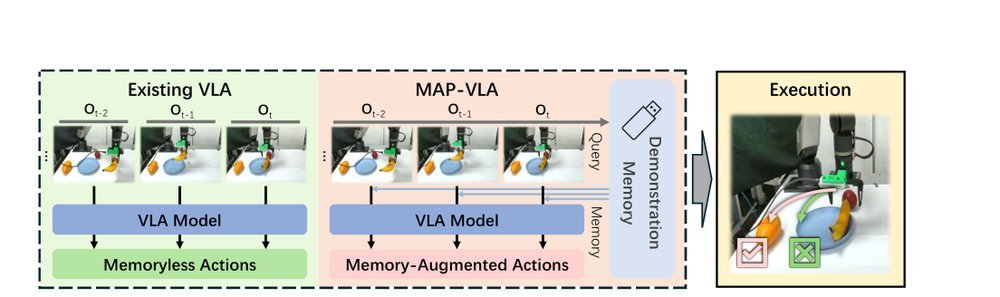
作者:Runhao Li, Wenkai Guo, Zhenyu Wu, Changyuan Wang, Haoyuan Deng, Zhenyu Weng, Yap-Peng Tan, Ziwei Wang · 单位:Nanyang Technological University, Singapore, Singapore, VinUniversity, Hanoi, Vietnam, Beijing University of Posts and Telecommunications, Beijing, China, Tsinghua University, Beijing, China, South China University of Technology, Guangzhou, China · 会议/期刊:arXiv · 日期:2025-11-12 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Model-agnostic Strategies