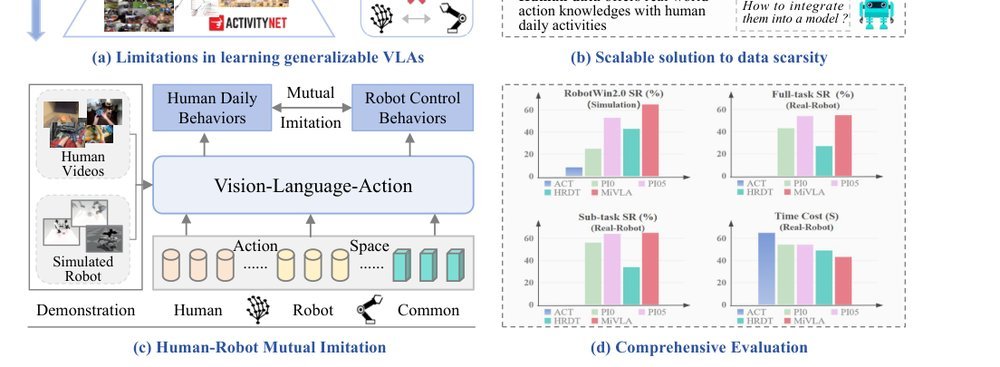
作者:Zhenhan Yin, Xuanhan Wang, Jiahao Jiang, Kaiyuan Deng, Pengqi Chen, Shuangle Li, Chong Liu, Xing Xu, Jingkuan Song, Lianli Gao, Heng Tao Shen · 单位:Tongji University, University of Electronic Science and Technology of China · 会议/期刊:arXiv · 日期:2025-12-17 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D LLM-based Vision Language Action Models