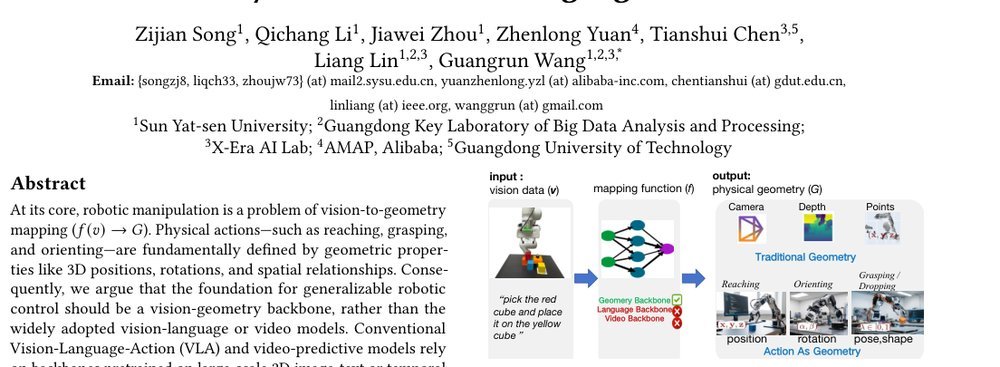
Robotic Manipulation is Vision-to-Geometry Mapping (f(v) \rightarrow G): Vision-Geometry Backbones over Language and Video Models
作者:Qichang Li, Jiawei Zhou, Zhenlong Yuan, Tianshui Chen, Liang Lin, Guangrun Wang · 单位:Sun Yat-sen University, Guangdong Key Laboratory of Big Data Analysis and Processing, X-Era AI Lab, Guangdong University of Technology · 会议/期刊:arXiv · 日期:2026-04-14 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 3D Vision Language Action Models