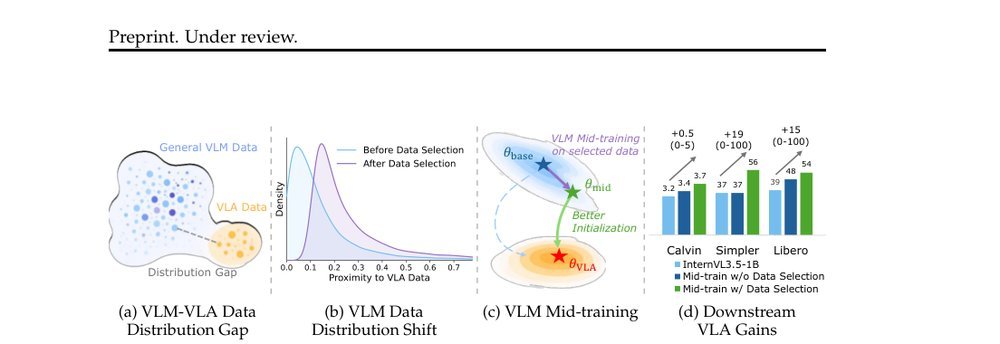
EmbodiedMidtrain: Bridging the Gap between Vision-Language Models and Vision-Language-Action Models via Mid-training
作者:Preprint. Under review. Yiyang Du, Zhanqiu Guo, Xin Ye, Liu Ren, Chenyan Xiong · 单位:Language Technologies Institute, Carnegie Mellon University · 会议/期刊:arXiv · 日期:2026-04-21 · 来源:Bottlenecks / Data Collection and Utilization / Data Selection