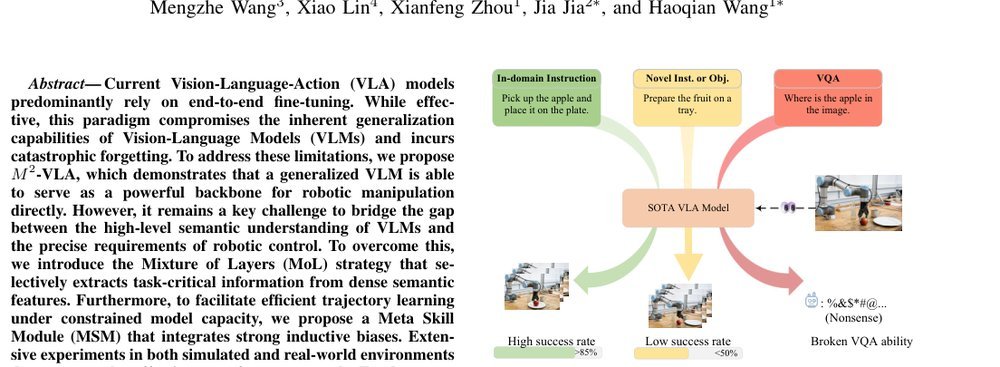
作者:Yuhong Zhang, Zhifang Liu, Zihan Gao, Jingye Zhang, Sinwai Choo, Dake Zhong, Mengzhe Wang, Xiao Lin, Xianfeng Zhou, Jia Jia, Haoqian Wang · 单位:Tsinghua Shenzhen International Graduate School, Tsinghua University, Peng Cheng Laboratory, Shenzhen, China, College of Intelligent Robotics and Advanced Manufacturing, Fudan University, Shanghai, China · 会议/期刊:arXiv · 日期:2026-04-27 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Efficiency / PEFT