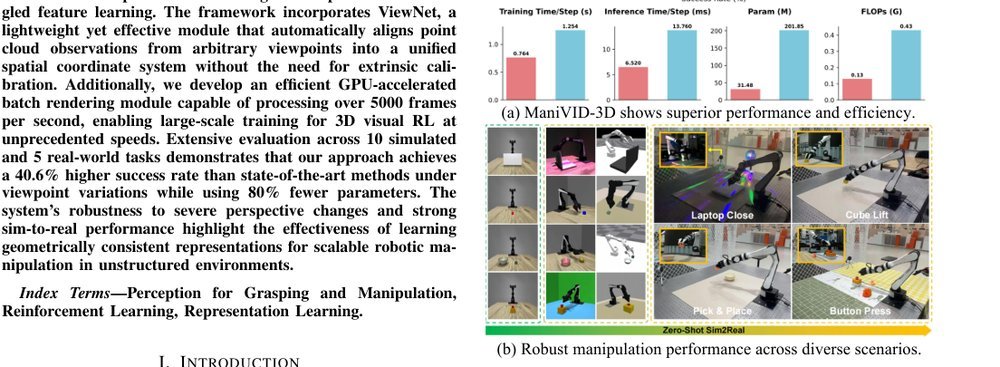
ManiVID-3D: Generalizable View-Invariant Reinforcement Learning for Robotic Manipulation via Disentangled 3D Representations
作者:Zheng Li, Pei Qu, Yufei Jia, Shihui Zhou, Haizhou Ge, Jiahang Cao, Jinni Zhou, Guyue Zhou, Jun Ma · 单位:The Hong Kong University of Science and Technology (Guangzhou), Guangzhou, Tsinghua University, The University of Hong Kong, Hong Kong SAR · 会议/期刊:RA-L 2026 · 日期:2026-09-14 · 来源:Bottlenecks / Generalization / SE(3)/SIM(3)-Equivariance/View Changes