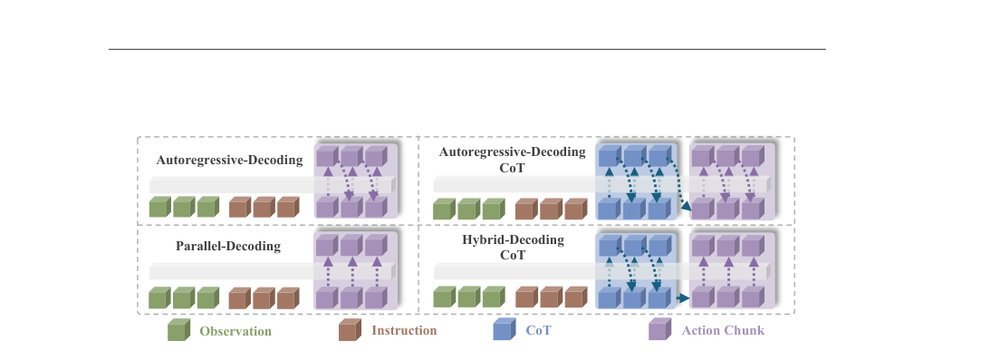
作者:Cheng Yin, Yankai Lin, Wang Xu, Sikyuen Tam, Xiangrui Zeng, Zhiyuan Liu, Zhouping Yin · 单位:Department of Computer Science and Technology, Tsinghua University, China, Gaoling School of Artificial Intelligence, Renmin University of China, China, Beijing Zhongguancun Academy, China · 会议/期刊:arXiv · 日期:2025-11-31 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Auxiliary Tasks - Text Goal Extraction