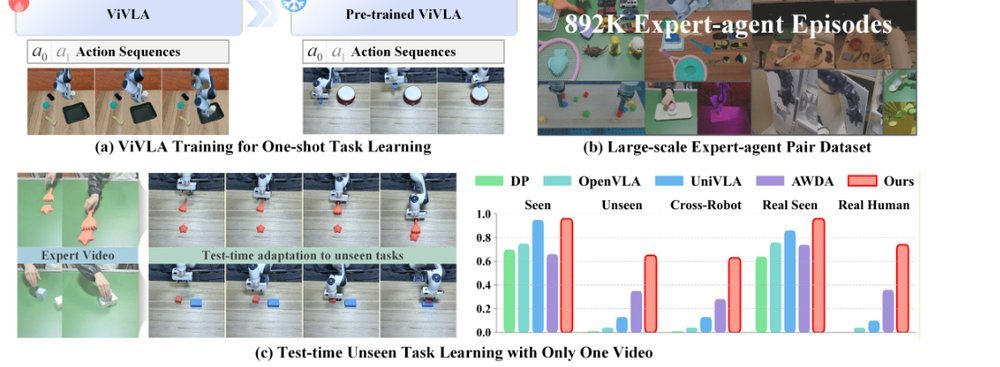
作者:Guangyan Chen, Meiling Wang, Qi Shao, Zichen Zhou, Weixin Mao, Te Cui, Minzhao Zhu, Yinan Deng, Luojie Yang, Zhanqi Zhang, Yi Yang, Hua Chen, Yufeng Yue · 单位:Beijing Institute of Technology · 会议/期刊:arXiv · 日期:2025-12-08 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models for Generalization / Test-time Adaptation