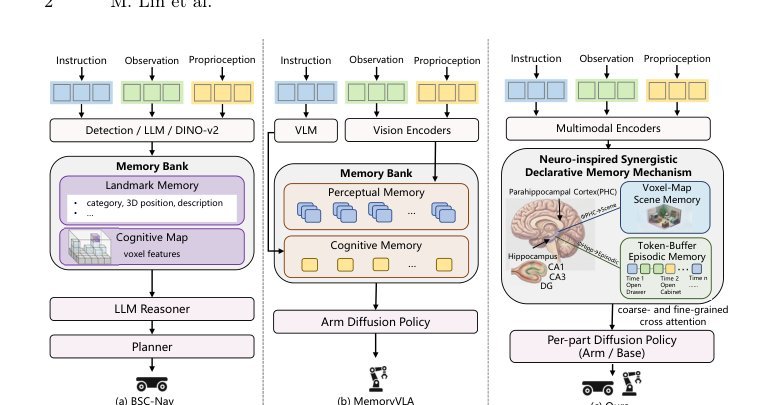
作者:Xiwen Liang, Bingqian Lin, Liu Jingzhi, Zijian Jiao, Kehan Li, Yu Sun, Weijia Liufu, Yuhan Ma, Yuecheng Liu, Shen Zhao, Yuzheng Zhuang, Xiaodan Liang · 单位:Shanghai Jiao Tong University, Shanghai, China, Huawei Noah’s Ark Lab, China · 会议/期刊:arXiv · 日期:2025-11-22 · 来源:Manipulation Tasks | Mobile Manipulation / Mobile Manipulation / VLA | VLA