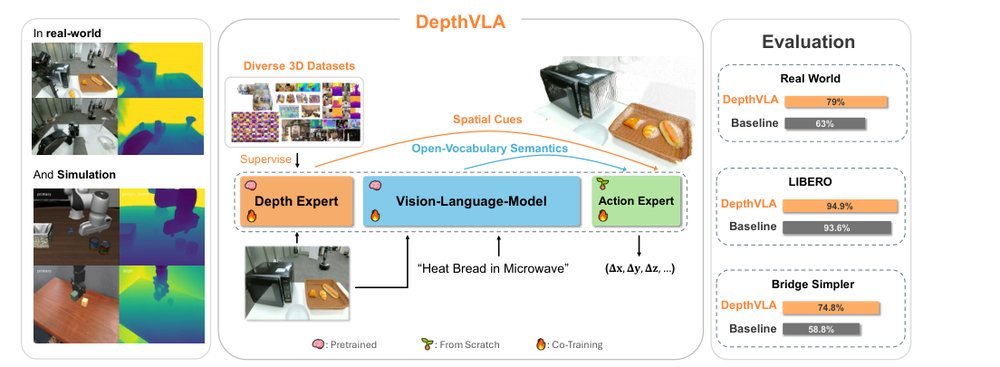
作者:Tianyuan Yuan, Yicheng Liu, Chenhao Lu, Zhuoguang Chen, Tao Jiang, Hang Zhao · 单位:IIIS, Tsinghua University · 会议/期刊:arXiv · 日期:2025-10-15 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 3D Vision Language Action Models