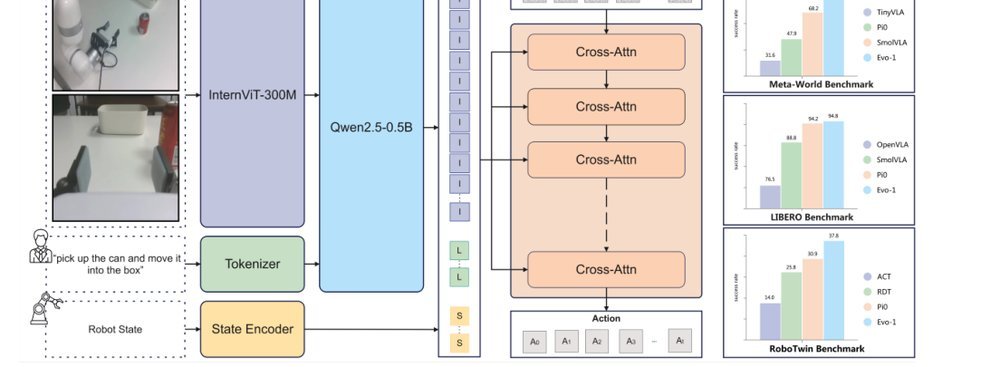
作者:Tao Lin, Yilei Zhong, Yuxin Du, Jingjing Zhang, Jiting Liu, Yinxinyu Chen, Encheng Gu, Ziyan Liu, Hongyi Cai, Yanwen Zou, Lixing Zou, Zhaoye Zhou, Gen Li, Bo Zhao · 单位:School of AI, Shanghai Jiao Tong University, Carnegie Mellon University, University of Cambridge, Nanyang Technological University · 会议/期刊:CVPR 2026 · 日期:2025-11-06 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Efficiency / Small Model