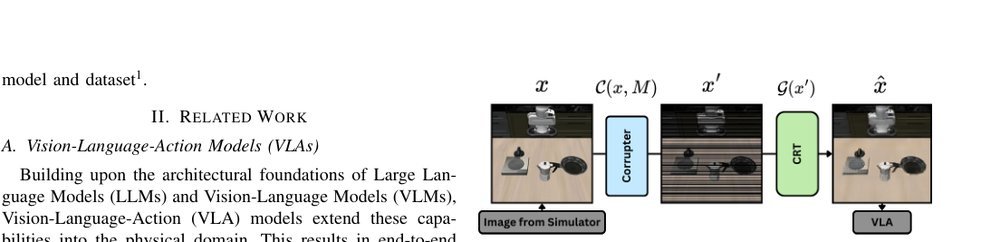
作者:Daniel Yezid Guarnizo Orjuela, Leonardo Scappatura, Veronica Di Gennaro Riccardo Andrea Izzo, Gianluca Bardaro, Matteo Matteucci · 单位:Department of Electronics, Information, and Bioengineering · 会议/期刊:arXiv · 日期:2026-02-01 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Robustness / Attack