精读笔记
Problem Setting
这篇论文实际解决的是:在在线RL中,如何有效利用真实场景里海量存在但难以直接使用的非精选离线数据——它们无奖励标签、质量参差、且来自多种具身。真正的困难点不是预训练一个世界模型,而是当把这个模型微调到下游任务时,离线预训练分布与在线交互分布之间的偏移会导致模型失效、策略难以受益。以前的方法要么卡在对奖励标签和任务特定结构的依赖上(传统Offline-to-Online RL),要么卡在“只预训练、不维护”——预训练时用了大数据,微调时却丢弃,导致世界模型在硬探索任务中因在线数据狭窄而灾难性遗忘。这个任务的关键矛盾是:非精选数据的“通用性”和“无结构性”在预训练阶段是资产,在微调阶段却成了分布偏移的祸根。
Motivation
作者发现,已有两条路线都不够用:一是离线RL和Offline-to-Online RL(如MOTO、RLPD),它们假设离线数据带有奖励且与目标任务对齐;二是世界模型/视觉表示预训练(如iVideoGPT、R3M),它们把非精选数据仅用于预训练,微调阶段直接丢弃。这种“预训练-丢弃”模式导致了一个反直觉现象:即使在大规模非精选数据上预训练了世界模型,朴素微调后在许多任务上相比scratch几乎没有提升。作者通过t-SNE可视化(图2) pinpoint 了根因:离线数据分布与早期在线数据分布存在显著偏移。因此,缺的不是更大的预训练数据集或更fancy的架构,而是能在微调阶段“重新调用”离线数据以锚定分布、防止遗忘并引导探索的机制。
Core Idea
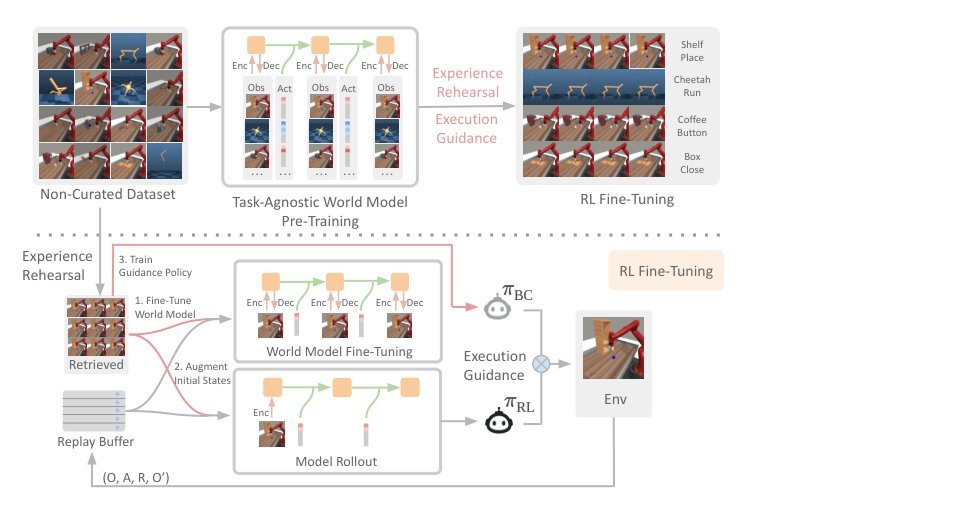
NCRL的核心思想是把非精选离线数据当成一个持续可用的、可检索的分布式记忆库,而不仅仅是一次性的预训练燃料。它重新组织了离线数据在在线学习环路中的信息流:在微调阶段,通过神经特征检索从海量跨任务数据中找到与当前任务相关的轨迹,将其重新注入世界模型的训练(Experience Rehearsal),以此对抗在线微调时的分布漂移和灾难性遗忘;同时,在这些检索到的数据上蒸馏出一个行为先验策略,在在线数据收集时以一定概率执行该先验(Execution Guidance),把智能体“拉”回世界模型高置信的区域。与prior的本质区别在于:它不是在世界模型架构上做文章(仍用标准RSSM),而是论证了“在非精选设定下,离线数据在微调阶段的正则化与引导价值,可能大于其在预训练阶段的表示价值”。它引入的inductive bias是:离线的、异构的、无奖励的数据可以通过检索和混合执行,被重新组织为针对当前任务的课程与约束。
Method
方法层面只保留两个真正必要的机制:
1. **Experience Rehearsal**:在微调每一步,用预训练编码器的特征距离,从大规模非精选离线数据中检索与当前在线缓冲区初始观测最相似的轨迹。它被混入世界模型的训练批次中。这解决的核心问题是灾难性遗忘和模型rollout初始分布的狭窄化——它相当于一个基于检索的参数正则化器,将模型锚定在预训练域的相关子空间,同时让想象轨迹的初始状态p0(s)覆盖离线数据已探索过的相关区域,而非仅限于在线策略当前能到达的局部。
2. **Execution Guidance**:在检索到的轨迹上训一个BC先验策略,以线性退火schedule决定是否在episode的随机时段执行该先验。它解决的核心问题是硬探索和分布外世界模型误差的累积——在RL策略尚未可靠时,用离线先验收集数据,确保在线分布不会过快偏离预训练域,从而维持世界模型对策略更新的信用分配准确性。
两者缺一不可:Rehearsal解决世界模型“内部”的表示漂移,Guidance解决数据收集“外部”的分布漂移。
Key Insight / Why It Works
方法真正有效的原因在于它同时耦合地解决了世界模型微调中的**分布偏移**与**探索死锁**。Experience Rehearsal不是简单的“多看了点数据”,而是提供了一个稀疏激活的外部记忆约束:当在线数据分布极其狭窄(如硬探索任务早期)时,它阻止了世界模型参数被这些有偏样本过度改写。这本质上是一种隐式的记忆保持机制,使得世界模型的隐空间在微调过程中不被带偏。Execution Guidance则通过混合策略确保在线收集的数据分布始终与离线预训练域有一定重叠,从而维持了世界模型的预测有效性,避免策略梯度在模型幻觉上更新。
从消融(图6)可以做出一个直接的技术判断:**在多数困难任务上,纯世界模型预训练(P)本身几乎不产生增益,甚至不如scratch**;只有当加上Experience Rehearsal(ER)和Execution Guidance(G)后,预训练才体现出价值。这意味着论文标题中“Guiding World Models”比“Learning World Models”更诚实——核心贡献不是预训练了一个多强的世界模型,而是设计了一套引导机制,让这个世界模型在微调时不被遗忘、不被偏移。因此,性能提升的主要来源应归因于**检索式正则化 + 先验引导探索**,而非模型架构scaling或预训练数据coverage本身。另一方面,这也暗示该方法在困难任务上的早期表现可能严重依赖BC先验的模仿学习增益,RL部分更像是对先验的渐进式修正,文中并未严格剥离这两者。
Relation To Prior Work
与iVideoGPT、Seo et al.等世界模型预训练路线相比,NCRL不追求新架构(仍用RSSM),而是把创新点完全放在fine-tuning机制;与JSRL-BC相比,虽然都用了BC先验+混合策略,但NCRL是model-based,且通过检索机制处理非精选、多具身数据,JSRL-BC则依赖任务特定数据且仅在episode开头使用先验;与RLPD、ExPLORe等Offline-to-Online方法相比,NCRL不需要奖励标签,也不直接把离线数据塞进Q-function训练,而是通过世界模型+检索的方式利用数据。
它属于“预训练-微调”技术谱系,但关键的不同在于:**它把离线数据的生命周期从预训练延长到了微调阶段**。很多看似新的东西其实是已有思想的重组:检索式replay类似于Episodic Memory在RL中的应用,混合执行类似于Conservative Policy Iteration/JSRL,但把它们同时用在“世界模型微调”这个特定场景下,且针对非精选、无奖励、多具身设定,是实质创新。它真正新增的信息是:在non-curated设定下,离线数据对防止模型遗忘的价值可能大于其作为静态预训练语料的价值。
Dataset / Evaluation
评估覆盖72个视觉运动任务(Meta-World 50 + DMControl 22),6种具身,像素输入,这在同类工作中属于较广的覆盖。离线数据集由同域内的无奖励数据构成:DMControl为好奇心驱动探索策略收集的10k轨迹(5具身),Meta-World为加噪TDMPC-v2策略收集的50k轨迹(50任务,混合质量)。
但evaluation对核心claim的支持存在局限:论文主张利用“abundant non-curated data”,但实际使用的数据仍是**in-domain**(与下游任务共享相同模拟环境和具身),并非真正的跨域野外数据(如真实机器人跨实验室采集的Open X-Embodiment)。因此,benchmark验证的更像是“同域内跨任务迁移”,而非标题暗示的广义“non-curated”数据利用。此外,所有实验均在模拟器中进行,没有真实世界验证,离线的“混合质量”在真机噪声下的表现未知。
Limitation
方法成立的一个重要隐含前提是:离线数据集中必须存在与下游任务“足够接近”的轨迹,以保证基于初始观测特征距离的检索有效。若离线数据与目标任务真正跨域,检索机制可能失效,文中未充分论证此边界条件。
增益归因不够清晰:在困难任务上,Execution Guidance提供的BC先验策略可能承担了早期学习的主要工作,性能提升可能部分来自“在相关子集上做模仿学习”,而非世界模型带来的长期推理或RL探索优势。文中未设计实验严格剥离“检索+BC”与“世界模型预训练”各自的边际贡献。
Scalability方面,RSSM的RNN架构在处理更长程、更高维任务时可能遇到瓶颈;且随着离线数据量进一步增大,基于Faiss的检索与持续rehearsal在内存和计算上的开销未被讨论。
此外,世界模型的“想象展开”能力可能被高估:它的长期预测质量严重依赖Experience Rehearsal扩充的初始状态分布,这意味着模型可能主要在离线数据已覆盖的状态空间内做插值,而非形成真正的长期推理能力。
Takeaway
- 1. **微调阶段的分布偏移是世界模型样本效率的隐形杀手**。
- 单纯扩大预训练数据量或模型尺寸,而不处理fine-tuning时的分布鸿沟,收益可能极其有限(iVideoGPT的困境)。
- 这个insight对任何走“预训练-微调”路线的机器人学习工作都适用。
- 2. **检索式经验回放是一个可迁移的机制设计**。
一句话总结
NCRL识别了世界模型从非精选数据预训练后在线微调的分布偏移瓶颈,通过检索式经验回放与执行引导机制将离线数据的利用延伸至微调阶段,证明了即使在标准RSSM架构下,充分消化in-domain非精选数据也能在72个视觉运动任务上实现样本效率的显著提升,但其核心增益更可能来自微调阶段的检索正则化与先验引导,而非世界模型本身。