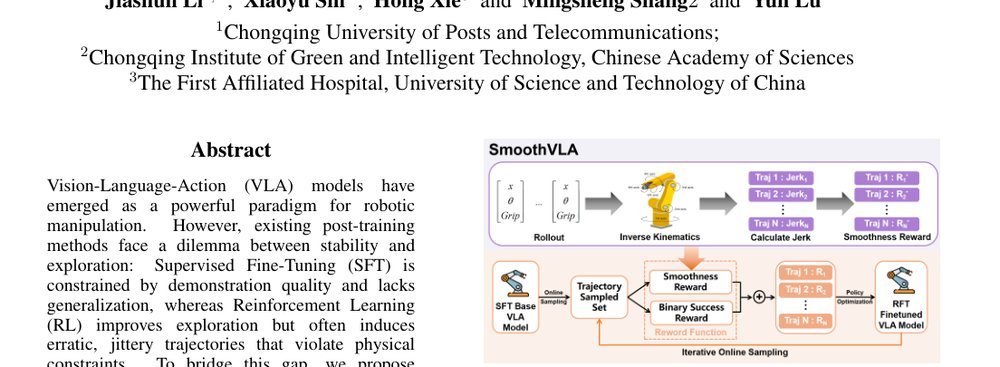
SmoothVLA: Aligning Vision-Language-Action Models with Physical Constraints via Intrinsic Smoothness Optimization
作者:Jiashun Li, Xiaoyu Shi, Hong Xie, Mingsheng Shang, Yun Lu · 单位:Chongqing University of Posts and Telecommunications, Chongqing Institute of Green and Intelligent Technology, Chinese Academy of Sciences · 会议/期刊:arXiv · 日期:2026-03-14 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with RL