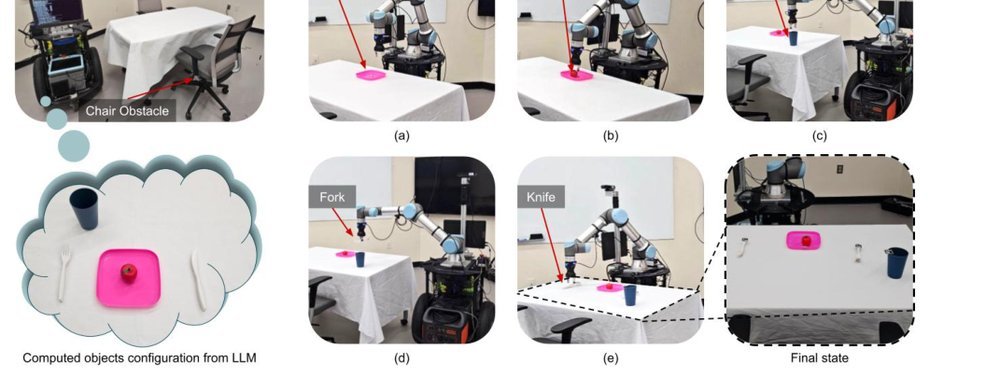
作者:©The Author(s) Reprints, Yan Ding, Yohei Hayamizu, Zainab Altaweel, Yifeng Zhu, Yuke Zhu, Peter Stone, Chris Paxton, Shiqi Zhang · 单位:The State University of New York at Binghamton, The University of Texas at Austin, Sony AI, Shanghai AI Laboratory · 会议/期刊:IJRR 2025 · 日期:2025-11-11 · 来源:High-Level Structured Planning / Task Planning