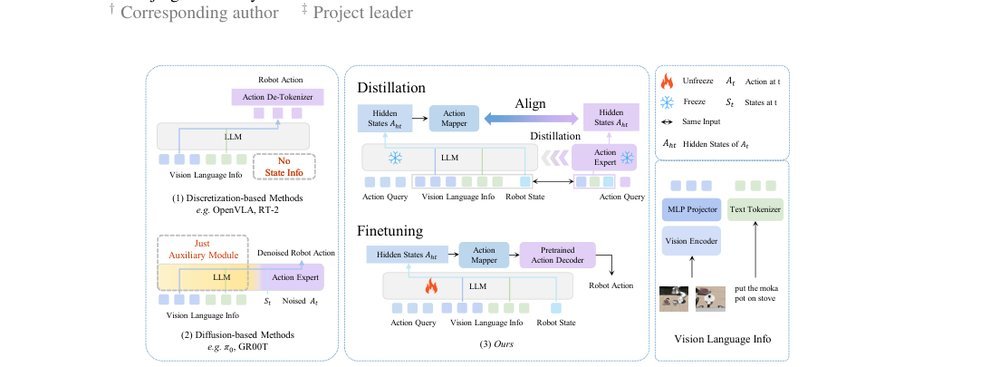
作者:Shaoqi Dong, Chaoyou Fu, Haihan Gao, Yi-Fan Zhang, Chi Yan, Chu Wu, Xiaoyu Liu, Yunhang Shen, Jing Huo, Deqiang Jiang, Haoyu Cao, Yang Gao, Xing Sun, Ran He, Caifeng Shan · 单位:Nanjing University, Tencent Youtu Lab · 会议/期刊:arXiv · 日期:2025-10-10 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Efficiency / Training-efficient Adaptation