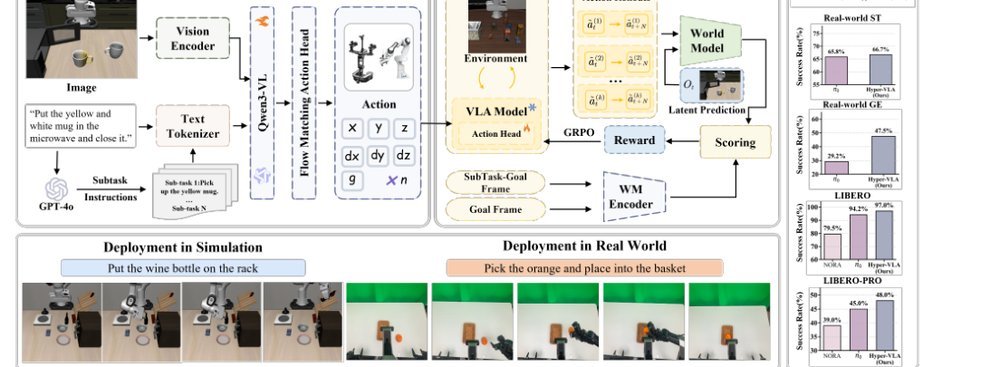
AtomVLA: Scalable Post-Training for Robotic Manipulation via Predictive Latent World Models
作者:Xiaoquan Sun, Zetian Xu, Chen Cao, Zonghe Liu, Yihan Sun, Jingrui Pang, Ruijian Zhang, Zhen Yang, Kang Pang, Dingxin He, Mingqi Yuan, Jiayu Chen · 单位:The University of Hong Kong, Hong Kong SAR, China, Huazhong University of Science and Technology, Wuhan, China, Tsinghua University, Beijing, China · 会议/期刊:arXiv · 日期:2026-03-09 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Auxiliary Tasks - World Model & Visual Prediction / World Model