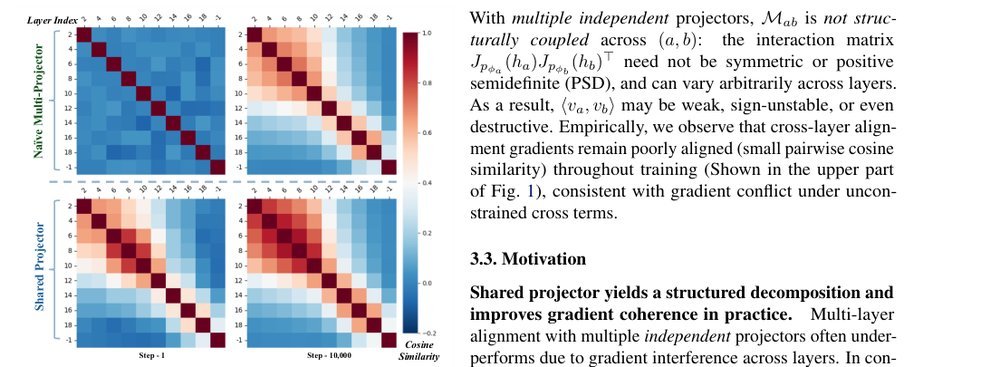
ROCKET: Residual-Oriented Multi-Layer Alignment for Spatially-Aware Vision-Language-Action Models
作者:Guoheng Sun Tingting Du, Kaixi Feng, Chenxiang Luo, Xingguo Ding, Zheyu Shen, Ziyao Wang, Yexiao He, Ang Li ghsun@umd.edu angliece@umd.edu · 单位:University of Maryland, College Park University of Wiscon · 会议/期刊:arXiv · 日期:2026-02-20 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 3D Vision Language Action Models