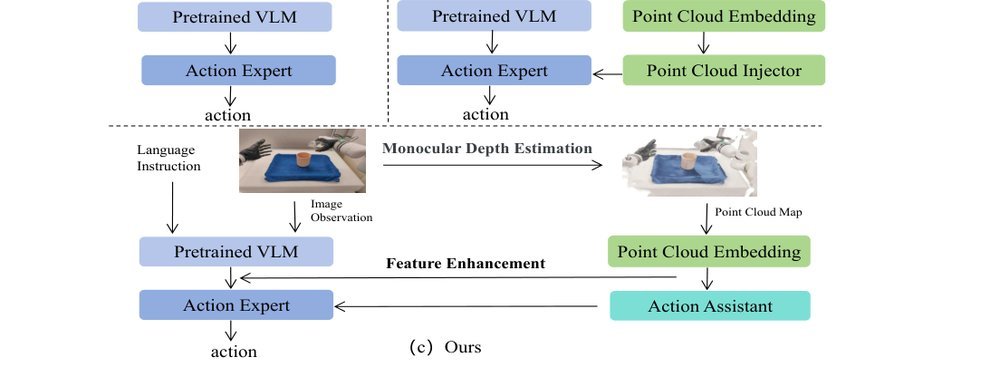
AugVLA-3D: Depth-Driven Feature Augmentation for Vision-Language-Action Models
作者:Zhifeng Rao, Wenlong Chen, Lei Xie, Xia Hua, Dongfu Yin, Zhen Tian, F. Richard Yu · 单位:Guangdong Laboratory of Artificial Intelligence and Digital Economy, School of Communication and Information Engineering, Shanghai Uni- versity, Shanghai, China, School of Information Technology, Carleton University, Ottawa, Canada · 会议/期刊:arXiv · 日期:2026-02-11 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 3D Vision Language Action Models