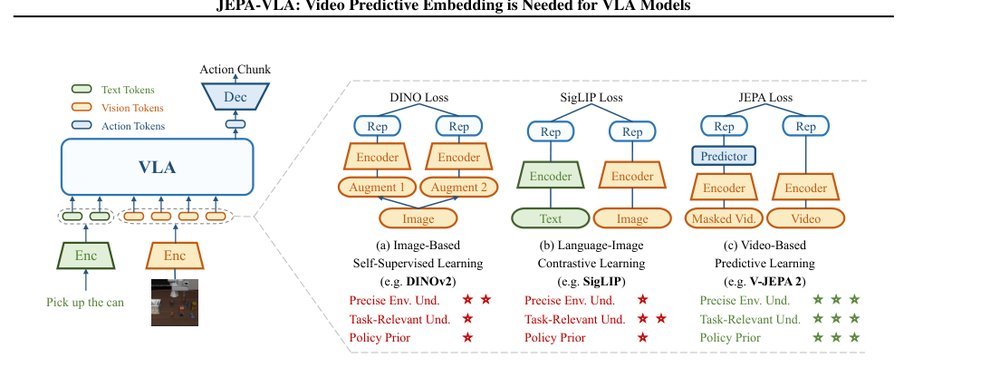
作者:Shangchen Miao, Ningya Feng, Jialong Wu, Ye Lin, Xu He, Dong Li, Mingsheng Long · 单位:Tsinghua University Huawei Noah’s Ark Lab. Correspon · 会议/期刊:arXiv · 日期:2026-02-12 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Latent Learning