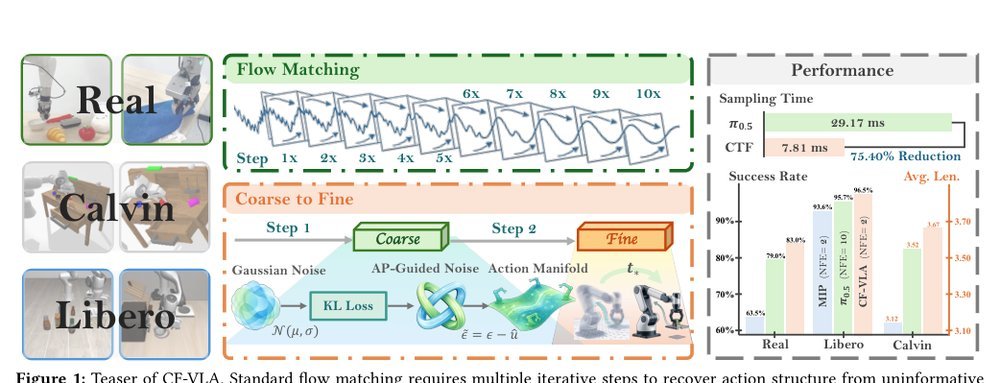
CF-VLA: Efficient Coarse-to-Fine Action Generation for Vision-Language-Action Policies
作者:Fan Du, Feng Yan, Jianxiong Wu, Xinrun Xu, Weiye Zhang, Weinong Wang, Yu Guo, Bin Qian, Zhihai He, Fei Wang, Heng Yang · 单位:Southern University of Science and Technology, Xi’an Jiaotong University, United Nova Technology, University of Science and Technology of China · 会议/期刊:arXiv · 日期:2026-04-27 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Model-agnostic Strategies