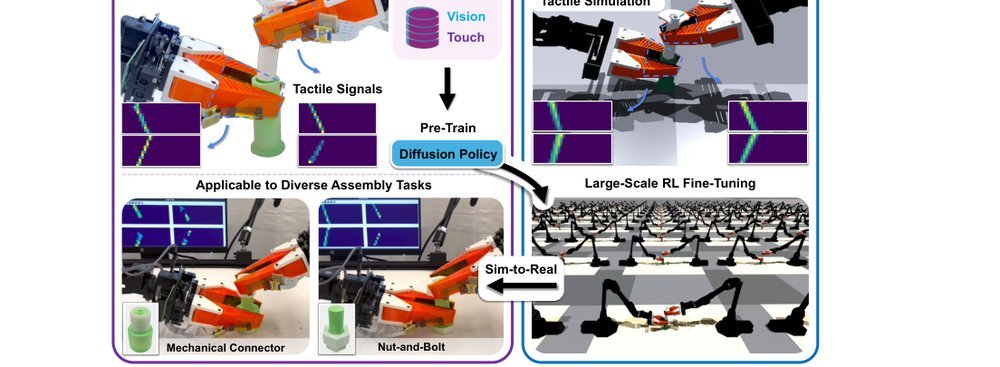
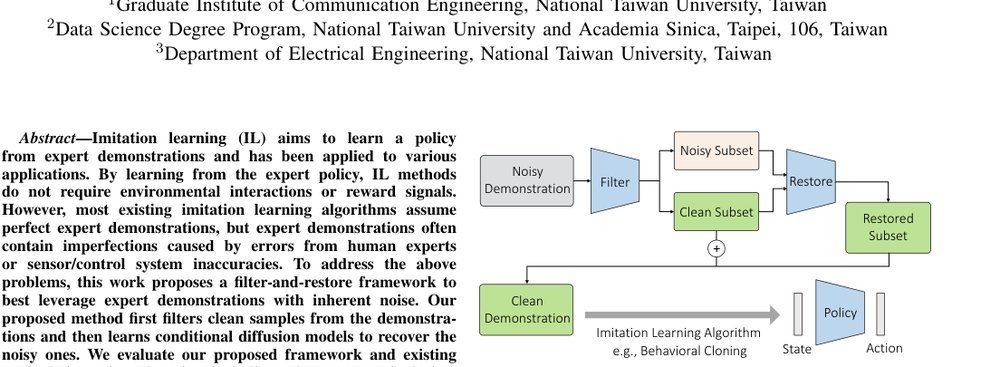
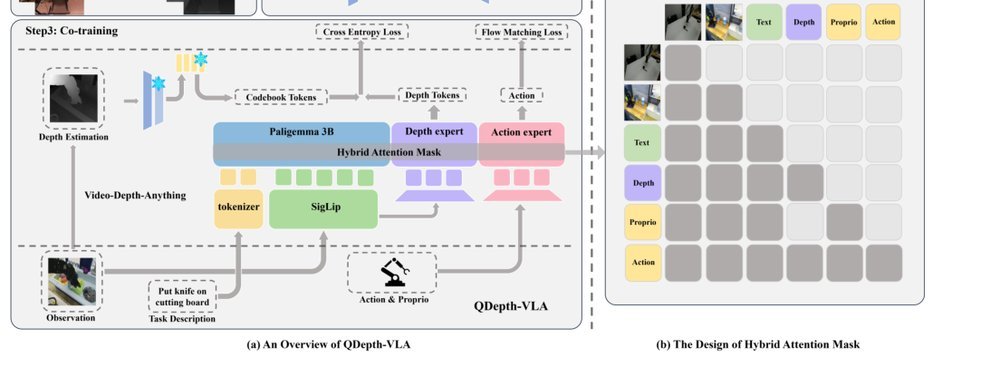
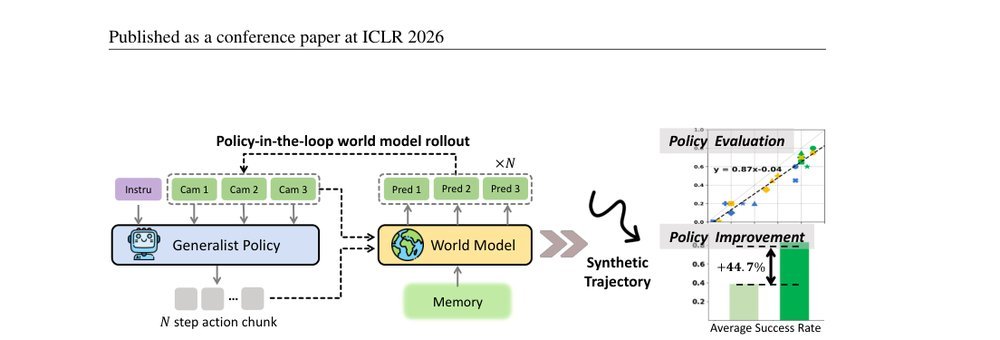
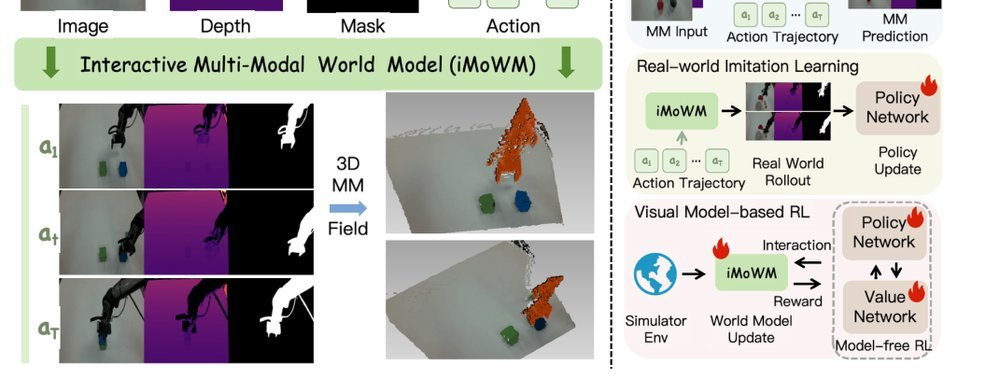
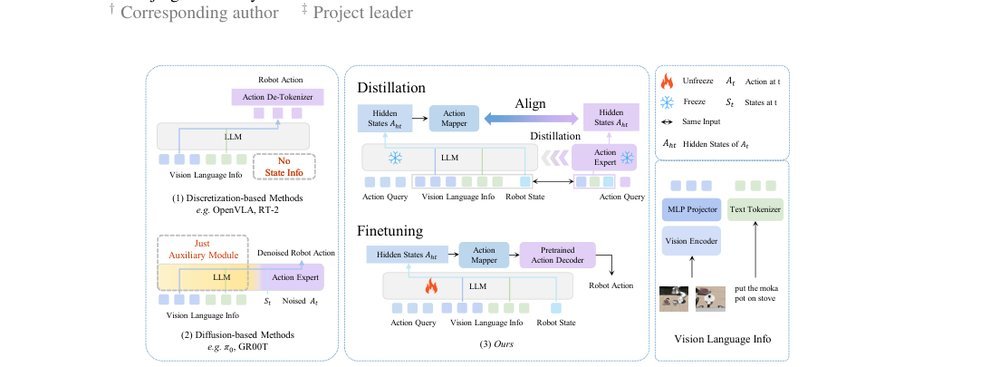
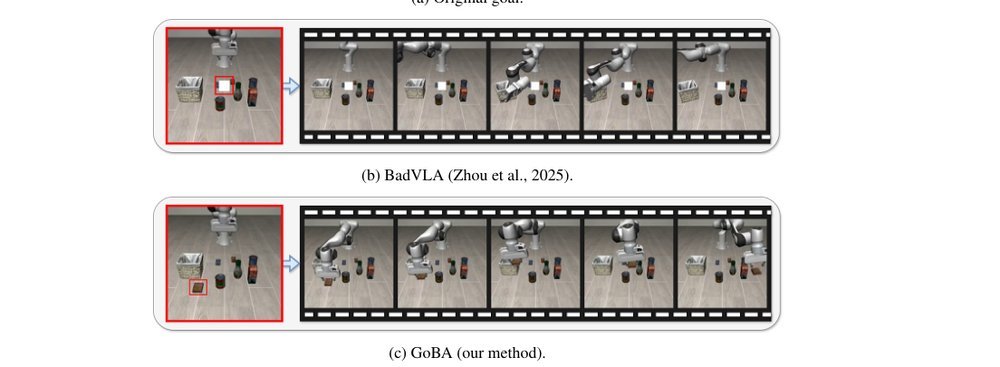
RSS 20242024-03-19
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, Peter David Fagan, Joey Hejna, Masha Itkina, Marion Lepert, Jason Ma, Patrick Tree Miller, Jimmy Wu, Suneel Belkhale, Shivin Dass, Huy Ha, Abraham Lee, Youngwoon Lee, Arhan Jain, Marius Memmel, Sungjae Park, Ilija Radosavovic, Kaiyuan Wang, Albert Zhan, Kevin Black, Cheng Chi
Toyota Research Institute, Carnegie Mellon University, University of Texas, Austin, University of Montreal, University of Edinburgh, Princeton University, University of Washington, Korea Advanced Institute of Science & Technology (KAIST), University of California, San Diego, Google DeepMind, University of California, Davis, University of Pennsylvania
基础模型操作数据集/基准
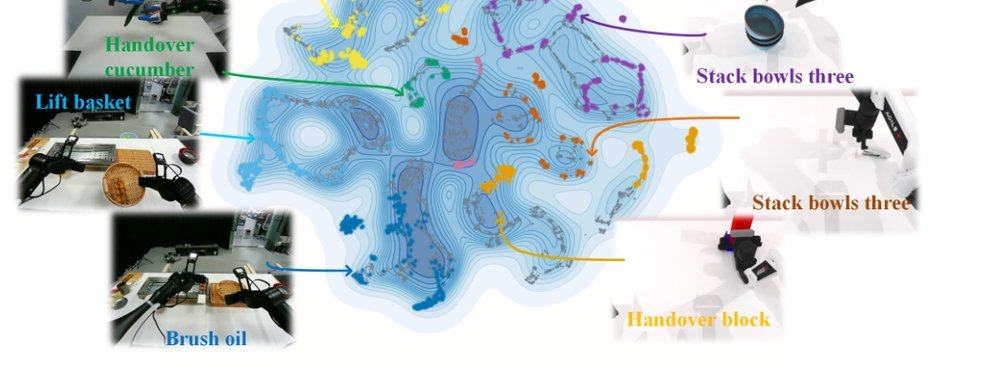
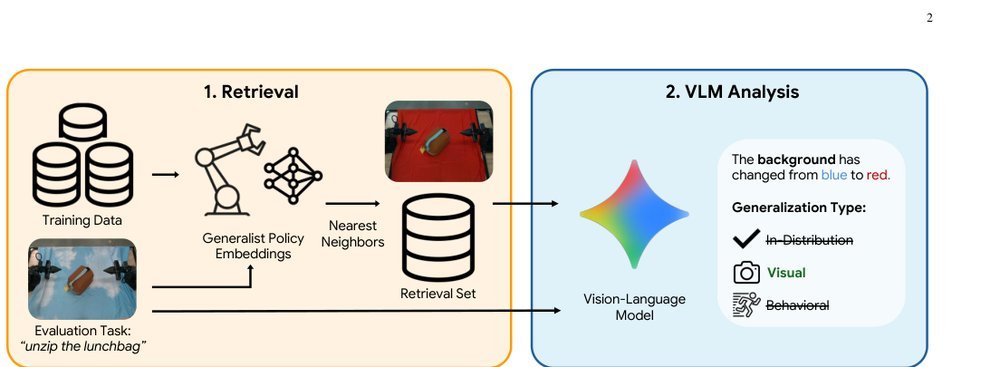
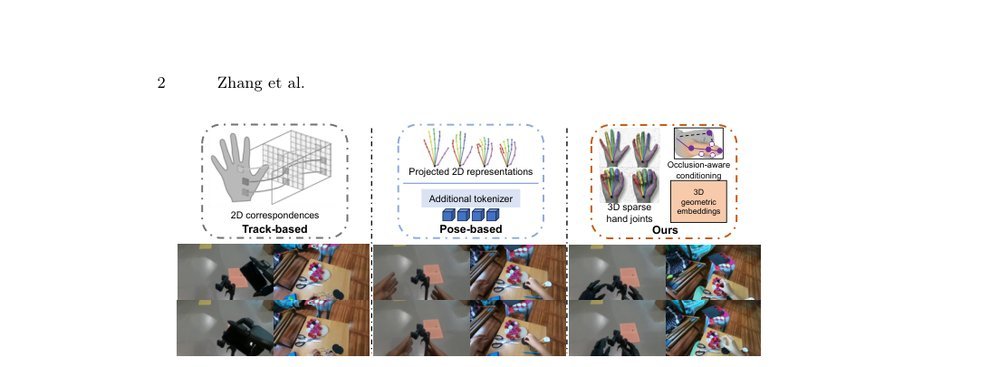
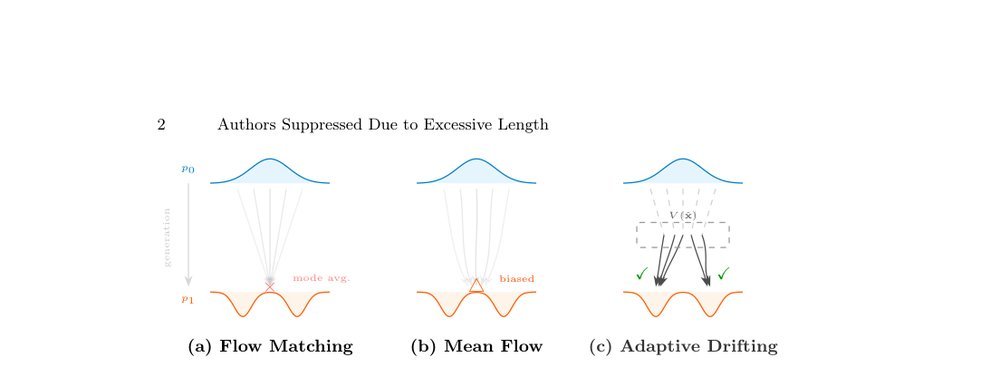
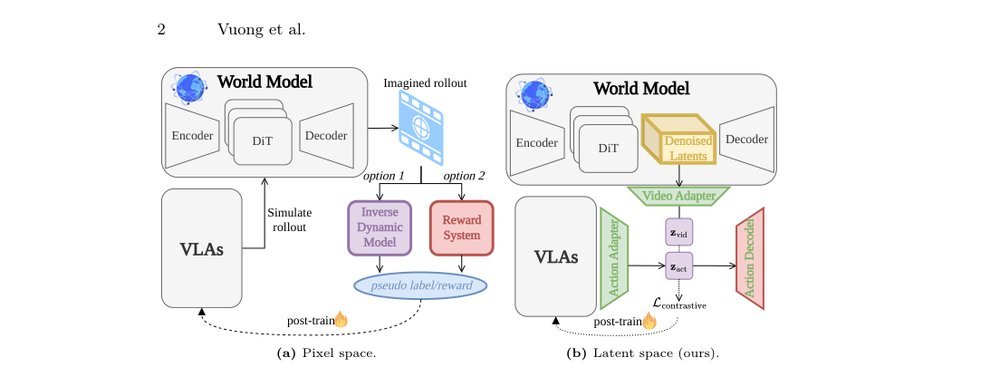
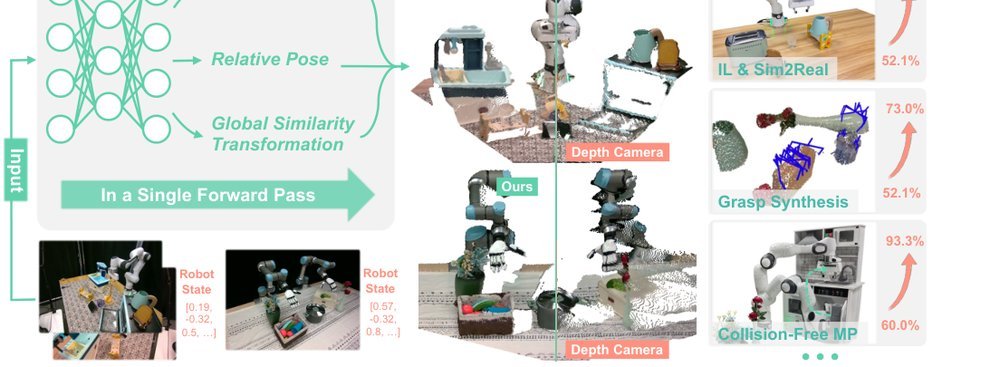
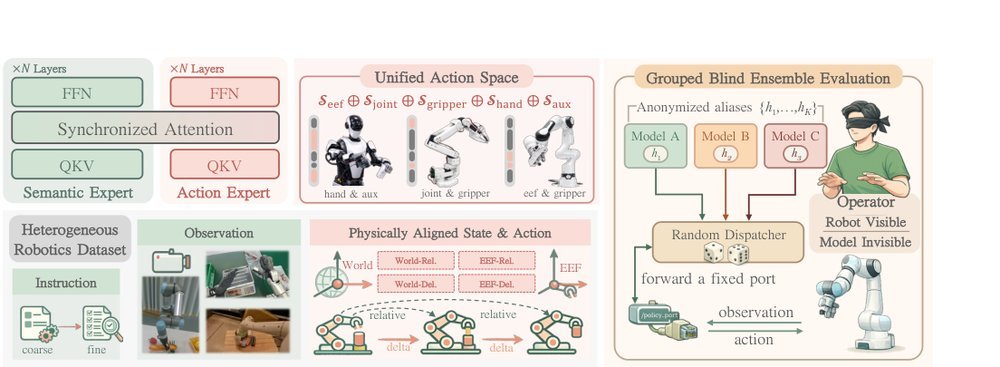
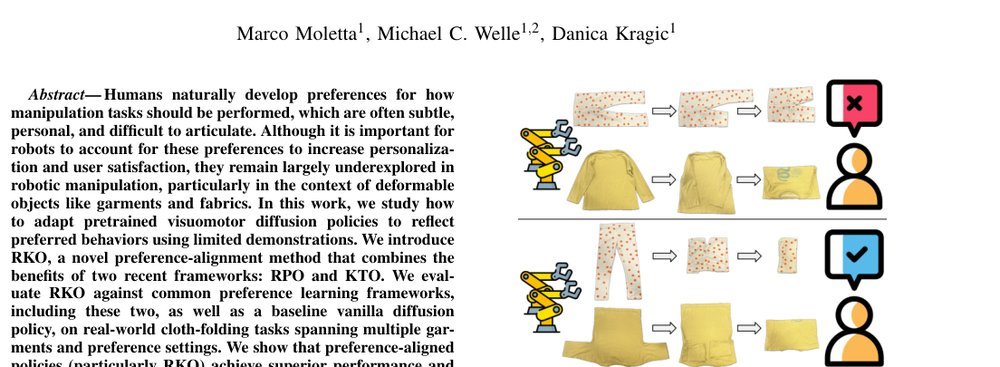
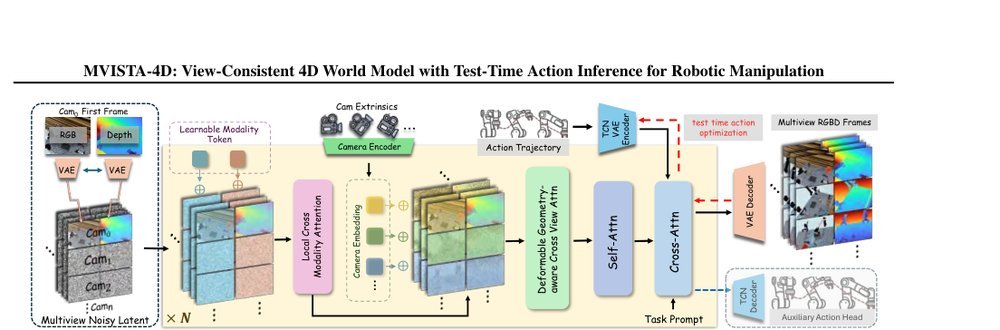
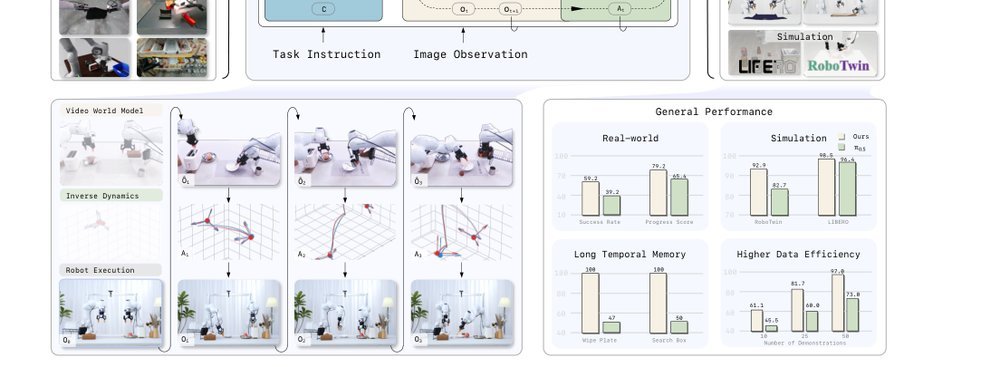
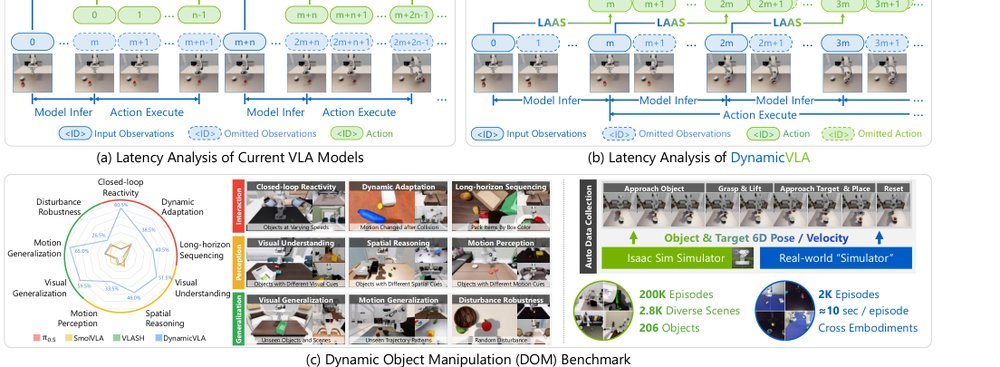
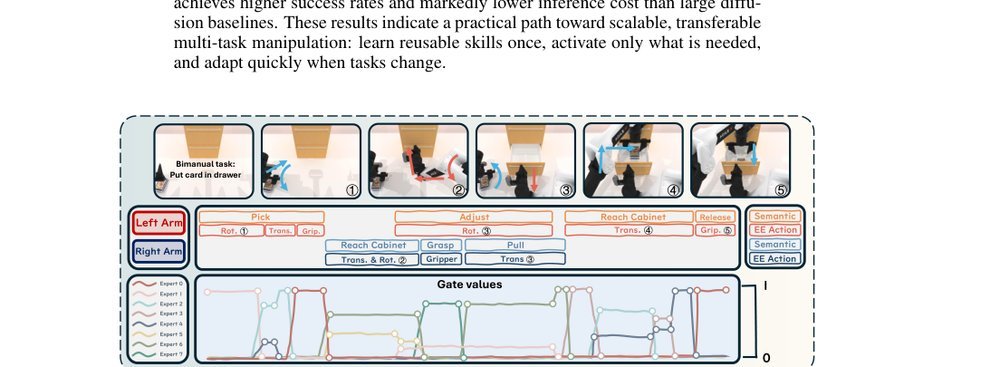
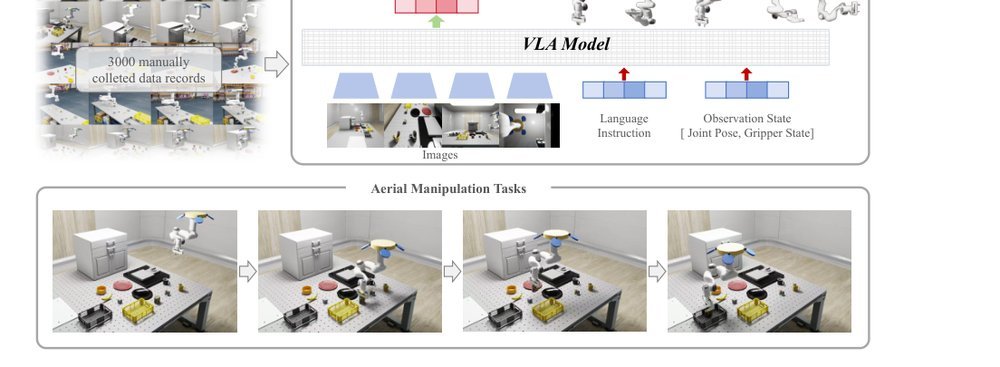
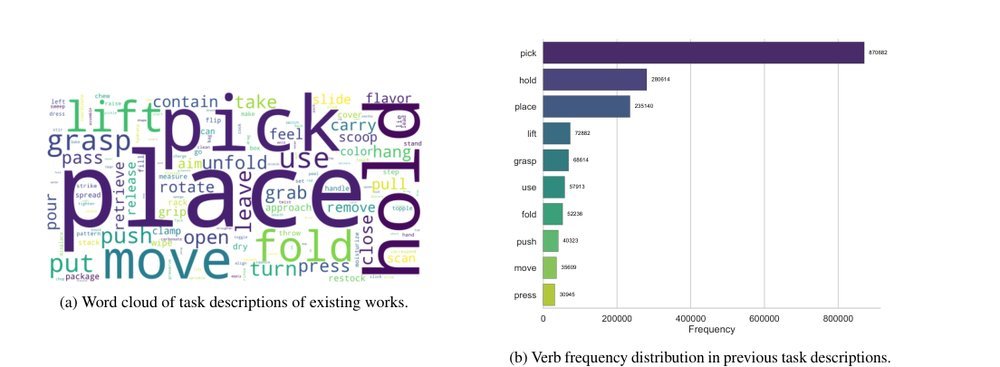
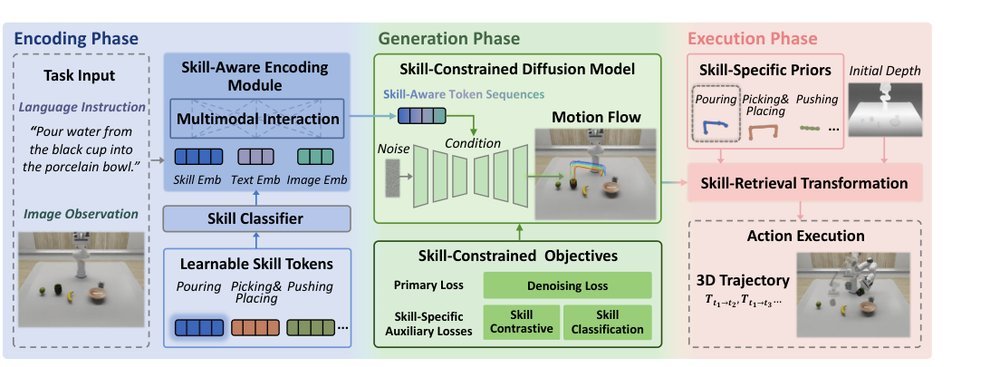
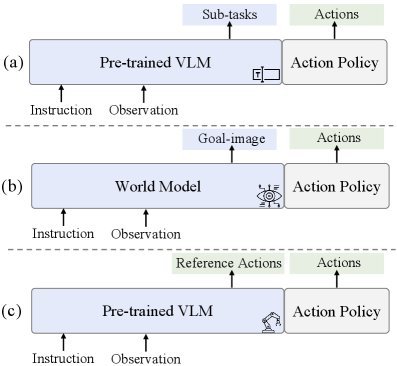
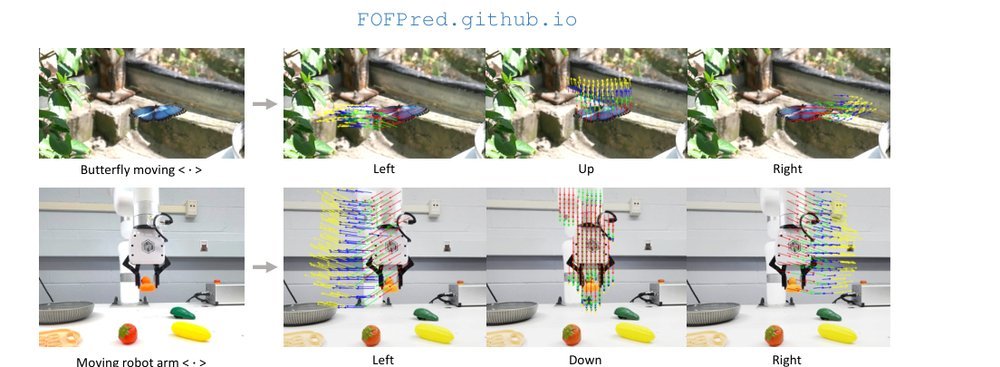
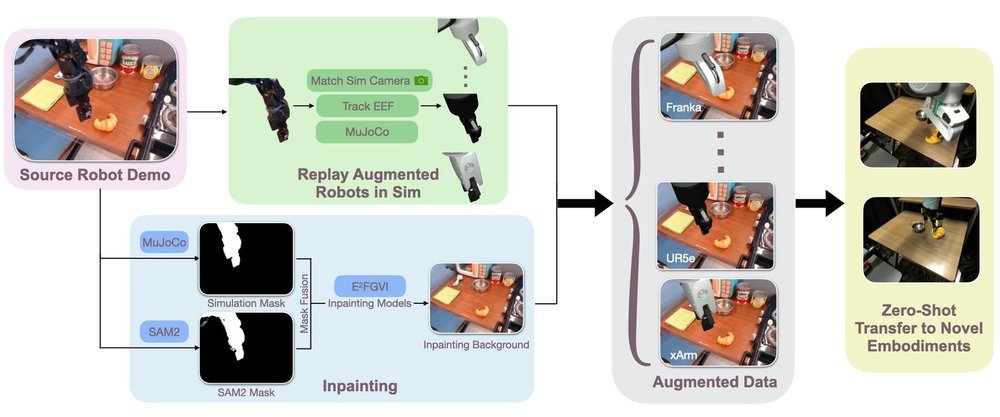
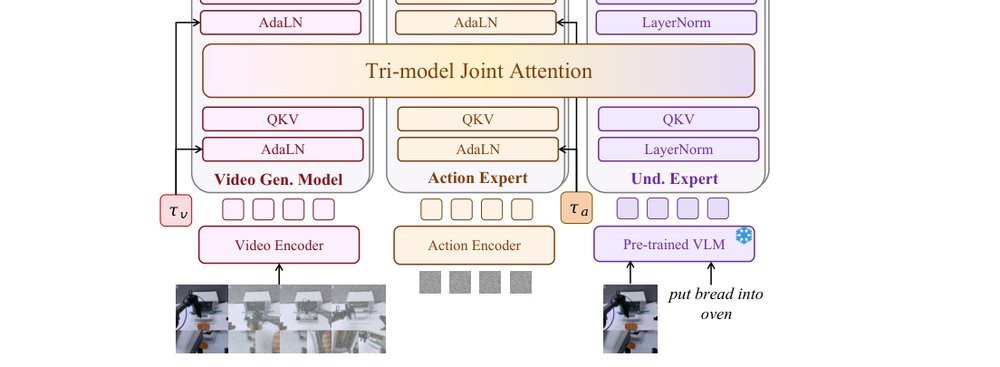
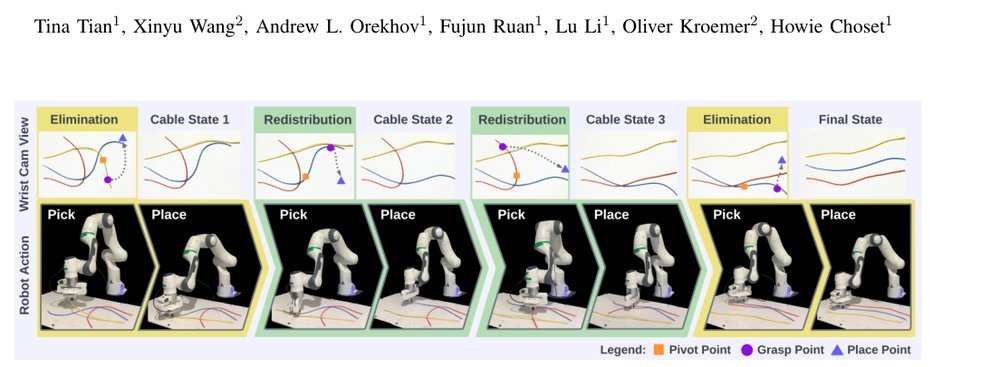
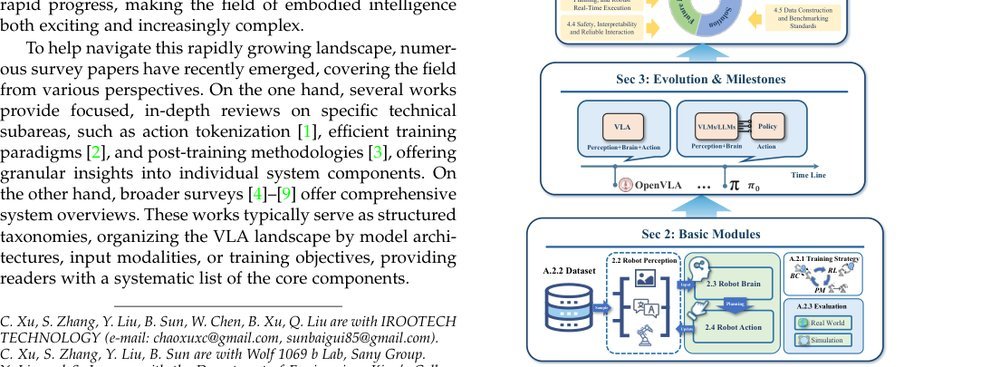
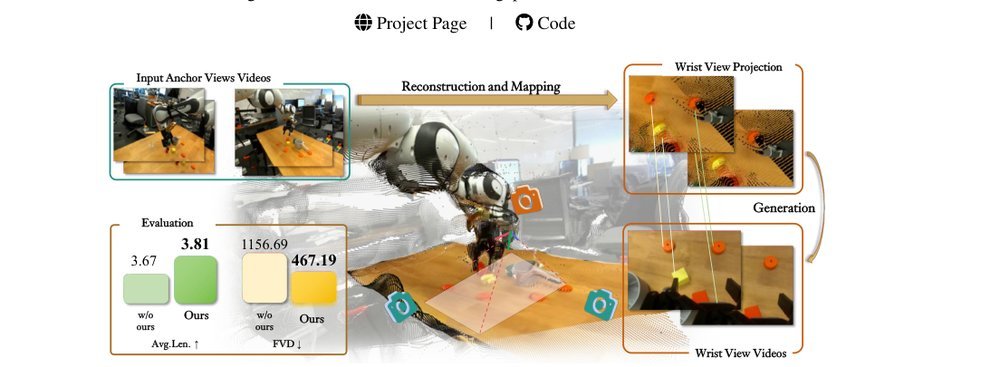
这篇工作针对机器人操作数据长期局限于少量实验室场景、导致泛化不足的问题,构建了“野外”分布式采集数据集 DROID:在统一 Franka 平台上跨 13 家机构收集 7.6 万条示范,覆盖 564 个场景、86 类任务,并提供多视角 RGB、深度、标定和语言指令。实验表明,用 DROID 训练的策略在 6 个任务、4 类地点上平均提升约 20%;增益看起来主要来自数据规模与场景多样性,而非新算法,因为文中沿用了现有 diffusion policy。