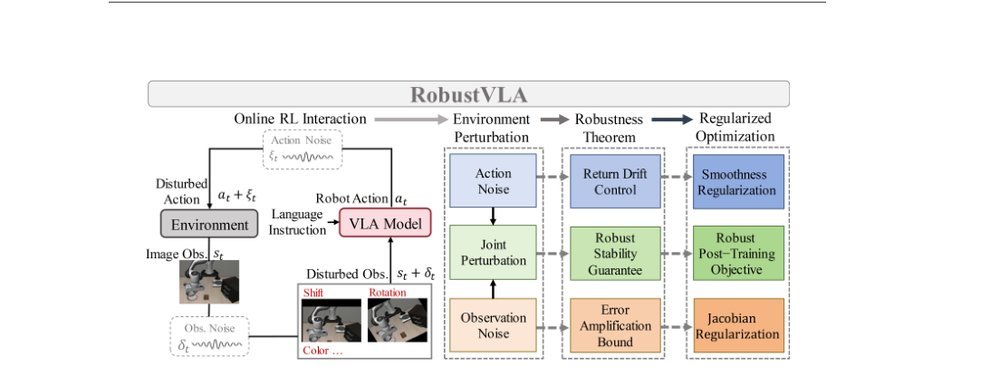
作者:Hongyin Zhang, Shuo Zhang, Junxi Jin, Qixin Zeng, Runze Li, Donglin Wang · 单位:Westlake University · 会议/期刊:arXiv · 日期:2025-11-03 · 来源:Low-Level Learning-Based Action Modelling / Input Modelling / 2D Vision Language Action Models with Robustness / Attack