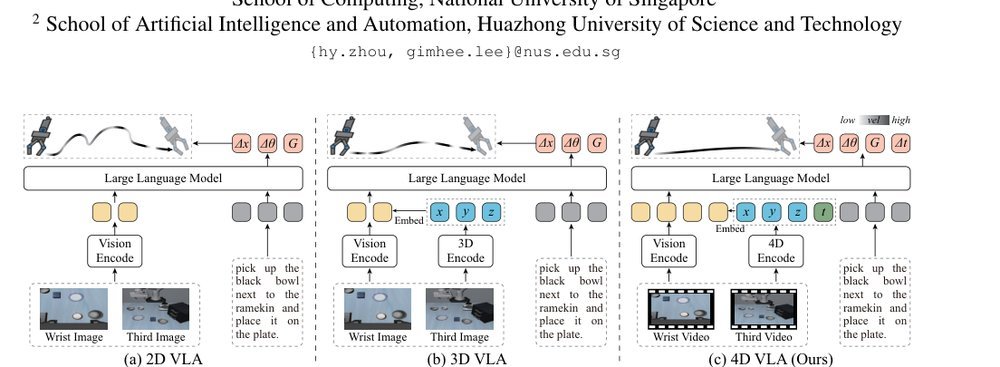
VLA-4D: Embedding 4D Awareness into Vision-Language-Action Models for SpatioTemporally Coherent Robotic Manipulation
作者:Hanyu Zhou, Chuanhao Ma, Gim Hee Lee · 单位:School of Computing, National University of Singapore · 会议/期刊:arXiv · 日期:2025-11-21 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 3D Vision Language Action Models