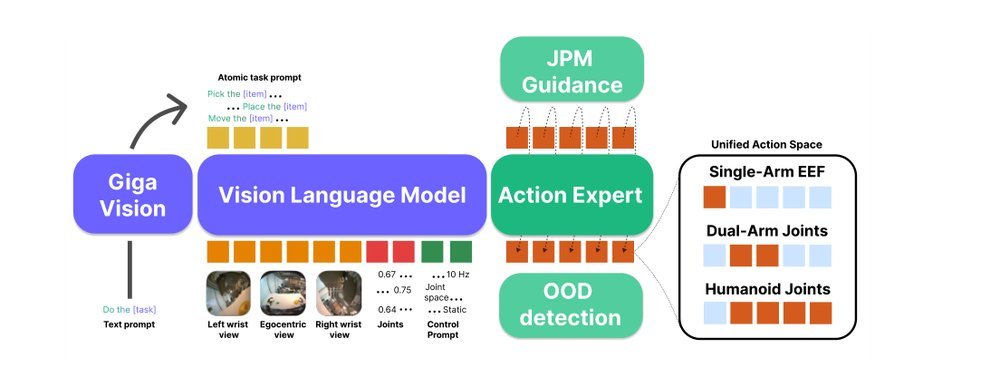
作者:Manipulation Team, R ) multi-embodiment pretraining, R ) embodiment-specific adaptation, physical priors, learns shared affordances, control stack for · 单位:robot fleets. A scalable data-processing pipeline including DataQA, Sber Robotics Center · 会议/期刊:arXiv · 日期:2026-01-31 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D LLM-based Vision Language Action Models