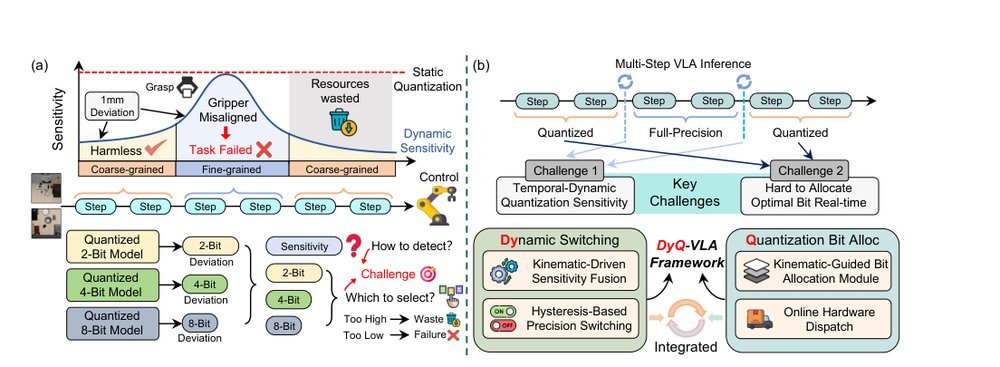
DyQ-VLA: Temporal-Dynamic-Aware Quantization for Embodied Vision-Language-Action Models
作者:Zihao Zheng, Hangyu Cao, Sicheng Tian, Jiayu Chen, Maoliang Li, Xinhao Sun, Hailong Zou, Zhaobo Zhang, Xuanzhe Liu, Donggang Cao, Hong Mei, Xiang Chen · 单位:School of Computer Science, Peking University, Beijing, China, School of Software Engineering, South China University of Technology, School of Artificial Intelligence, Beijing Normal University, Beijing, School of Electronics Engineering and Computer Science, Peking University, Beijing China · 会议/期刊:arXiv · 日期:2026-03-09 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Efficiency / Model Quantization