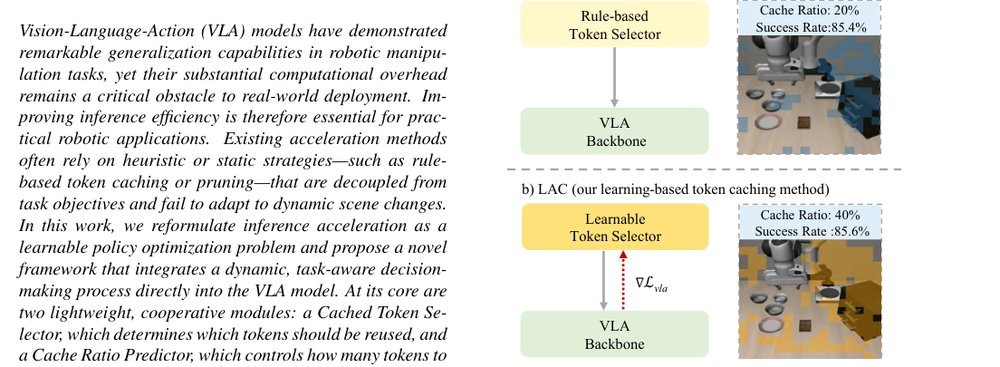
作者:Yujie Wei, Jiahan Fan, Jiyu Guo, Ruichen Zhen, Rui Shao, Xiu Su, Zeke Xie, Shuo Yang B · 单位:Harbin Institute of Technology, Shenzhen, Meituan Academy of Robotics Shenzhen, Meituan, Central South University, HKUST(GZ) · 会议/期刊:arXiv · 日期:2026-01-31 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Efficiency / Token Pruning