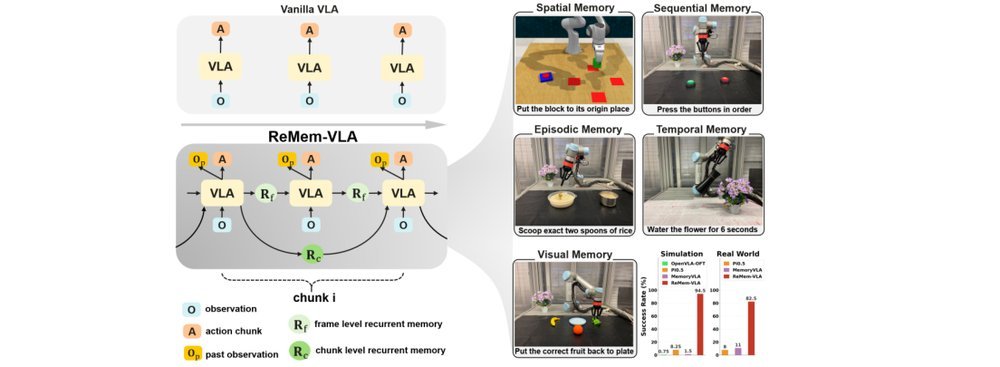
作者:Hang Li, Fengyi Shen, Dong Chen, Liudi Yang, Xudong Wang, Jinkui Shi, Zhenshan Bing, Ziyuan Liu, Alois Knoll · 单位:Technical University of Munich, Munich, Germany, Huawei Heisenberg Research Center, Munich, Germany, University of Freiburg, Freiburg, Germany, Nanjing University, China, Huawei Technologies, China · 会议/期刊:arXiv · 日期:2026-03-13 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Latent Learning