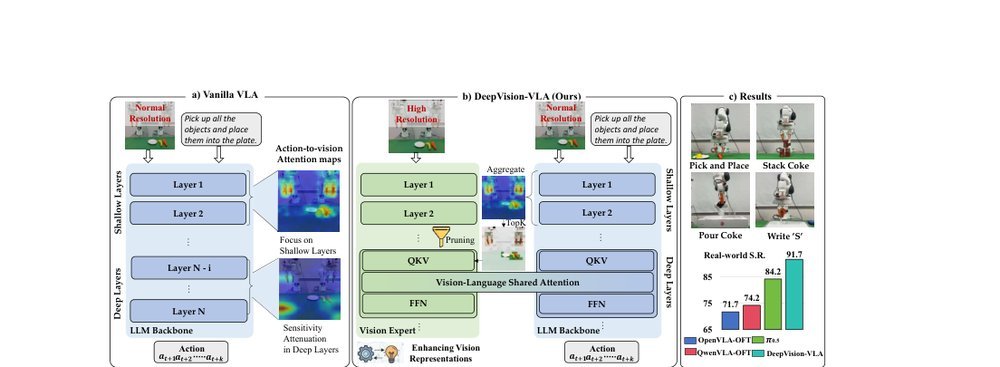
作者:Yulin Luo, Hao Chen, Zhuangzhe Wu, Bowen Sui, Jiaming Liu, Chenyang Gu, Zhuoyang Liu, Qiuxuan Feng, Jiale Yu, Shuo Gu, Peng Jia, Pheng-Ann Heng, Shanghang Zhang · 单位:State Key Laboratory of Multimedia Information Processing, School of Computer Science Peking University, The Chinese University of Hong Kong · 会议/期刊:arXiv · 日期:2026-03-16 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Latent Learning