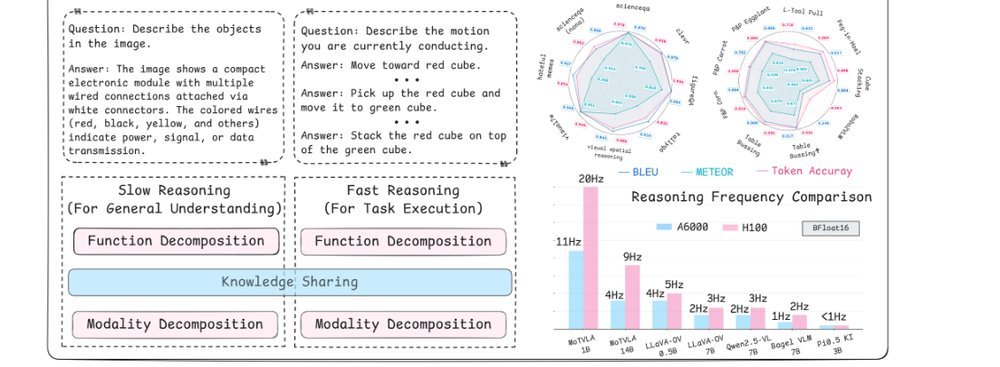
作者:Wenhui Huang Changhe Chen Han Qi, Chen Lv, Yilun Du, Heng Yang · 单位:Harvard University, University of Michigan, Nanyang Technological University · 会议/期刊:arXiv · 日期:2025-10-21 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Non-LLM-based Vision Language Action Models