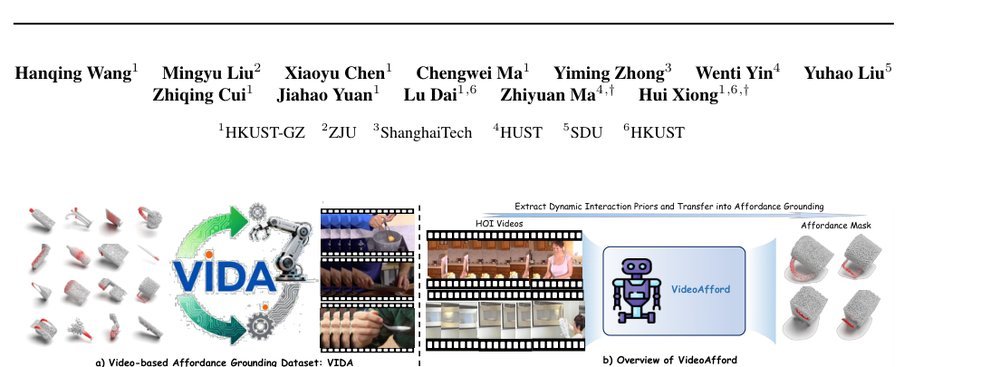
作者:Hanqing Wang, Mingyu Liu, Xiaoyu Chen, Chengwei Ma, Yiming Zhong, Wenti Yin, Yuhao Liu, Zhiqing Cui, Jiahao Yuan, Lu Dai, Zhiyuan Ma, Hui Xiong · 单位:HKUST-GZ · 会议/期刊:arXiv · 日期:2026-02-10 · 来源:README / 📊 Awesome Simulators, Benchmarks and Dataset / Embodied QA and Affordance Datasets