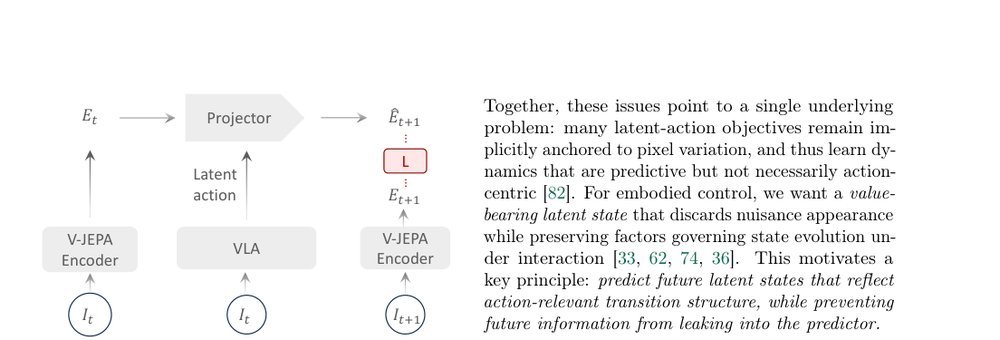
作者:Jingwen Sun, Wenyao Zhang, Zekun Qi, Shaojie Ren, Zezhi Liu, Hanxin Zhu, Guangzhong Sun, Xin Jin, Zhibo Chen · 单位:University of Science and Technology of China Zhongguancun Academy, Beijing, China Shanghai Jiao · 会议/期刊:arXiv · 日期:2026-02-10 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Latent Learning