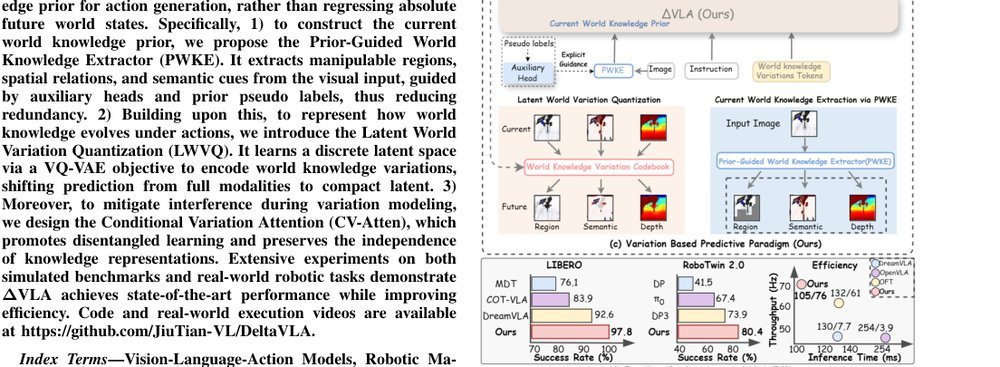
作者:Yijie Zhu, Jie He, Rui Shao, Member, Kaishen Yuan, Tao Tan, Xiaochen Yuan, Zitong Yu · 单位:Knowledge Extractor (PWKE). It extracts manipulable regions, Harbin Institute of Technology, Shenzhen, Shenzhen, Science and Technology (Guangzhou), Guangzhou 511400, China, Macao Polytechnic University, Macao, Great Bay University, Dongguan 523000, China · 会议/期刊:arXiv · 日期:2026-03-09 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 3D Vision Language Action Models