主页
返回索引
CoRL 2025 / Poster #132
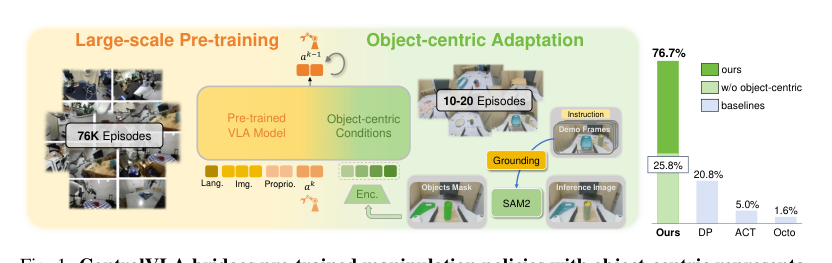
ControlVLA: Few-shot Object-centric Adaptation for Pre-trained Vision-Language-Action Models
Poster
VLA/VLM
新标签打开 AlphaXiv
AlphaXiv 中文概览(可滚动查看)