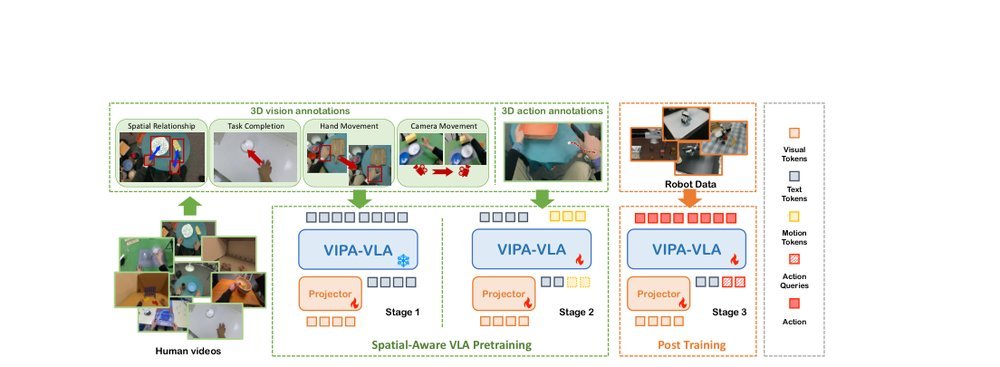
作者:Yicheng Feng, Wanpeng Zhang, Ye Wang, Hao Luo, Haoqi Yuan, Sipeng Zheng, Zongqing Lu · 单位:Peking University, Renmin University of China · 会议/期刊:CVPR 2026 · 日期:2025-12-15 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 3D Vision Language Action Models