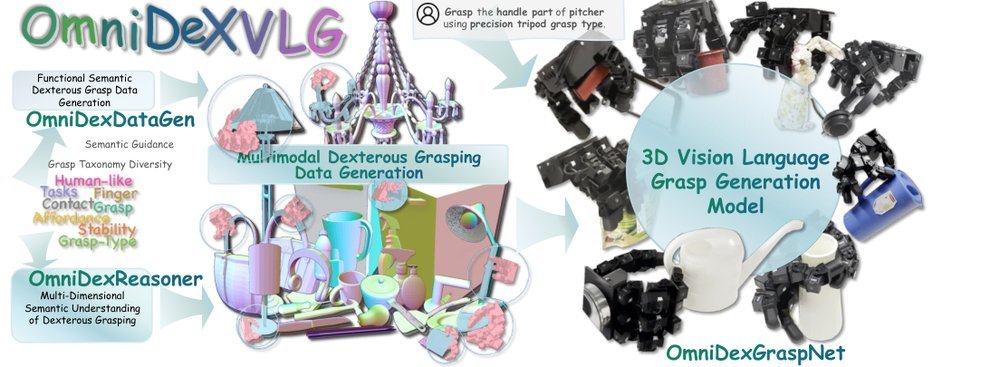
作者:Lei Zhang, Diwen Zheng, Kaixin Bai, Zhenshan Bing, Zolt´an-Csaba M´arton, Zhaopeng Chen, Alois Christian Knoll, Jianwei Zhang · 单位:University of Hamburg, Technical University of Munich · 会议/期刊:arXiv · 日期:2025-12-03 · 来源:Manipulation Tasks / Grasp / Dexterous Grasp