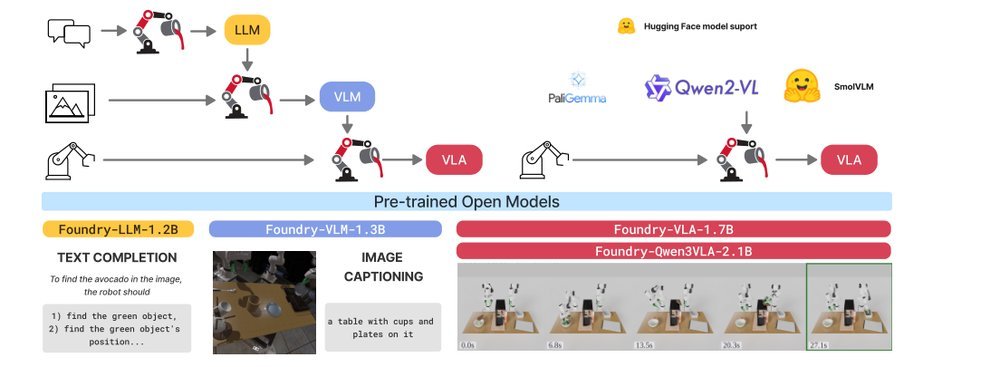
作者:Jean Mercat, Sedrick Keh, Kushal Arora, Isabella Huang, Paarth Shah, Haruki Nishimura, Shun Iwase, Katherine Liu · 单位:Toyota Research Institute · 会议/期刊:arXiv · 日期:2026-04-21 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D LLM-based Vision Language Action Models