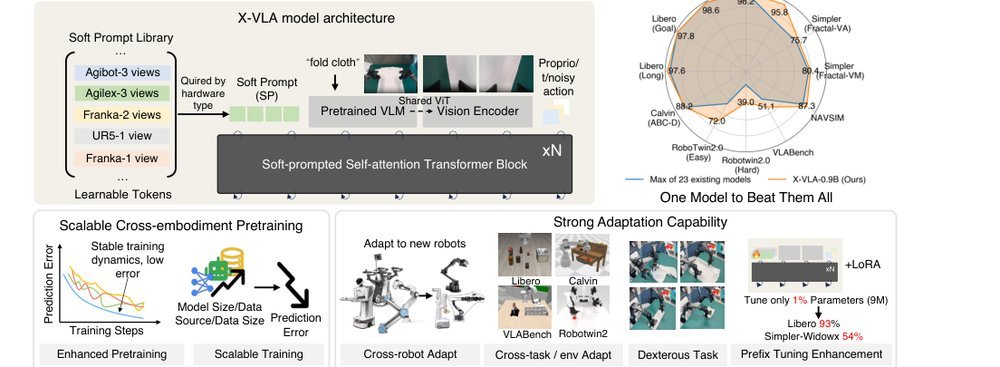
作者:Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, Ya-Qin Zhang, Jiangmiao Pang, Jingjing Liu, Tai Wang, Xianyuan Zhan · 单位:Institute for AI Industry Research (AIR), Tsinghua University, Shanghai AI Lab, Peking University · 会议/期刊:ICLR 2026 · 日期:2025-10-11 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D LLM-based Vision Language Action Models