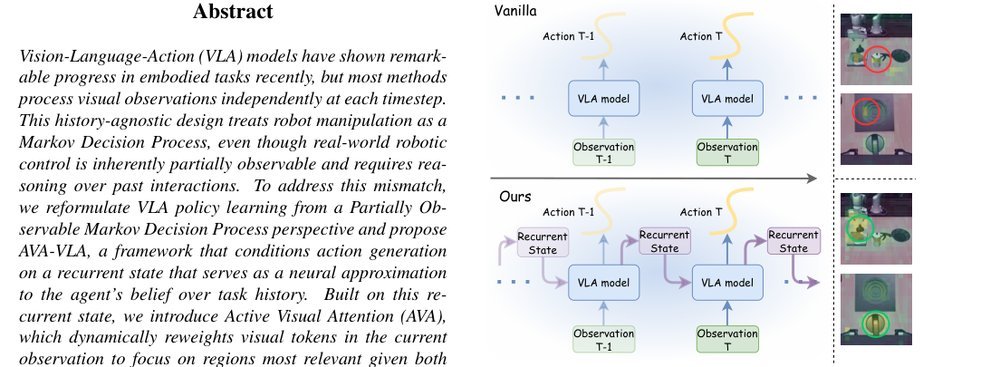
AVA-VLA: Improving Vision-Language-Action models with Active Visual Attention
作者:Lei Xiao, Jifeng Li, Juntao Gao, Feiyang Ye, Yan Jin, Jingjing Qian, Jing Zhang, Yong Wu, Xiaoyuan Yu · 单位:Beijing University of Technology, The Chinese University of Hong Kong, Shenzhen · 会议/期刊:CVPR 2026 · 日期:2025-11-24 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Model-agnostic Strategies