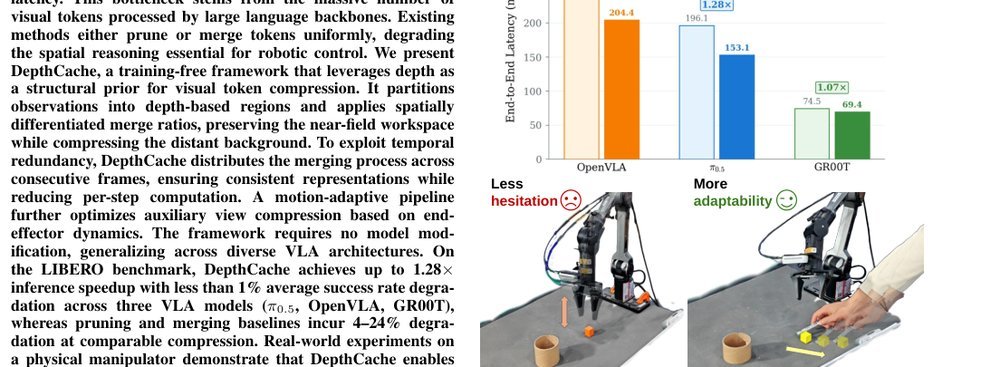
DepthCache: Depth-Guided Training-Free Visual Token Merging for Vision-Language-Action Model Inference
作者:Yuquan Li, Lianjie Ma, Han Ding, Lijun Zhu · 单位:School of Artificial Intelligence and Automation, Huazhong Uni, School of Mechanical Science and Engineering, Huazhong University, of Science and Technology, Wuhan, China · 会议/期刊:arXiv · 日期:2026-03-11 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 3D Vision Language Action Models