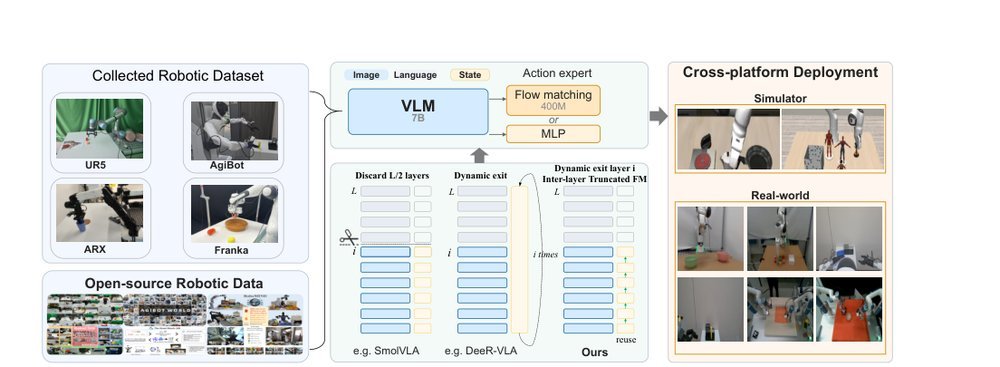
作者:Spatialtemporal AI | ATeam Kaidong Zhang, Jian Zhang, Rongtao Xu, Yu Sun, Shuoshuo Xue, Youpeng Wen, Xiaoyu Guo, Minghao Guo, Weijia Liufu, Liu Zihou, Kangyi Ji, Yangsong Zhang, Jiarun Zhu, Jingzhi Liu, Zihang Li, Ruiyi Chen, Meng Cao, Jingming Zhang, Shen Zhao, Xiaojun Chang, Feng Zheng, Ivan Laptev, Xiaodan Liang, SYSU, MBZUAI, Spatialtemporal AI Equal contribution, Project Lead, Correspondence · 会议/期刊:arXiv · 日期:2026-04-07 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Efficiency / Part of Model