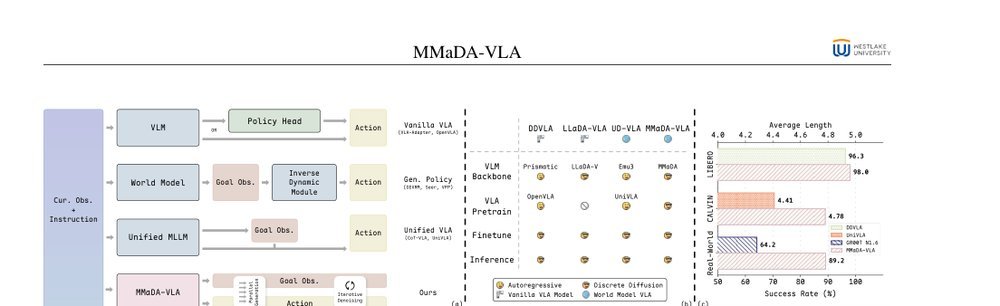
MMaDA-VLA: Large Diffusion Vision-Language-Action Model with Unified Multi-Modal Instruction and Generation
作者:Yang Liu, Pengxiang Ding, Tengyue Jiang, Xudong Wang, Minghui Lin, Wenxuan Song, Hongyin Zhang, Zifeng Zhuang, Han Zhao, Wei Zhao, Siteng Huang, Jinkui Shi, Donglin Wang · 单位:Westlake University Zhejiang University, East China University of Science and Technology, Huawei Celia Team, The Hong Kong University of Science and Technology (Guangzhou) · 会议/期刊:arXiv · 日期:2026-03-26 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D LLM-based Vision Language Action Models