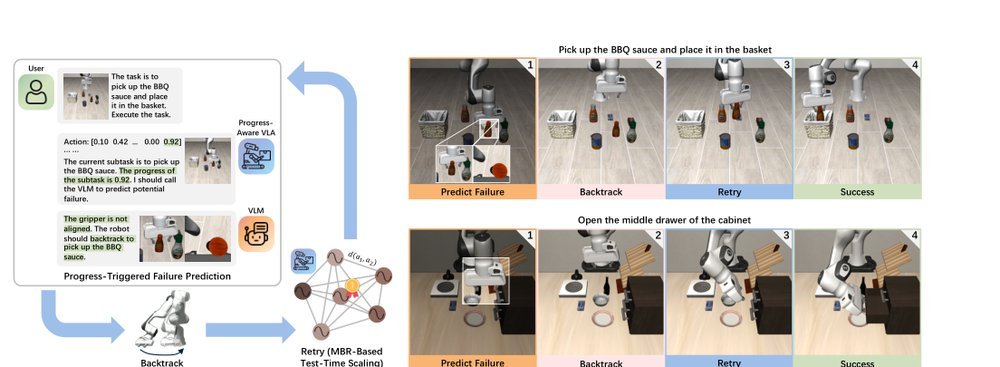
CycleVLA: Proactive Self-Correcting Vision-Language-Action Models via Subtask Backtracking and Minimum Bayes Risk Decoding
作者:Chenyang Ma, Guangyu Yang, Kai Lu, Shitong Xu, Bill Byrne, Niki Trigoni, Andrew Markham, 𝑎") Pick up the BBQ sauce · 单位:Department of Computer Science, University of Oxford, Department of Engineering, University of Cambridge · 会议/期刊:arXiv · 日期:2026-01-05 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Robustness / Failure Analysis & Recovery