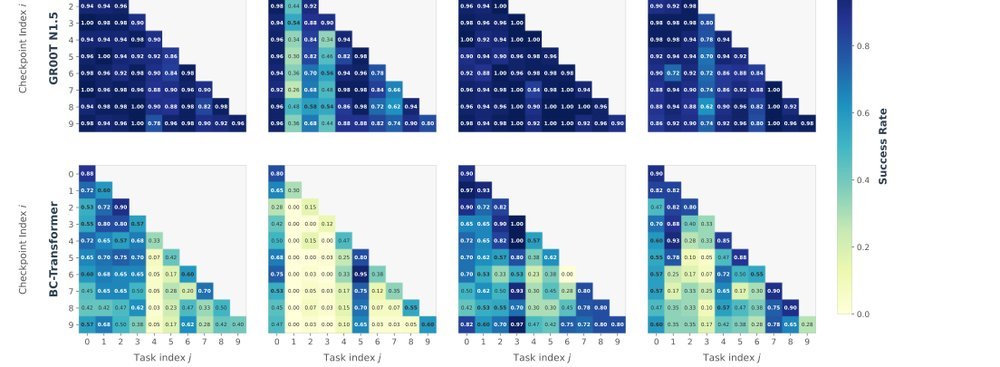
作者:Huihan Liu, Changyeon Kim Bo Liu, Minghuan Liu · 会议/期刊:arXiv · 日期:2026-03-04 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models for Generalization / Continue Learning