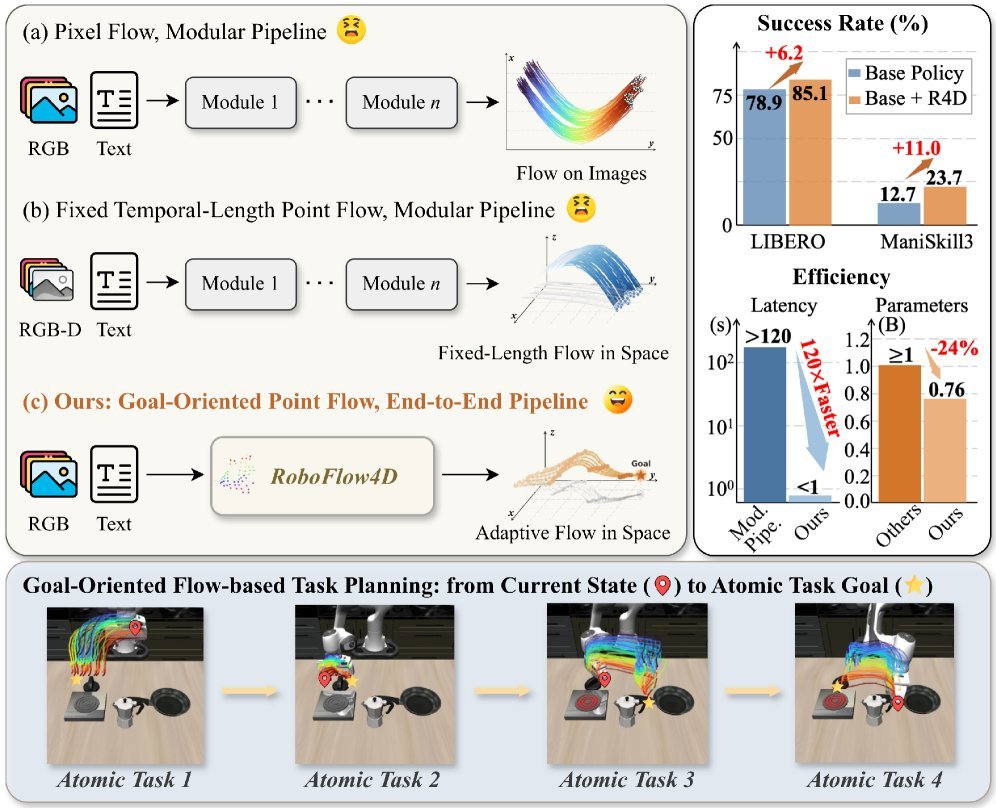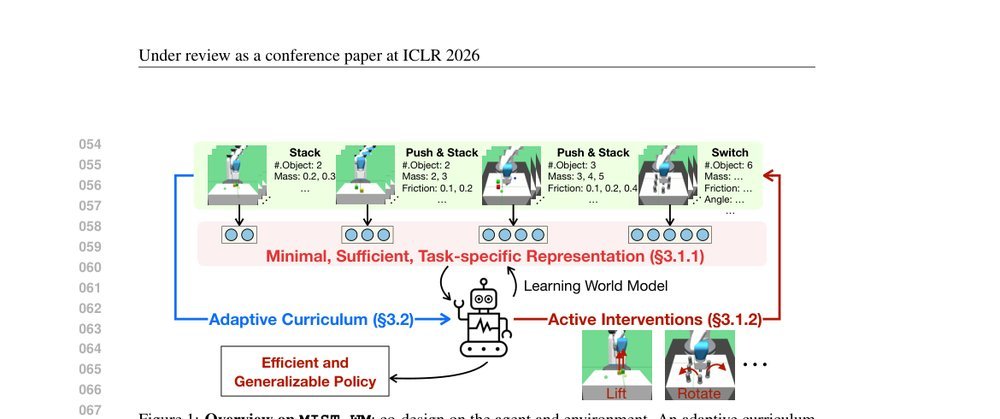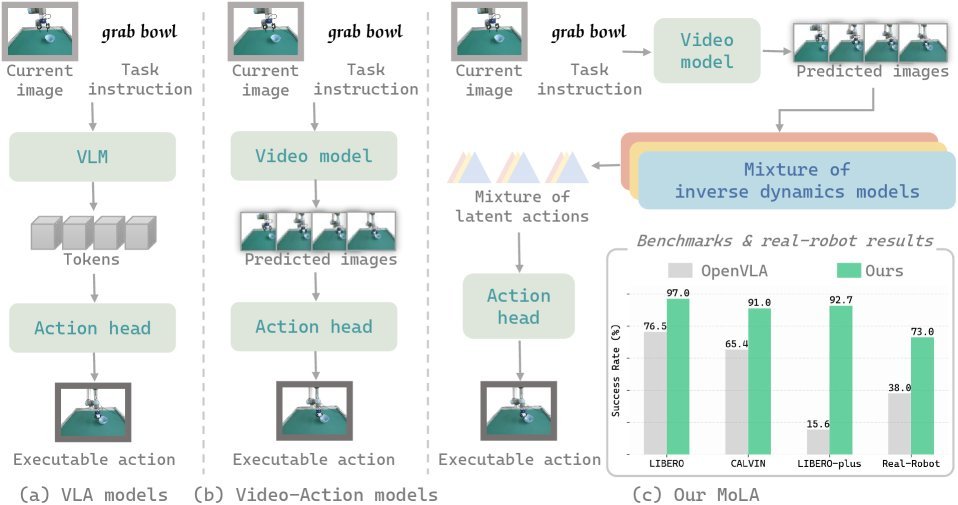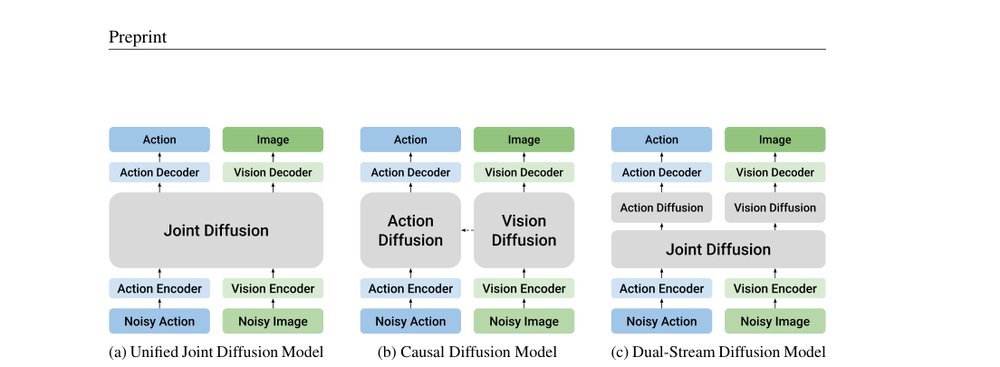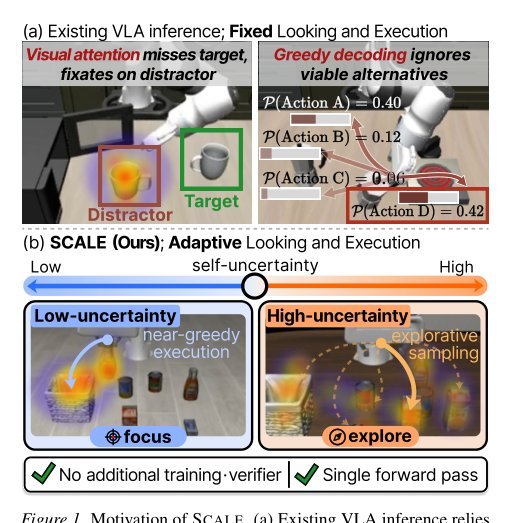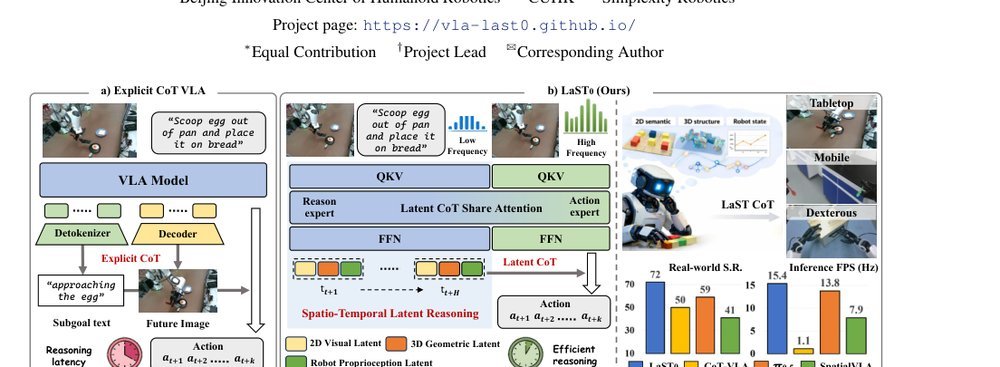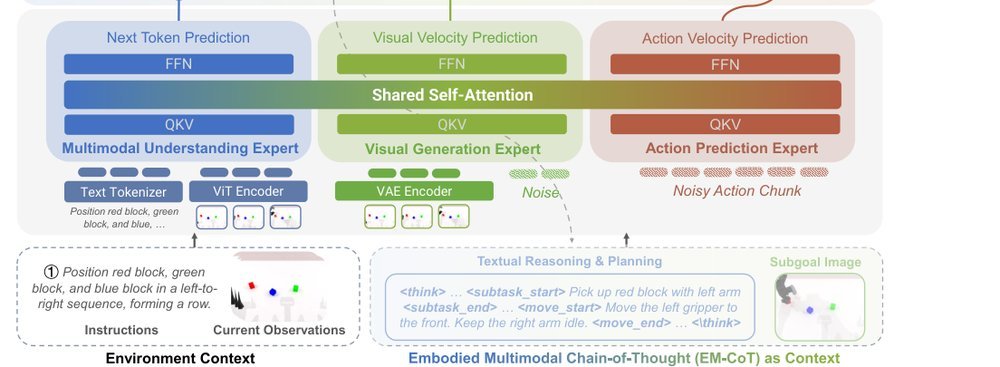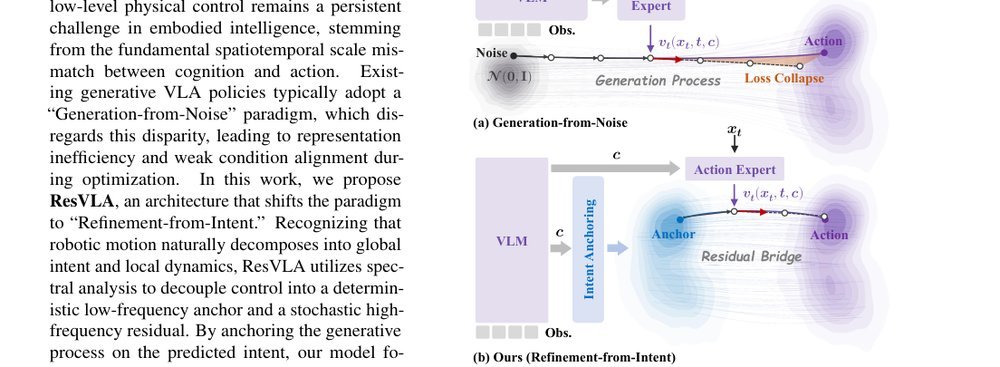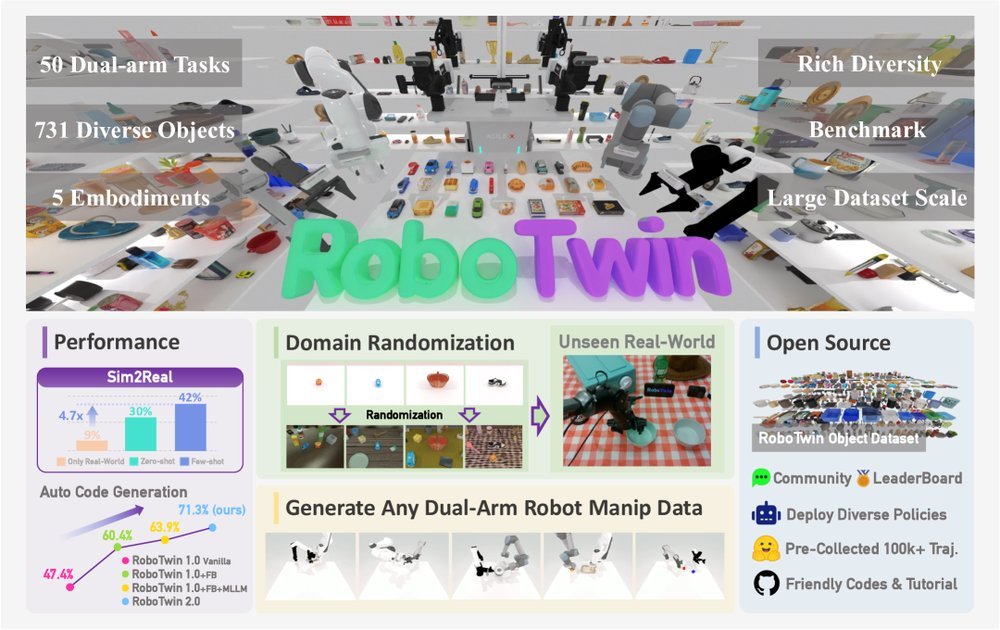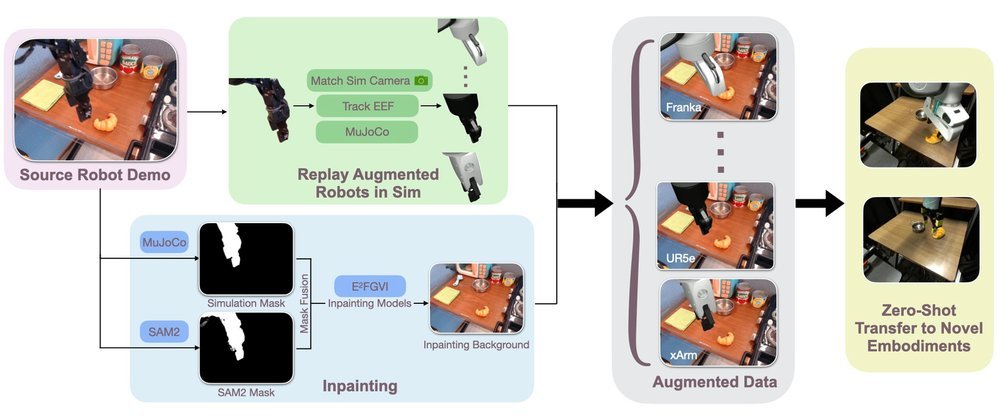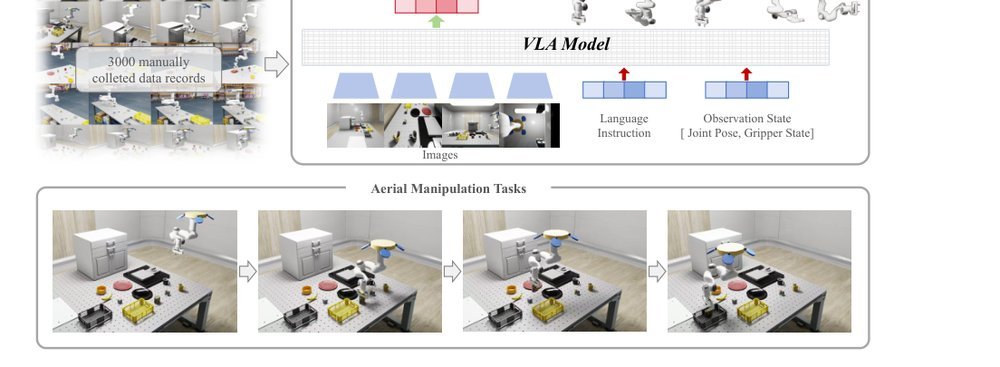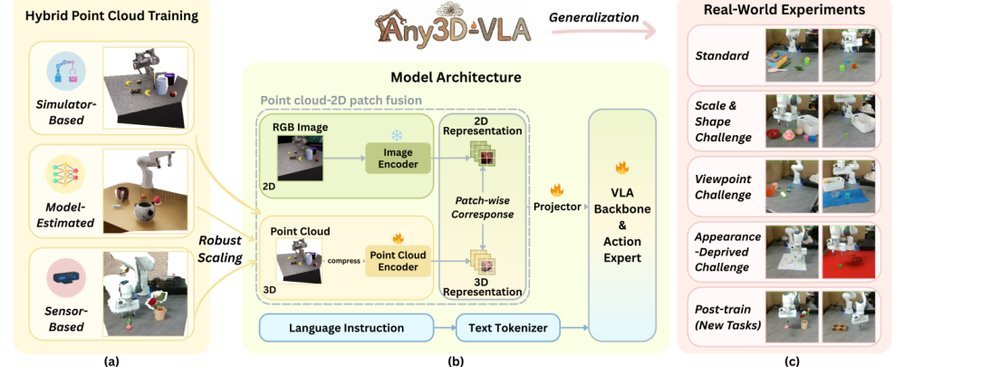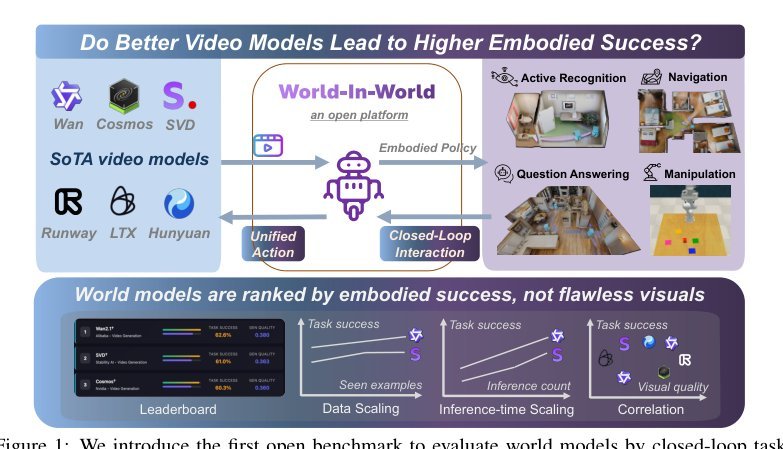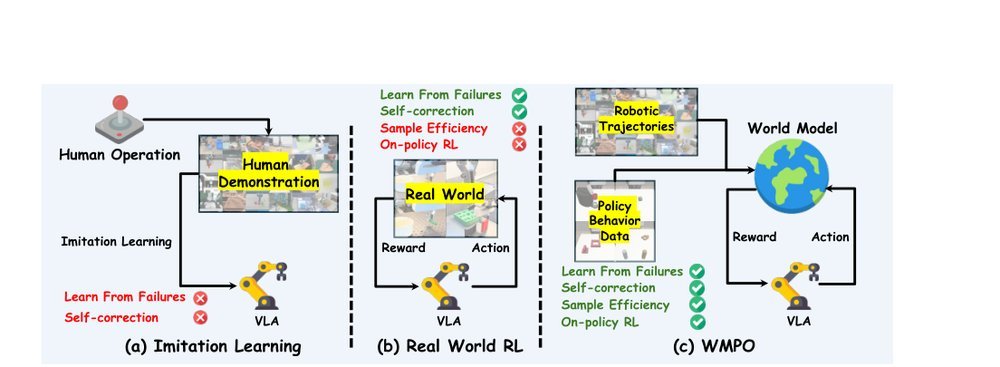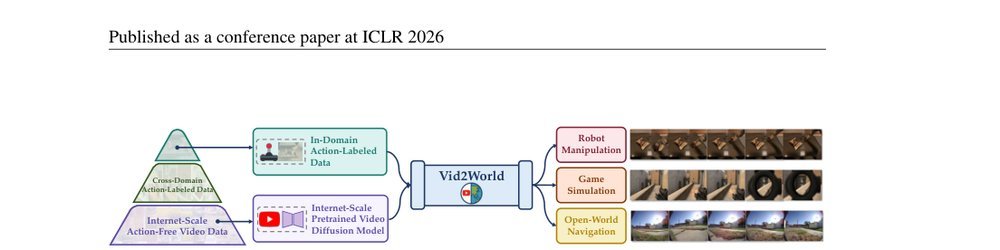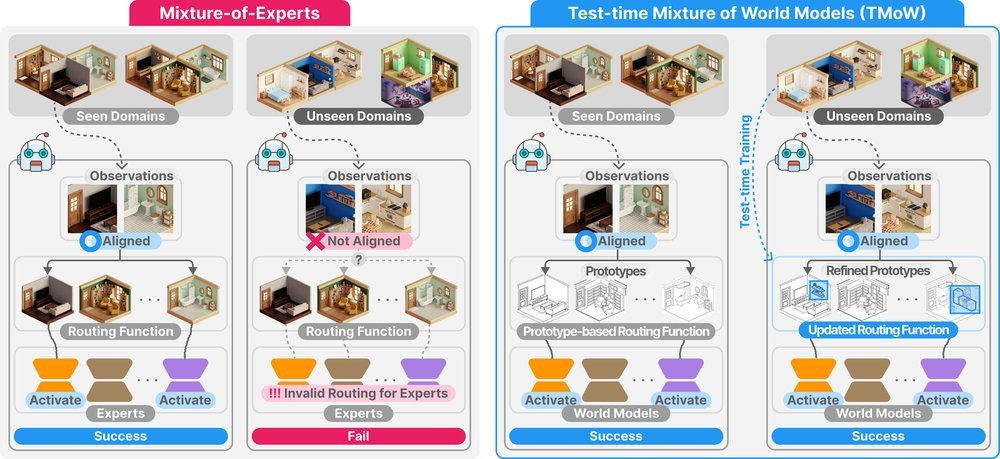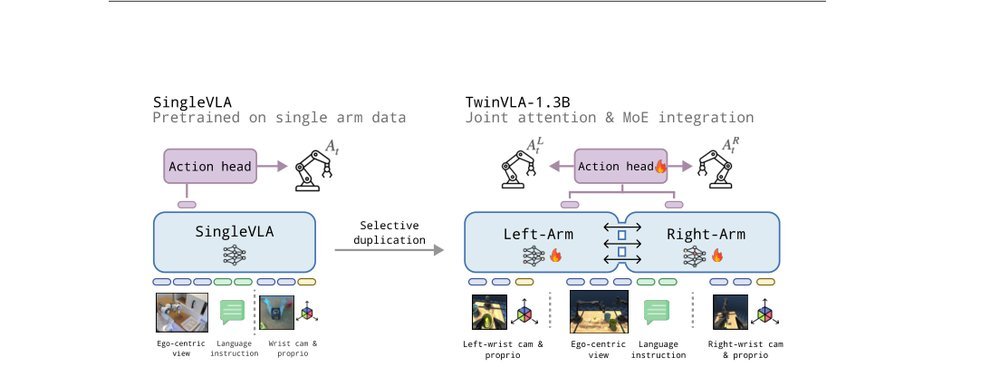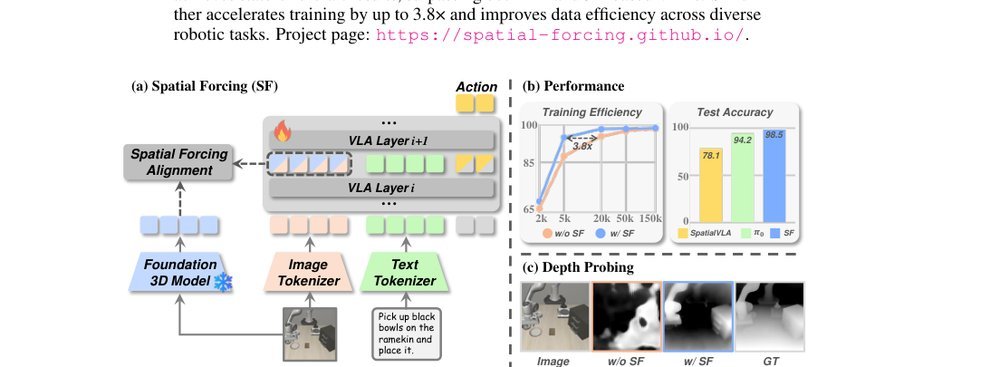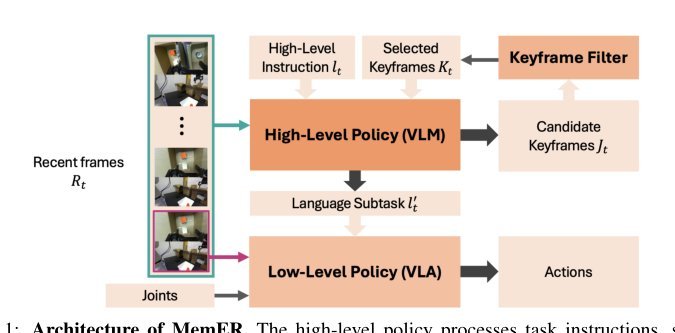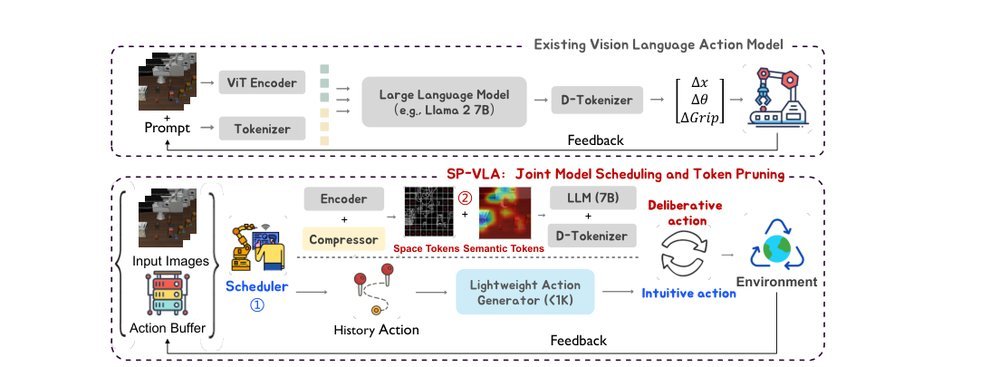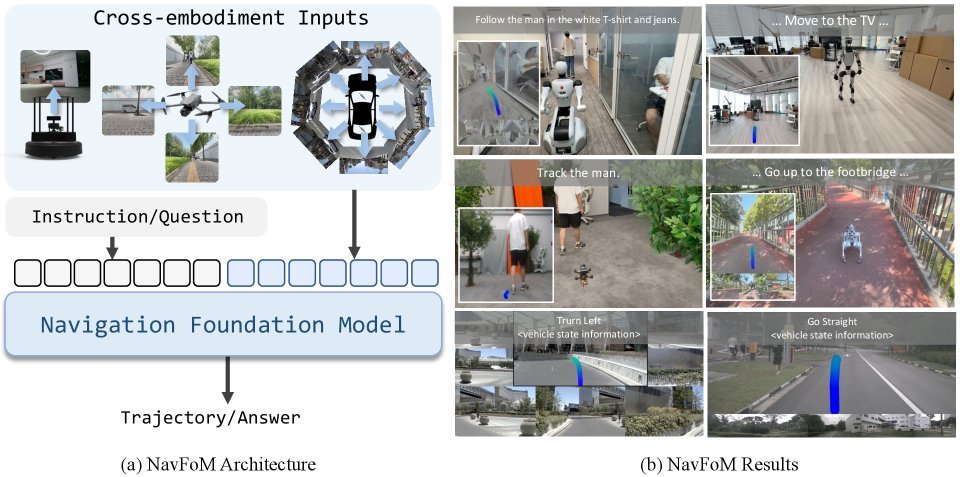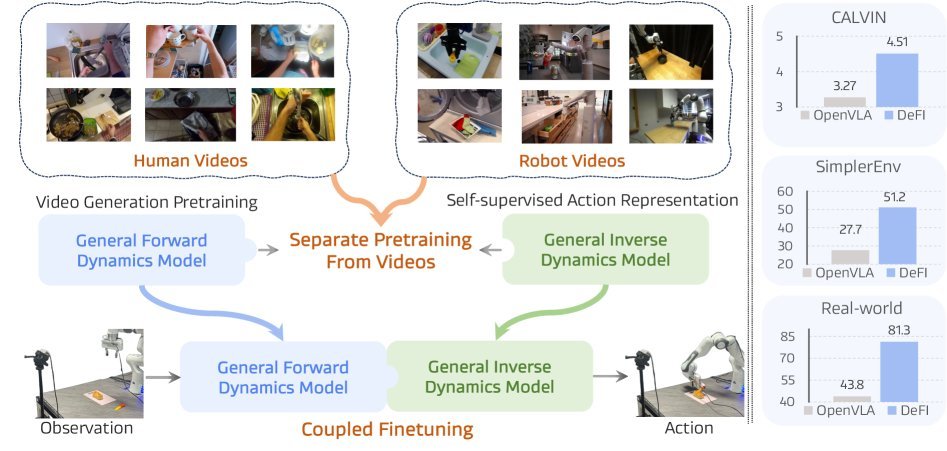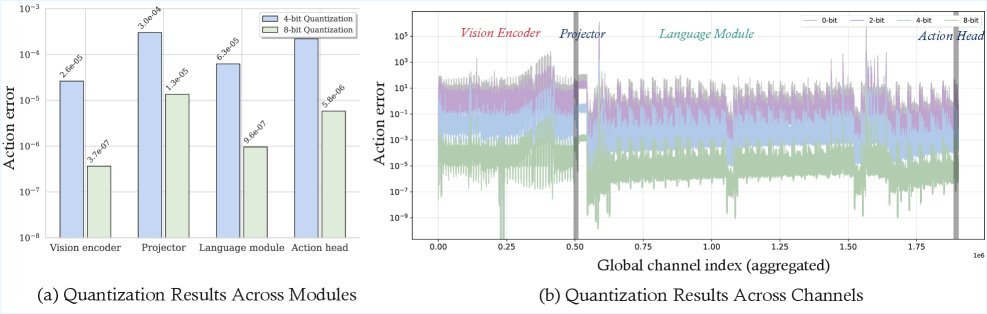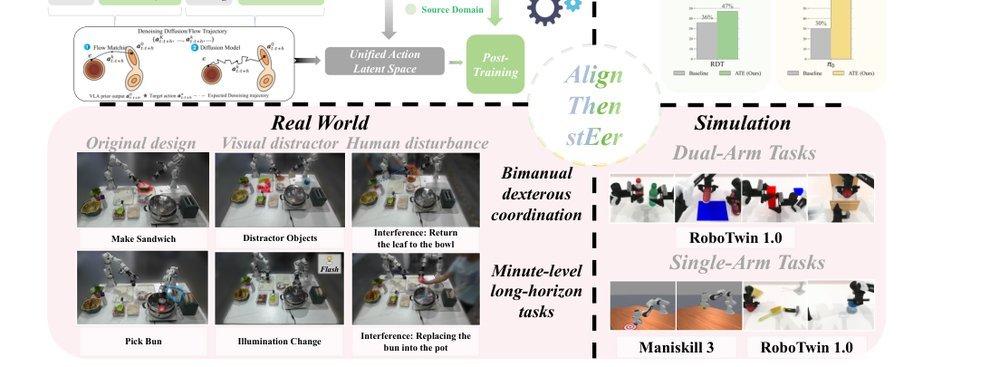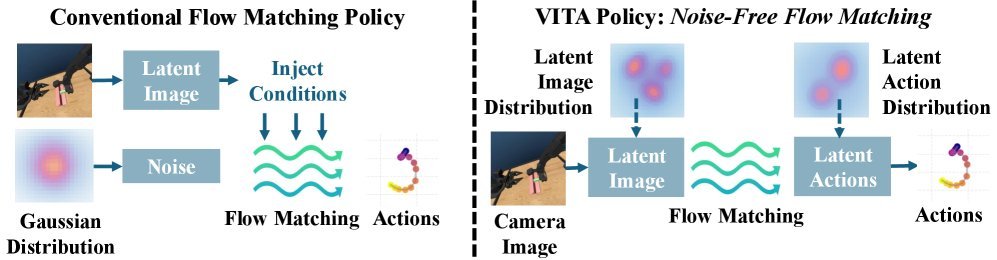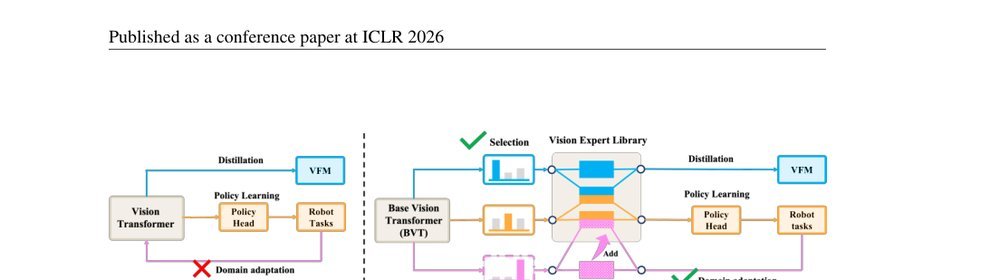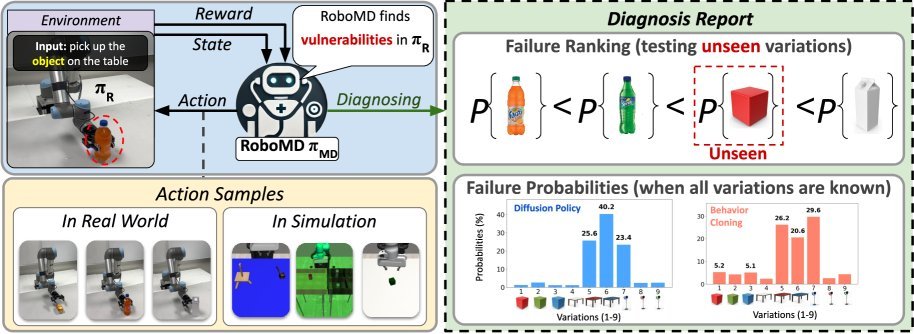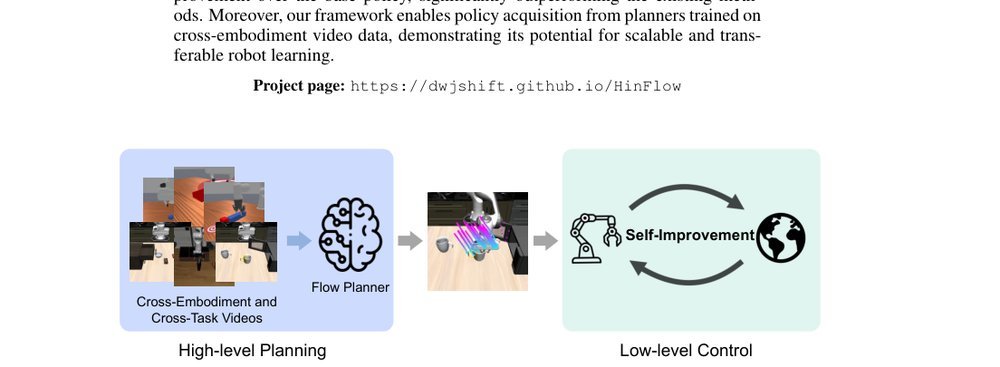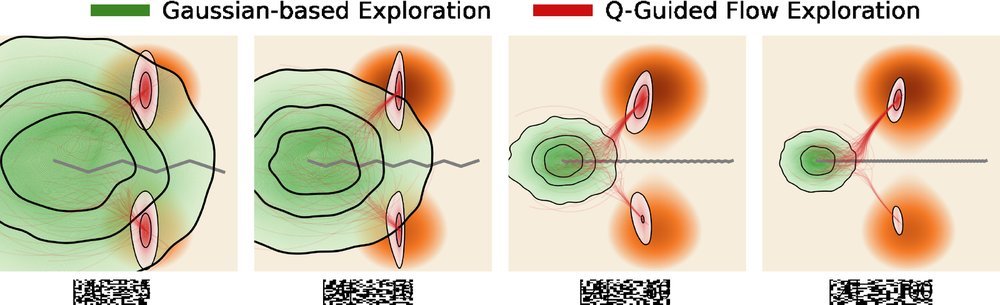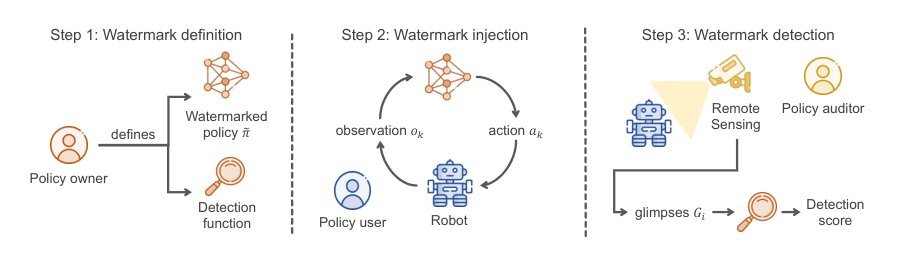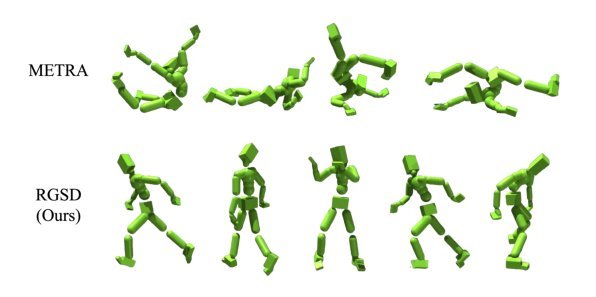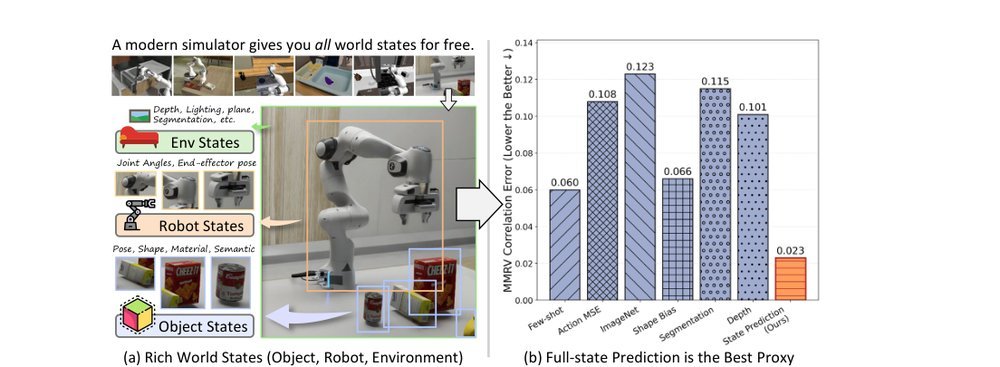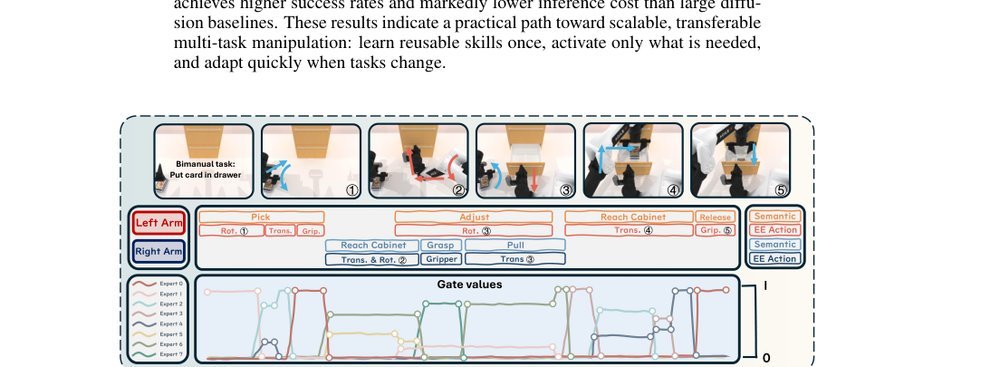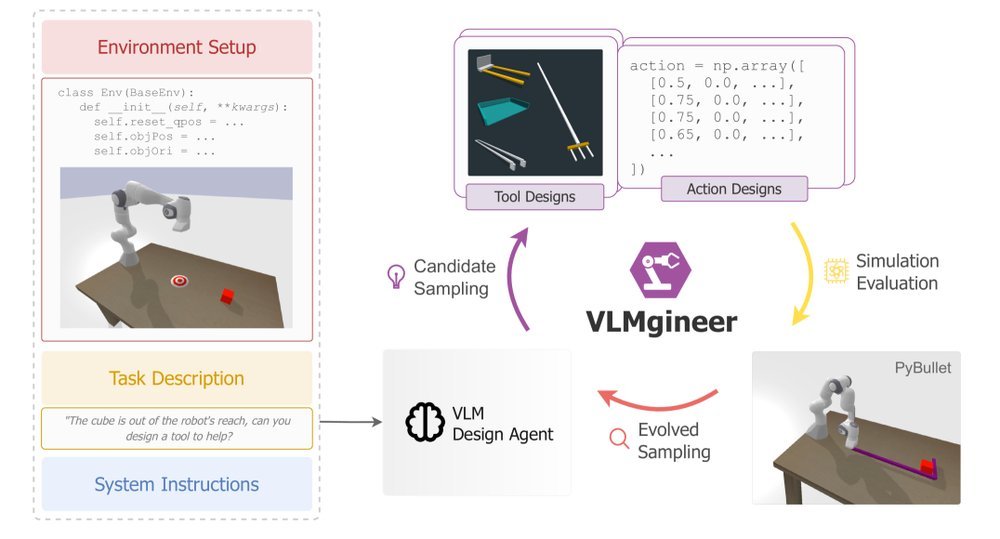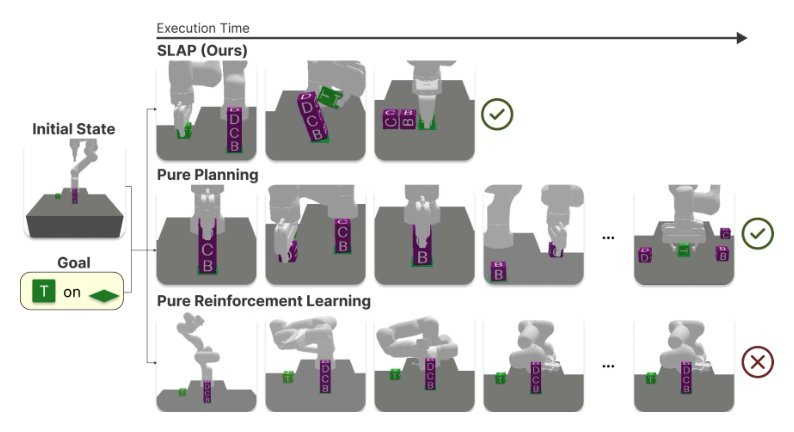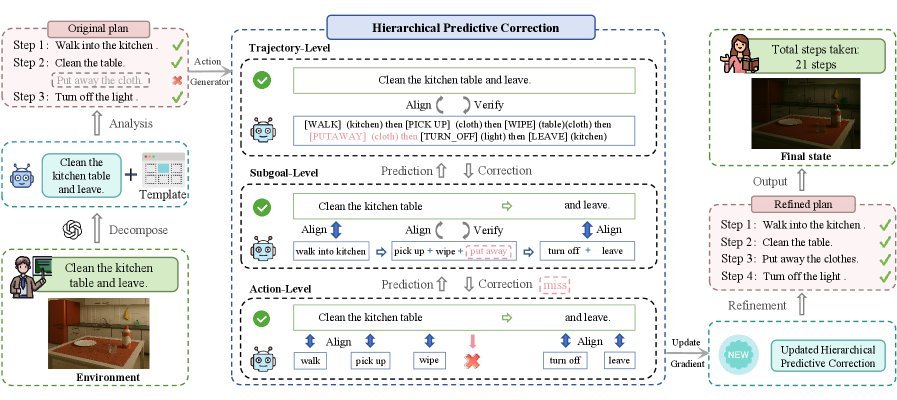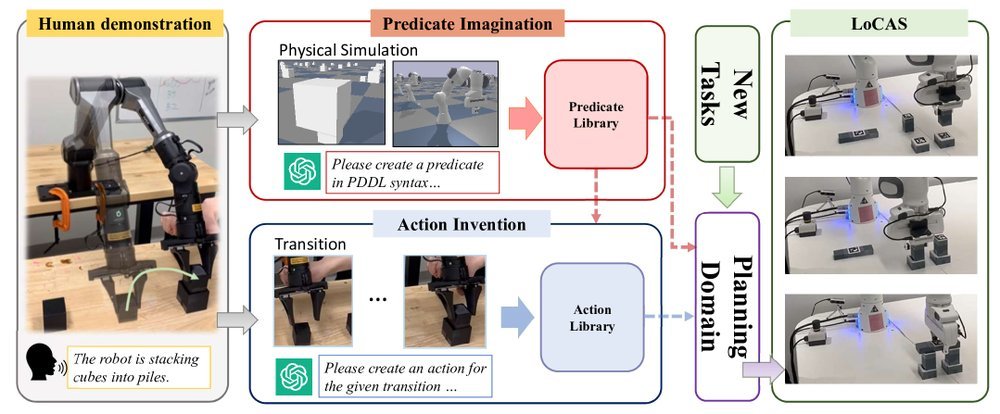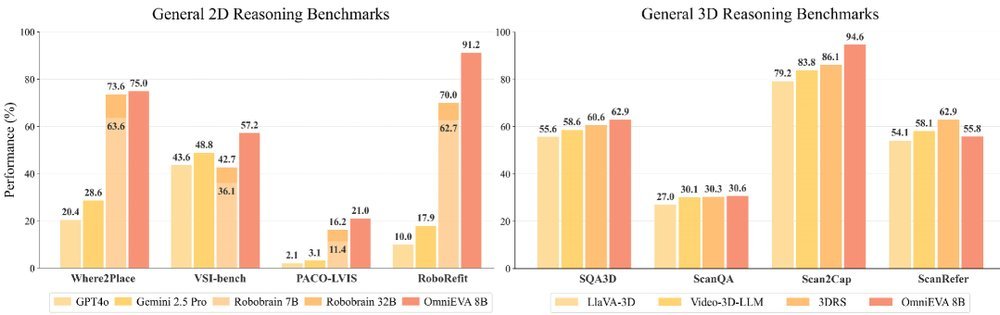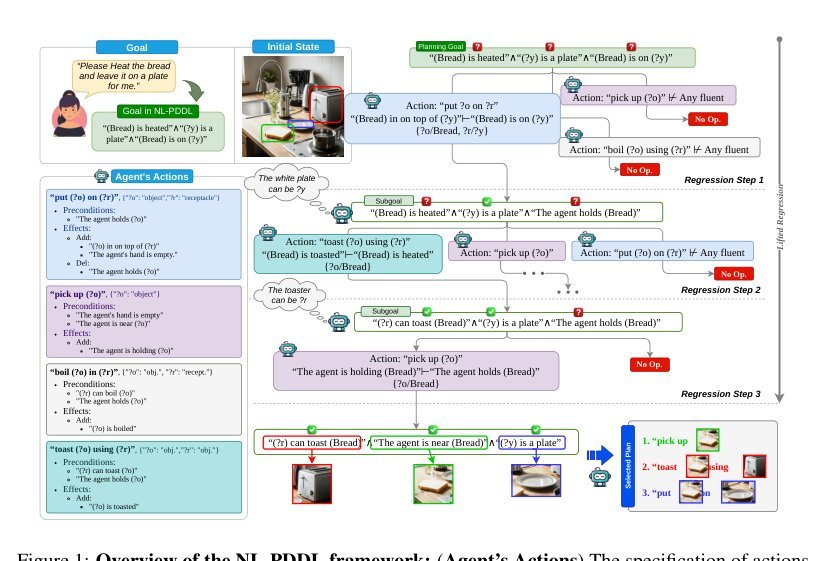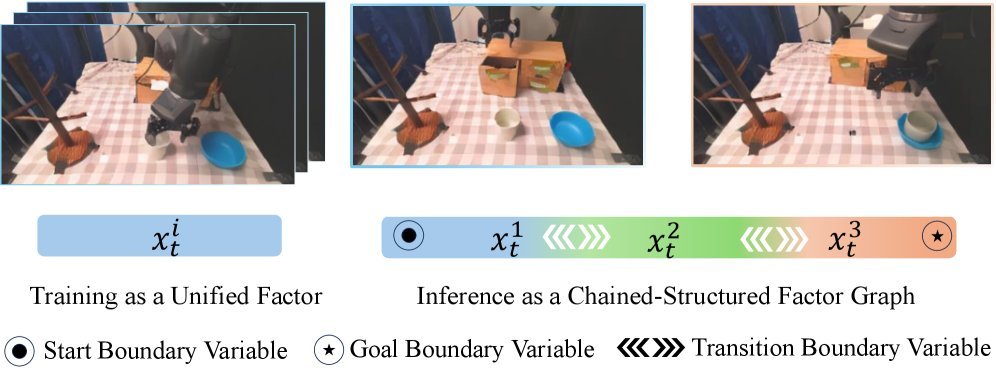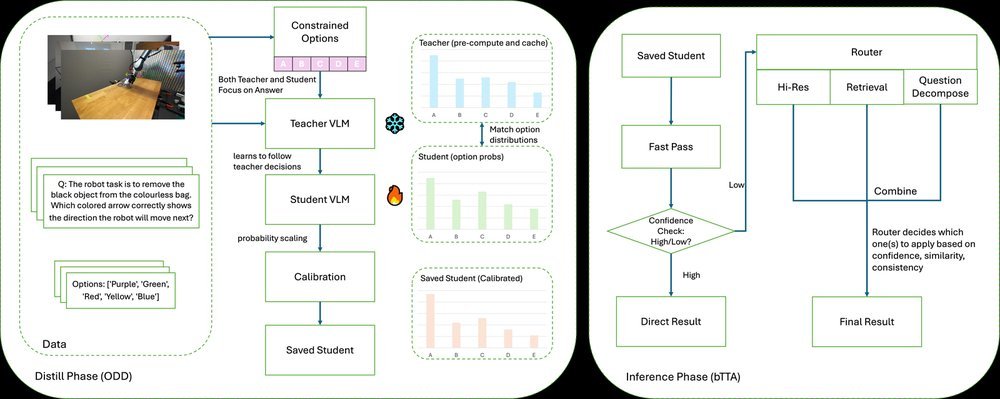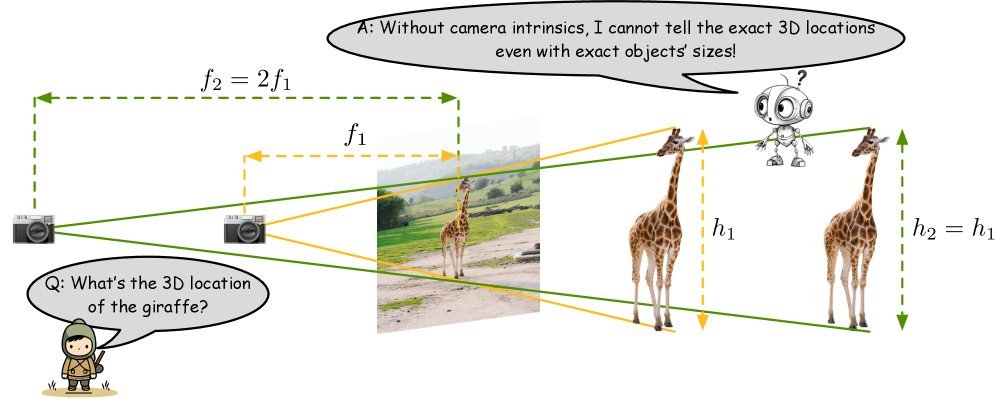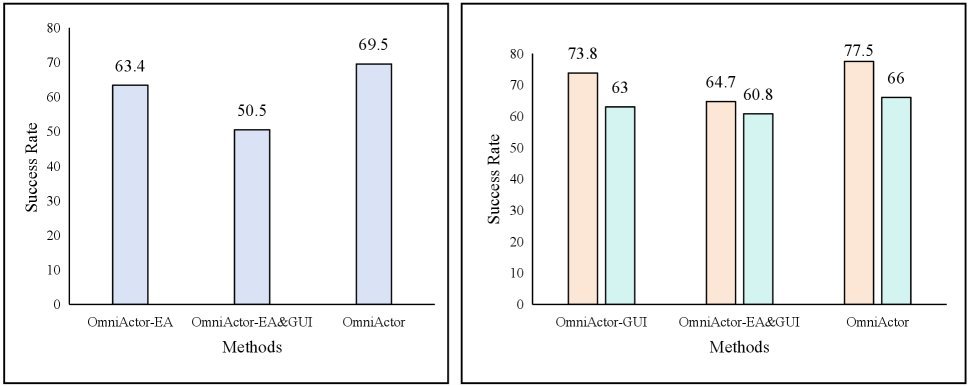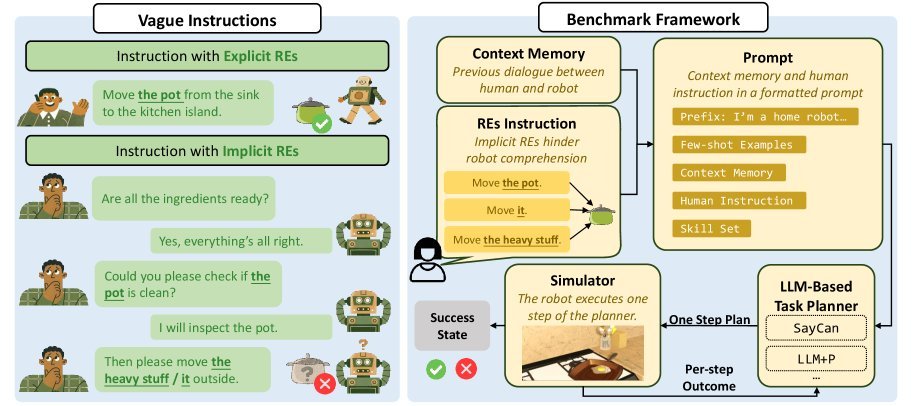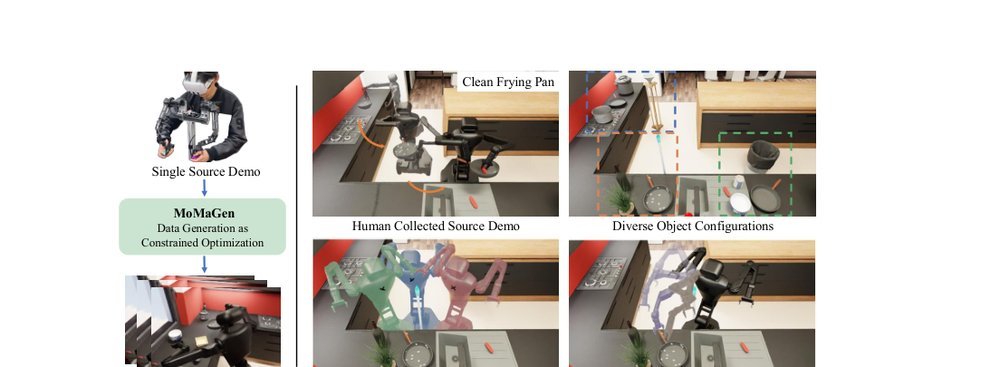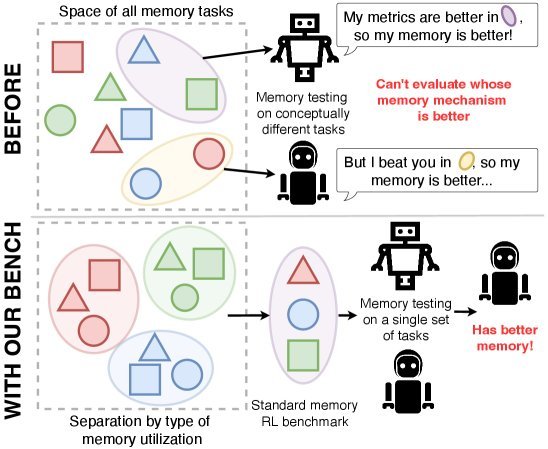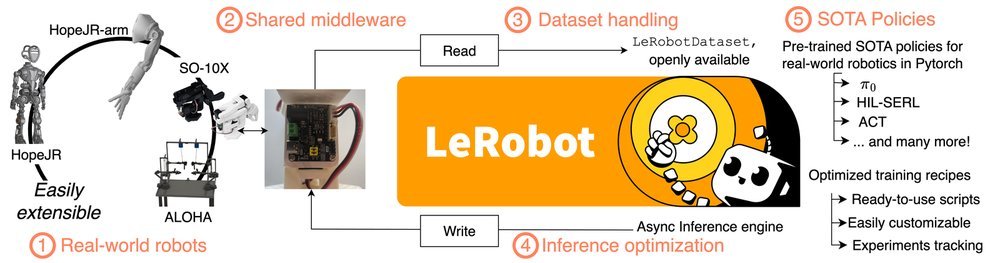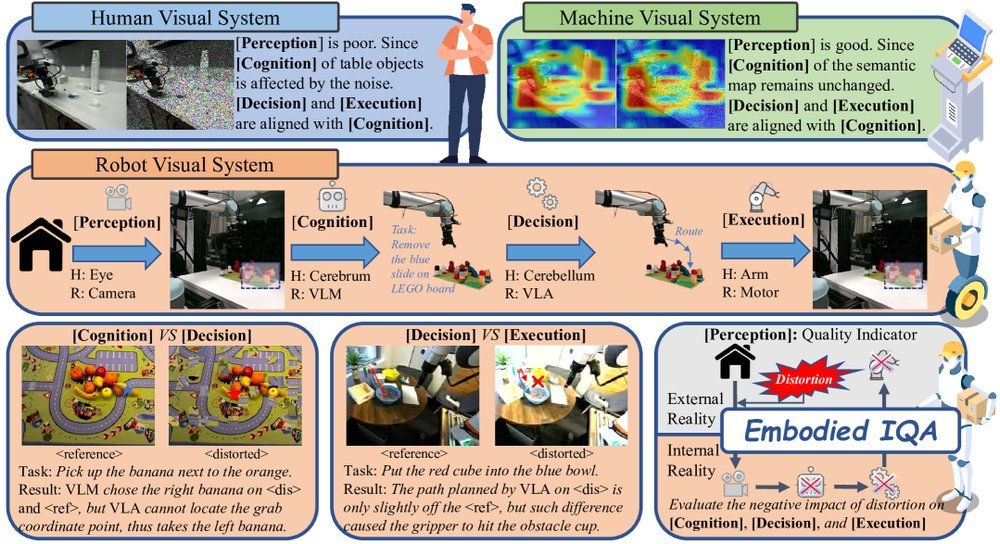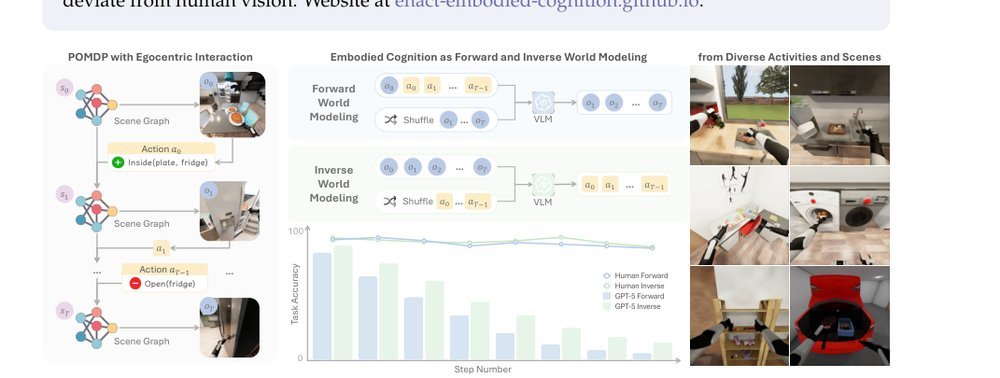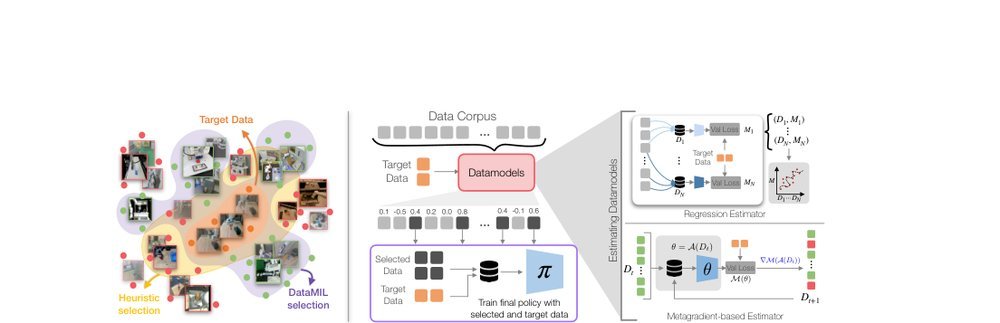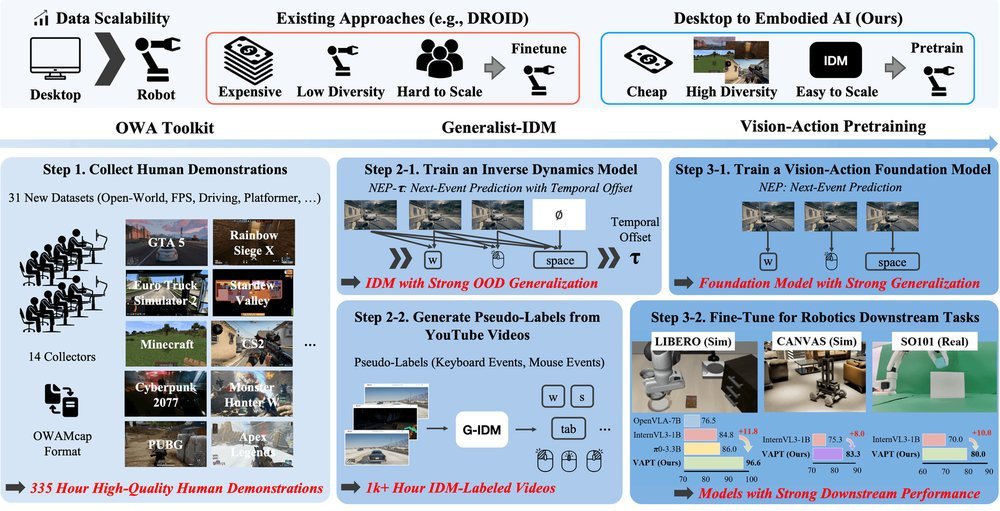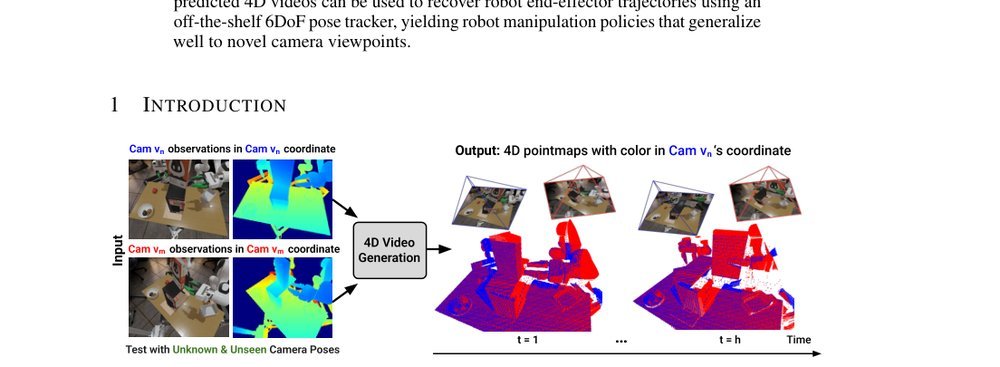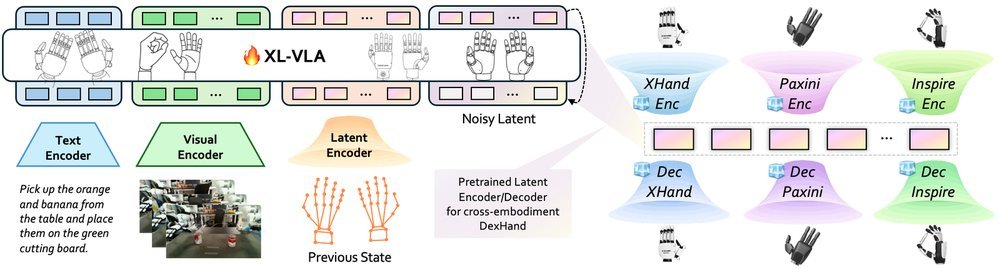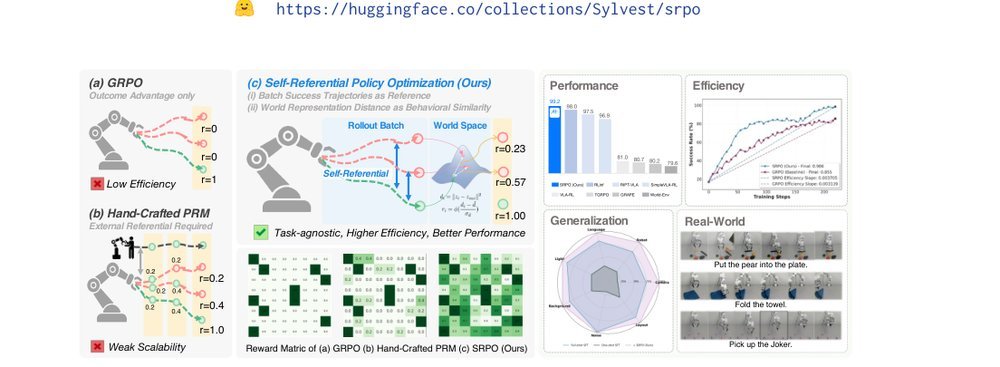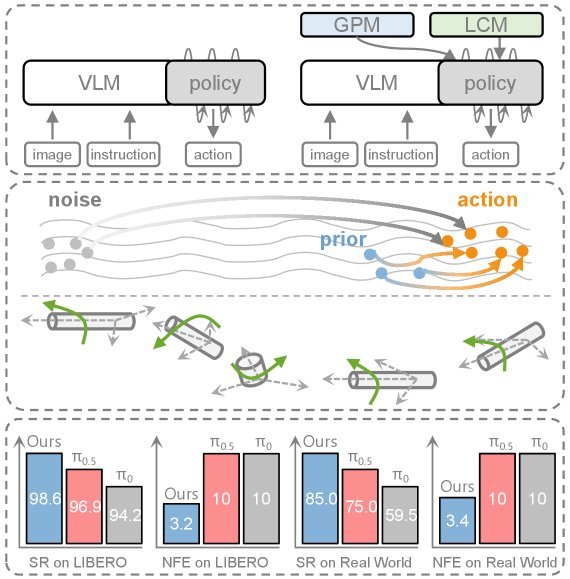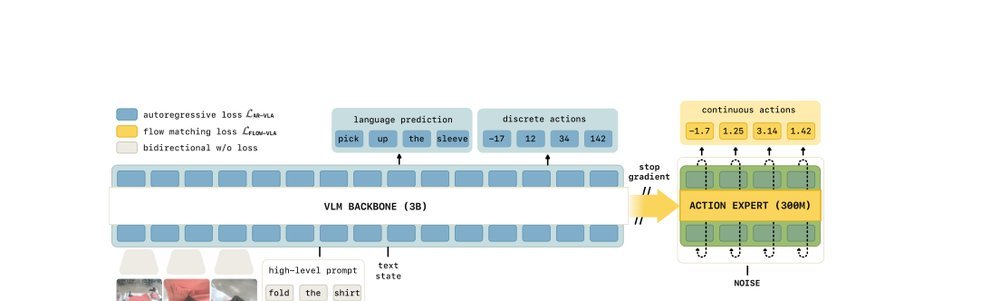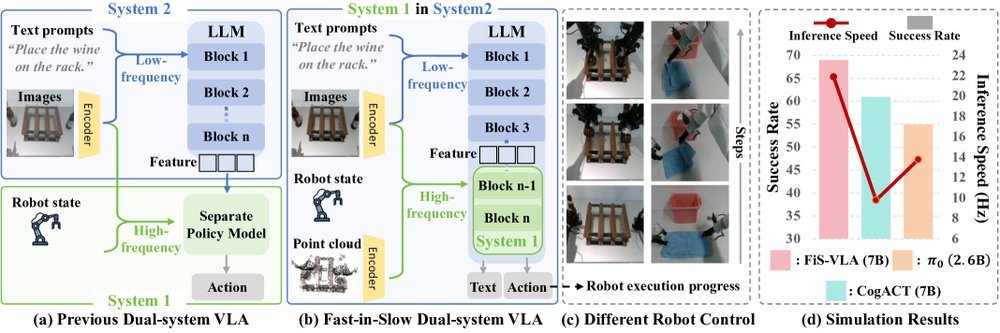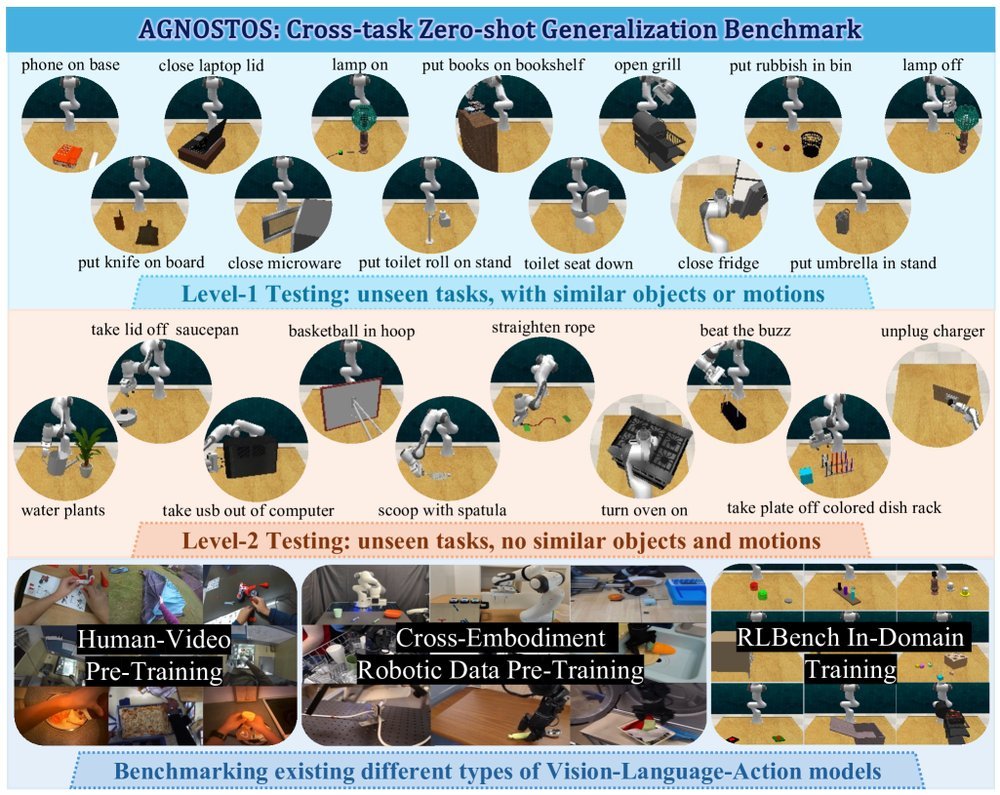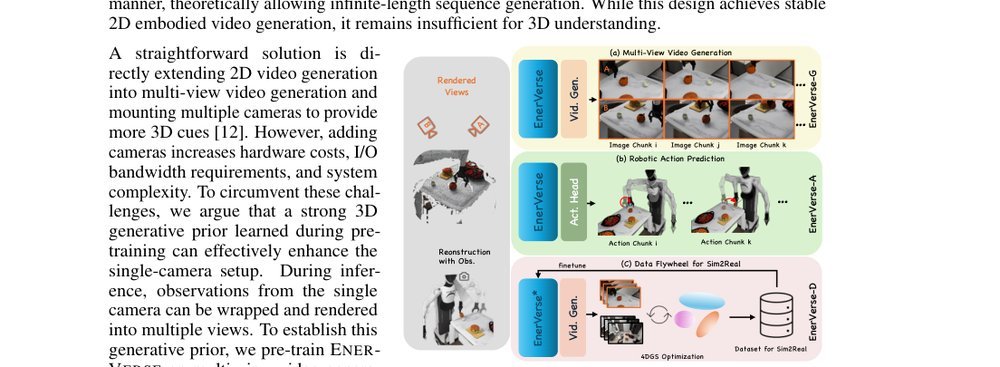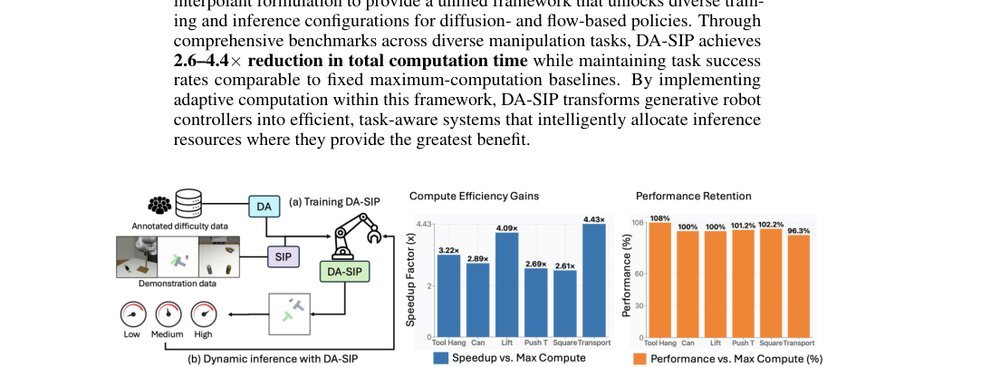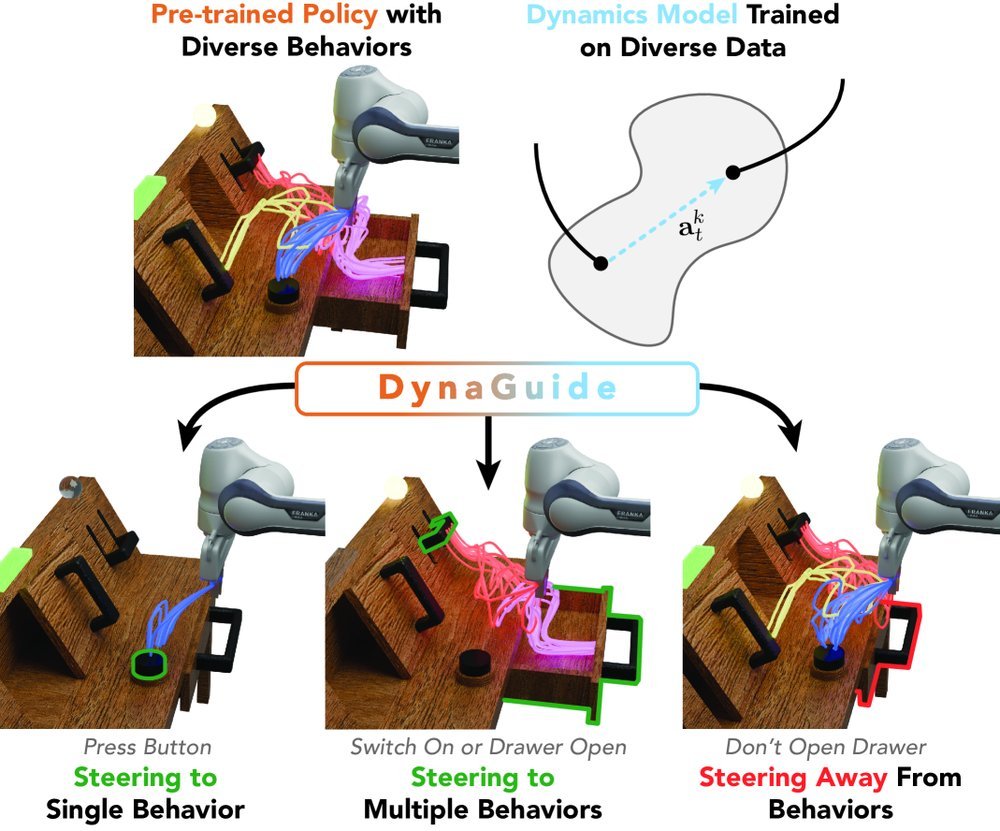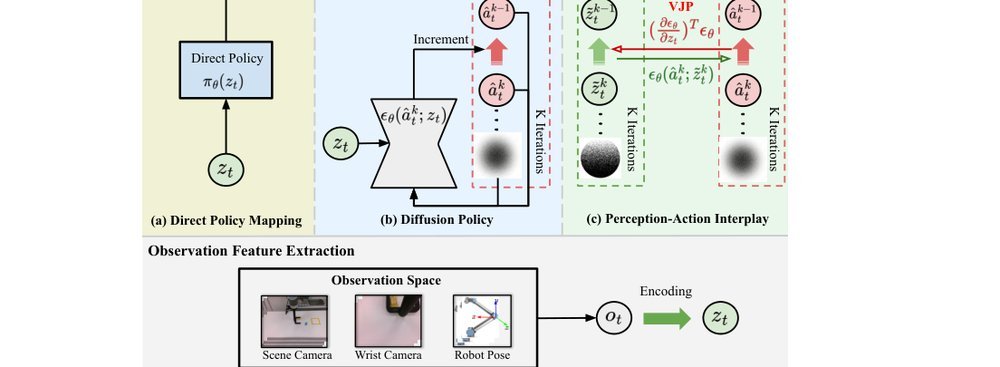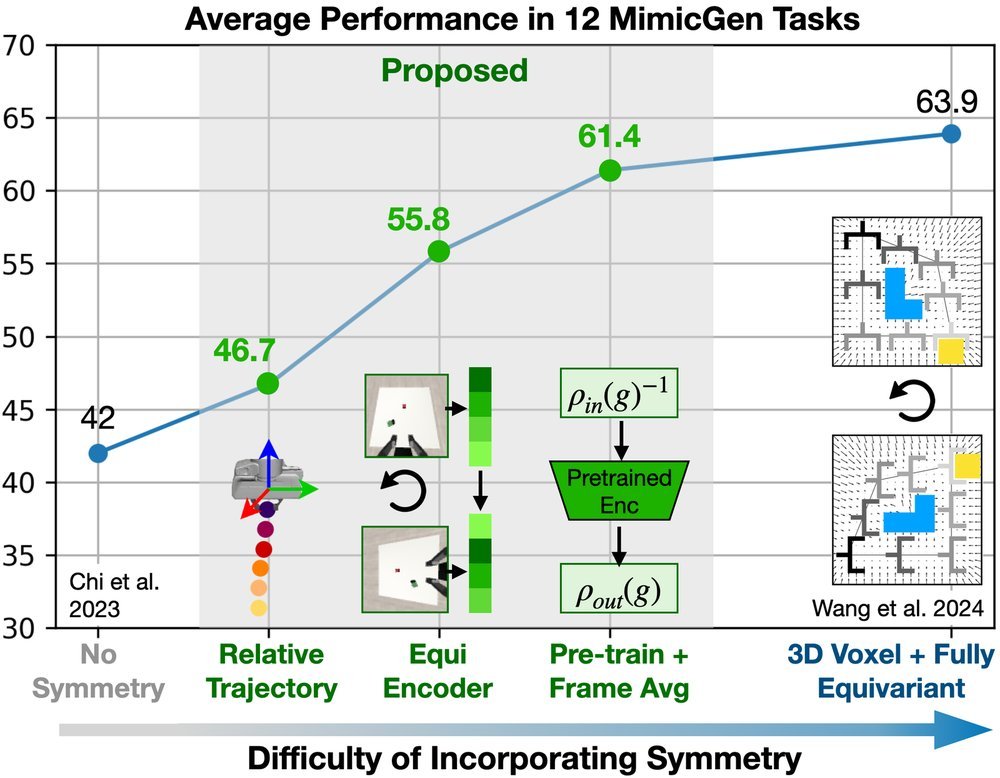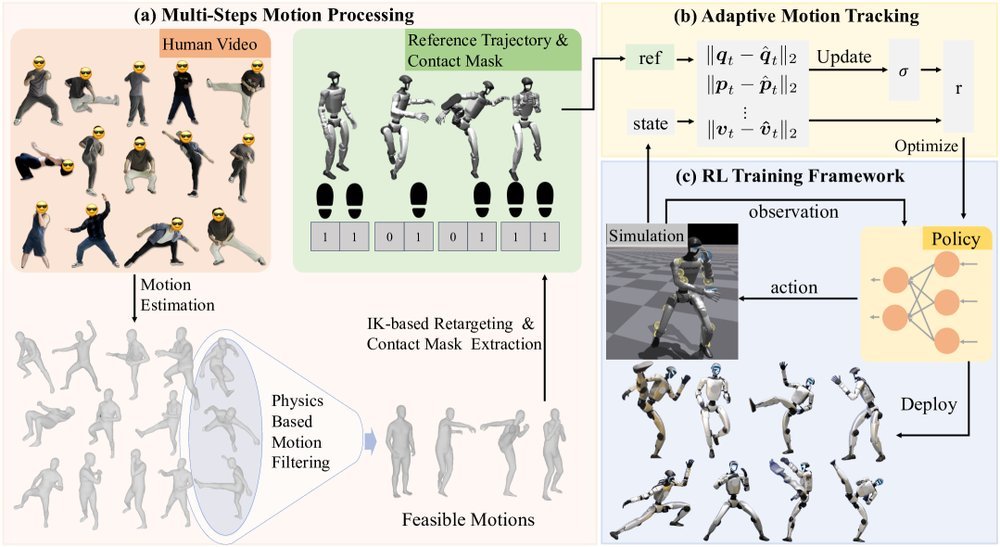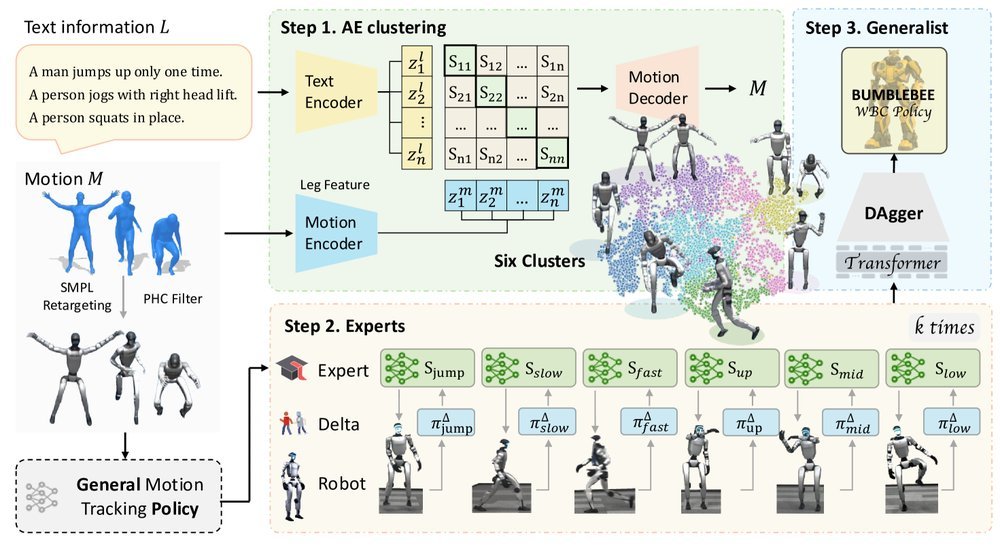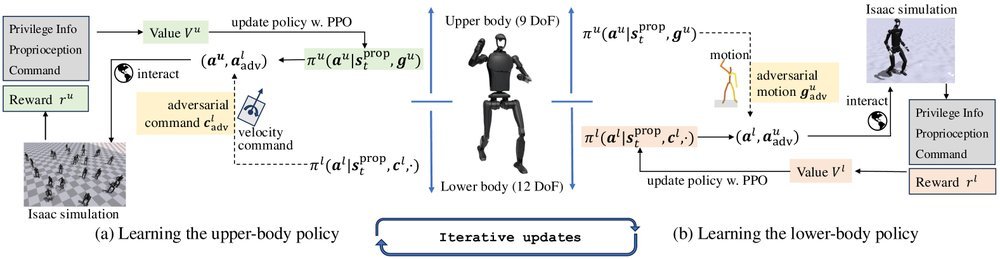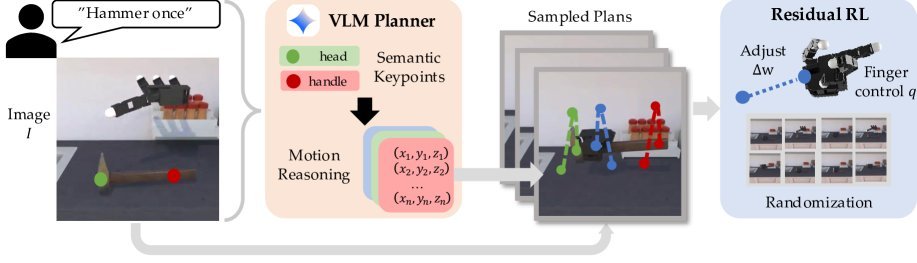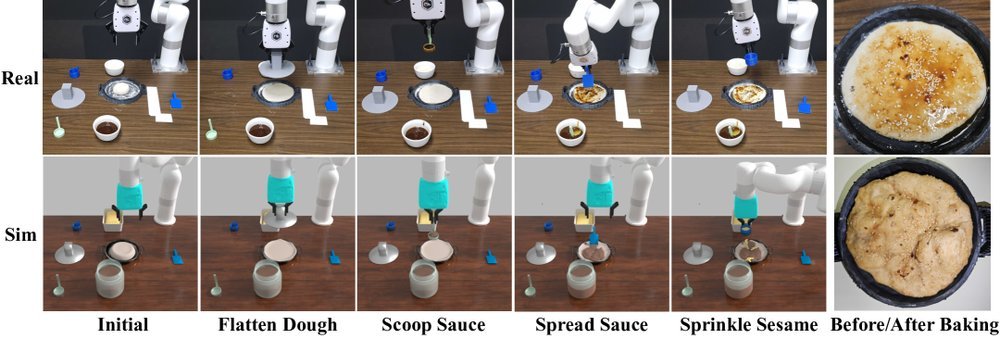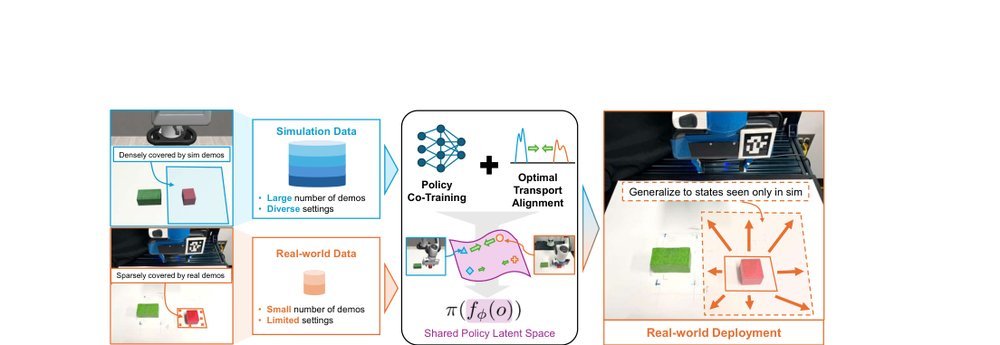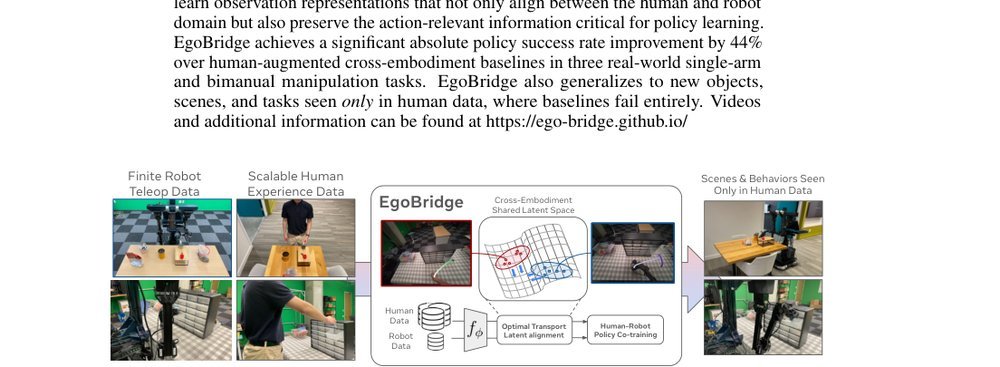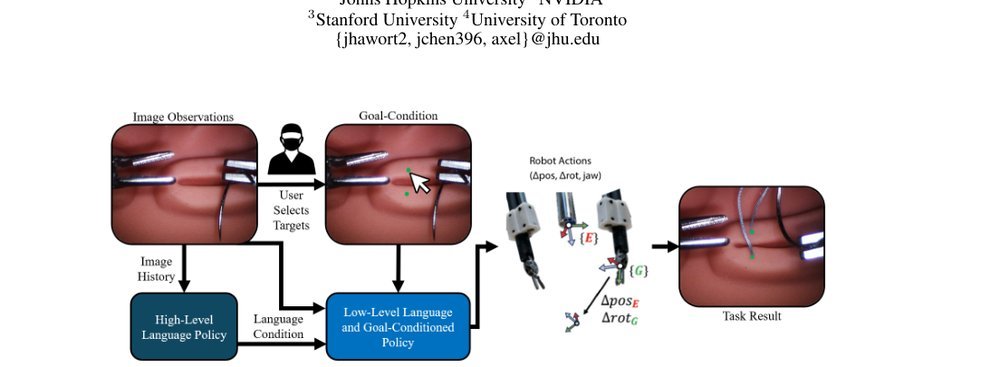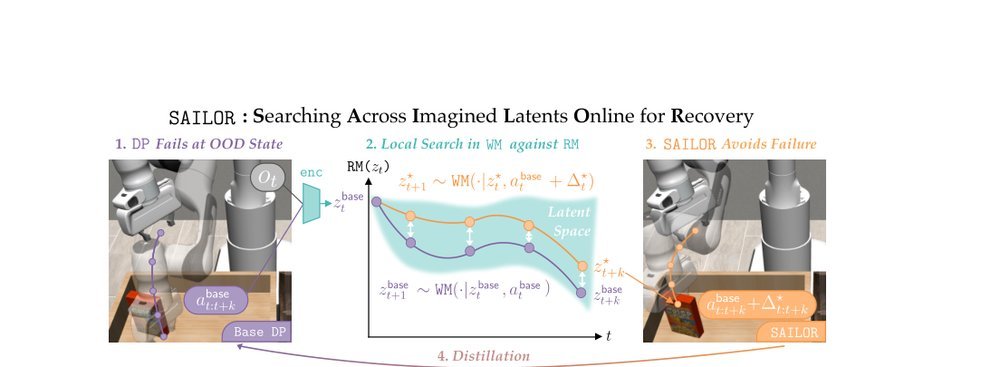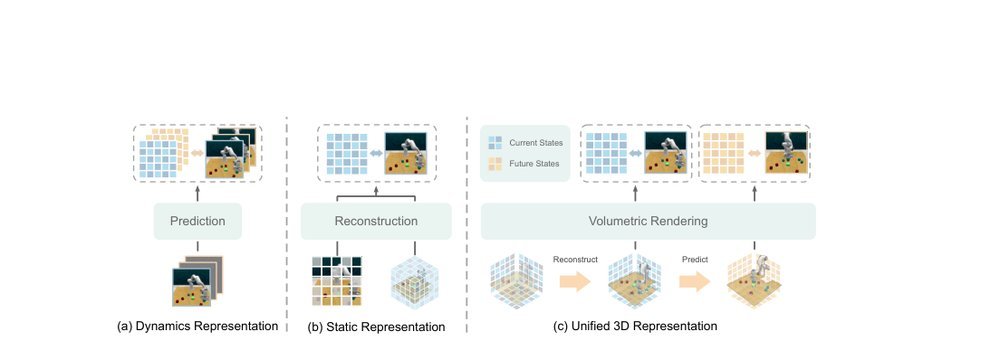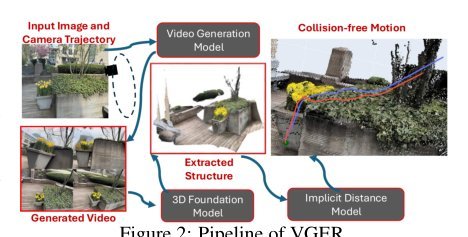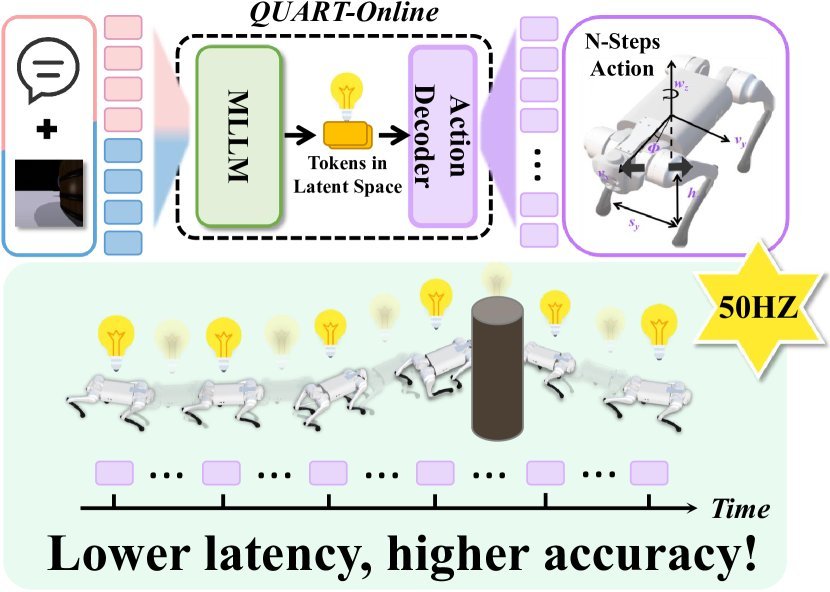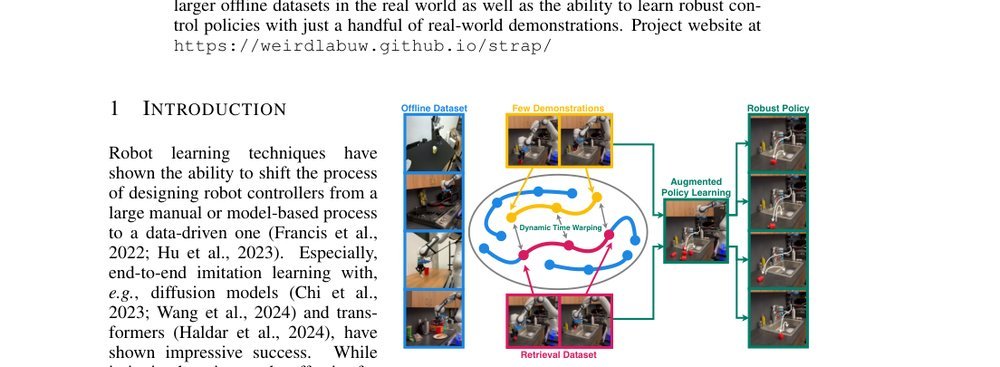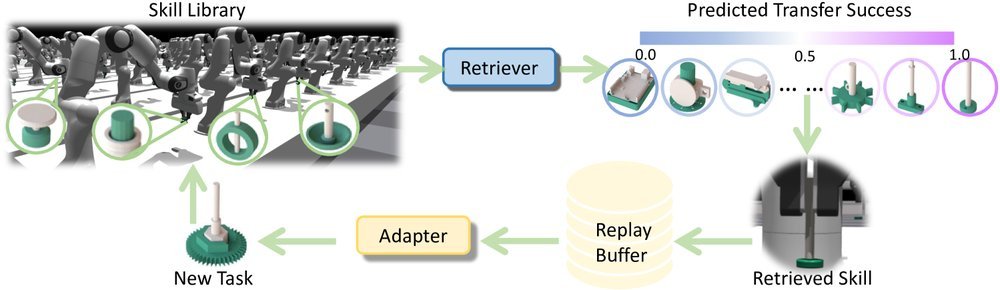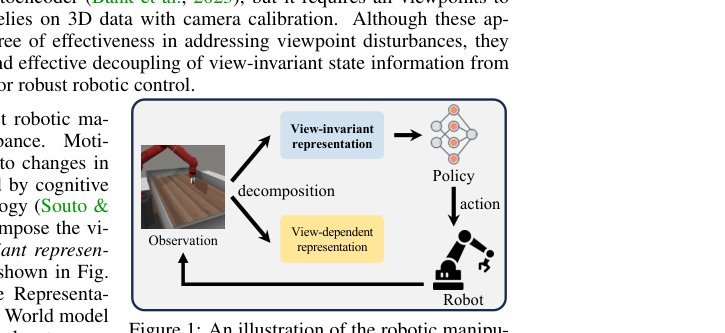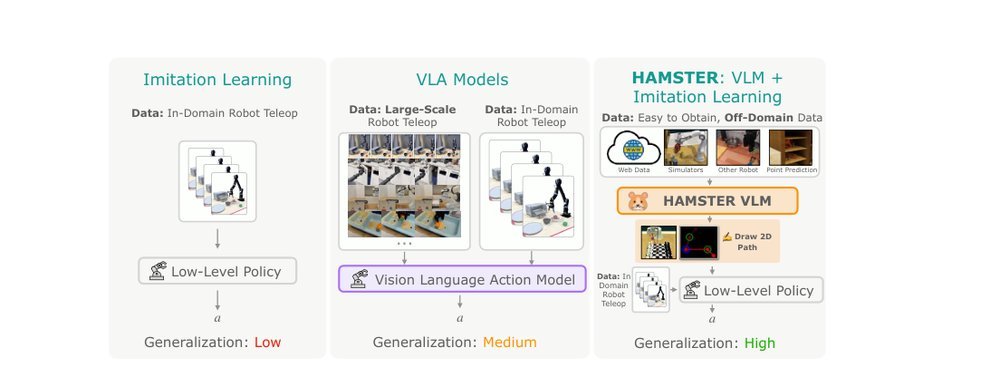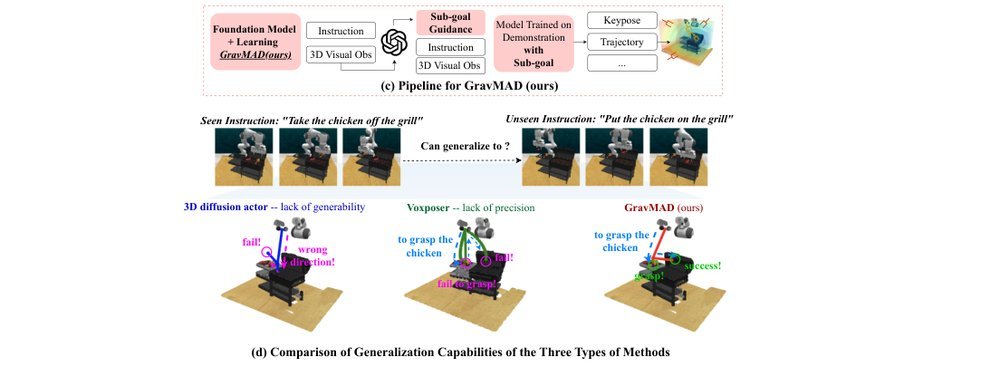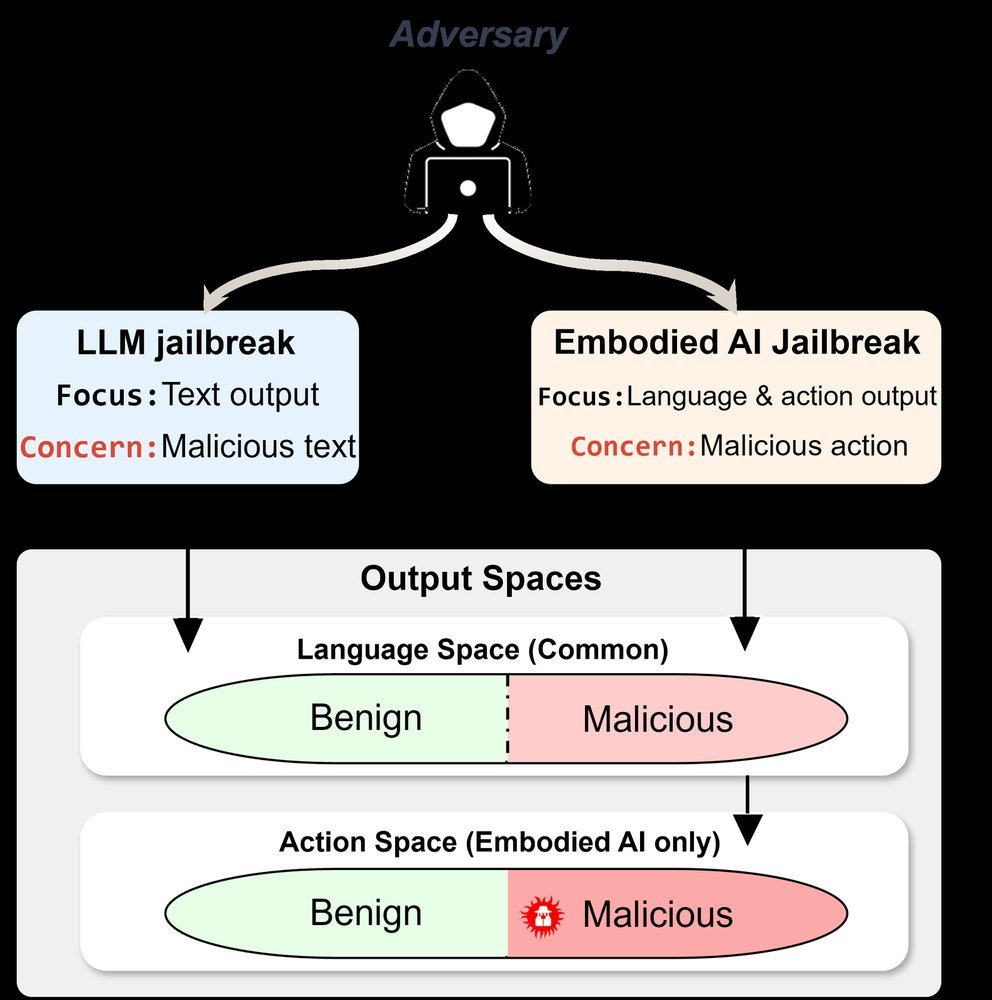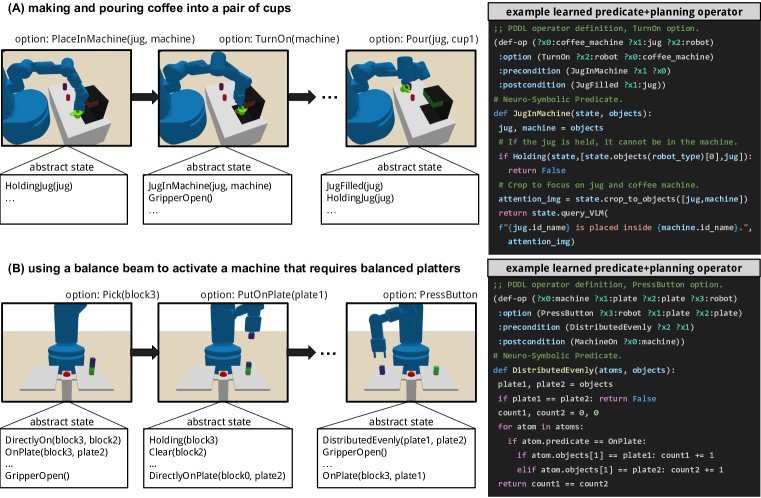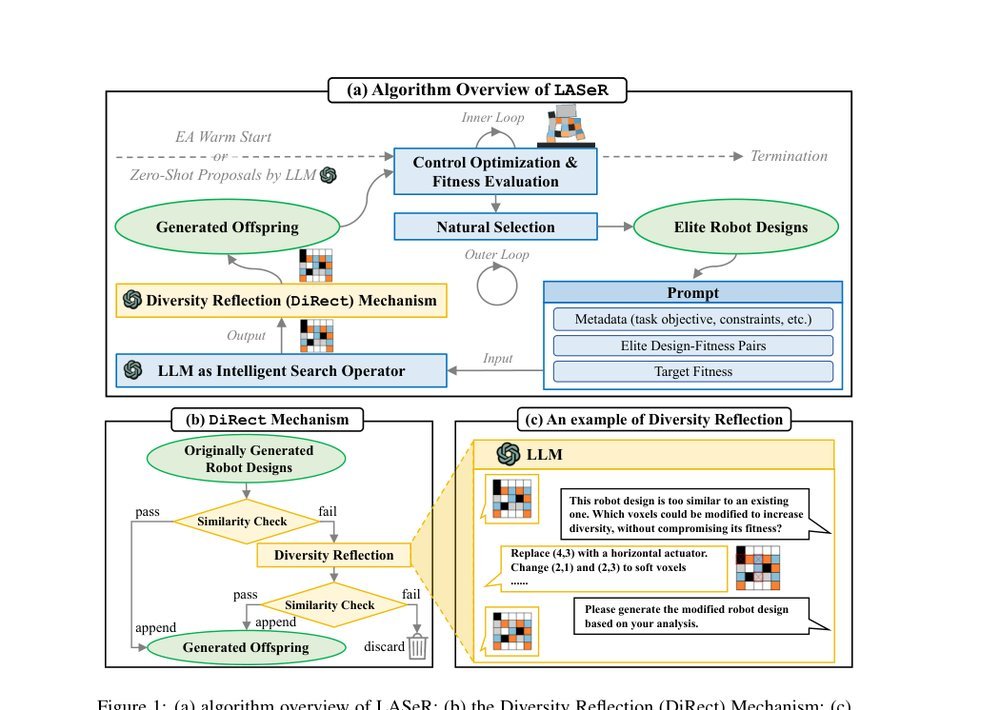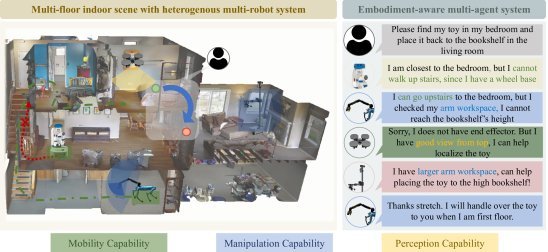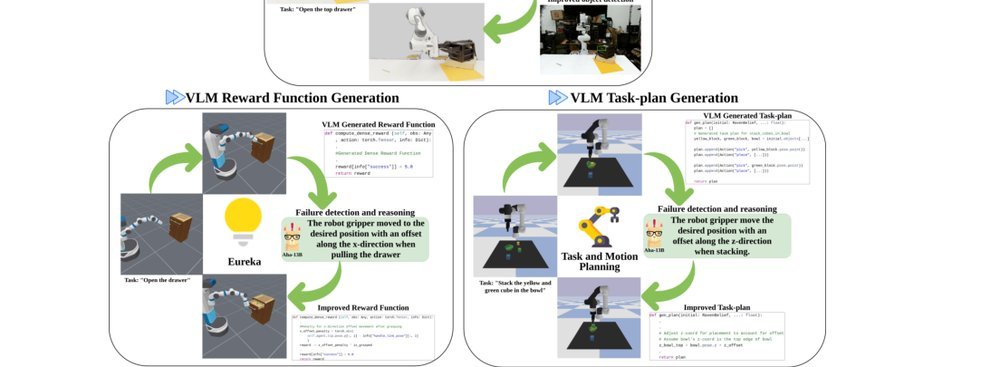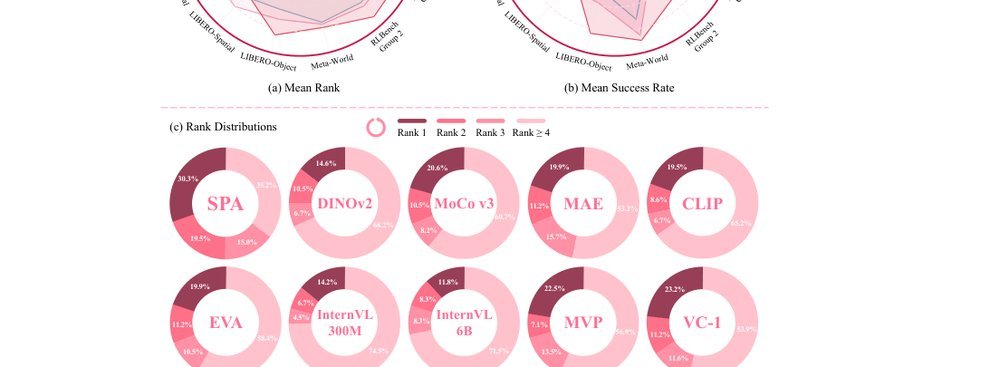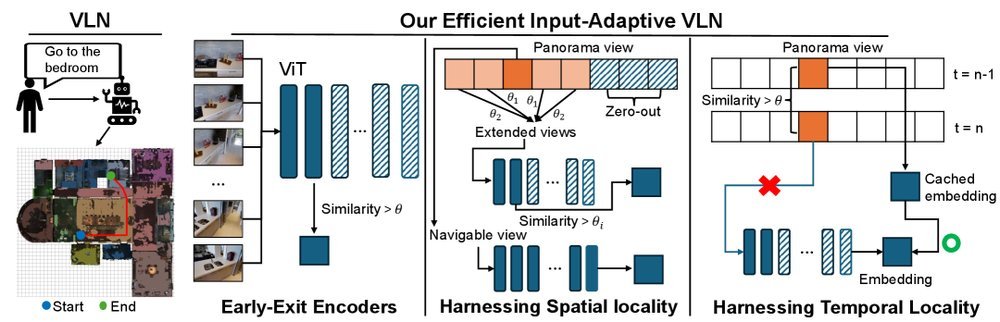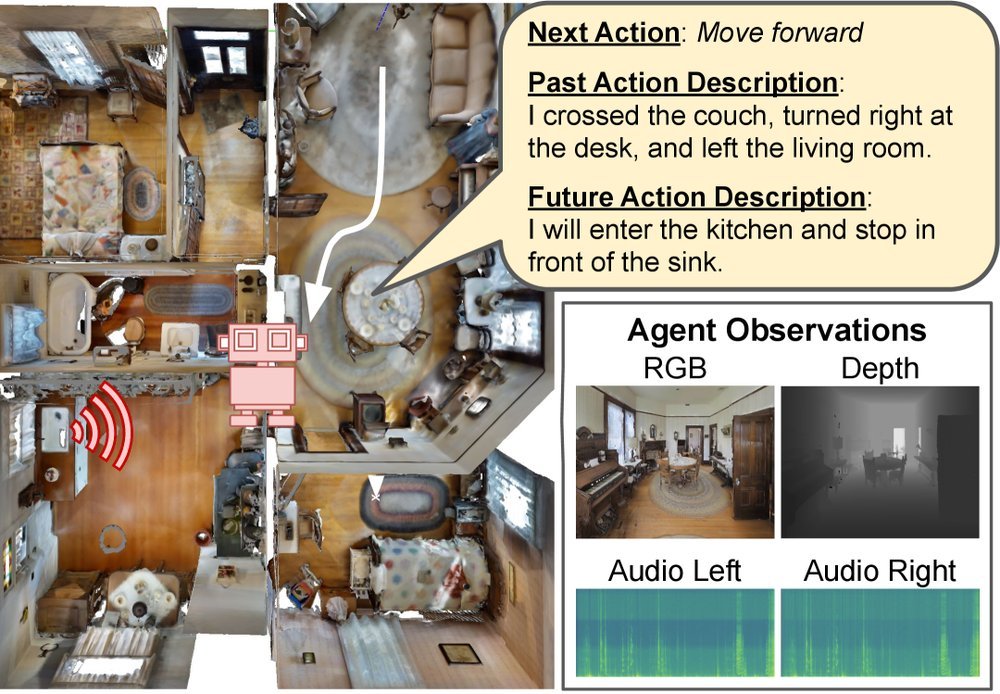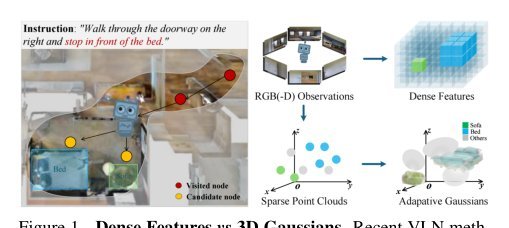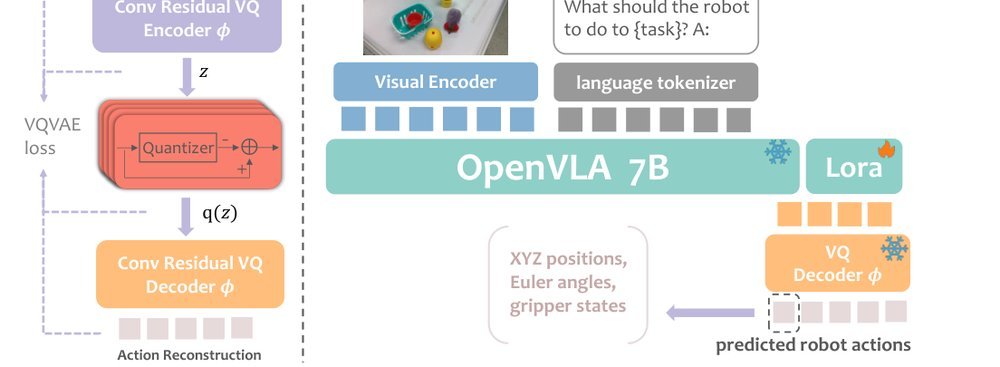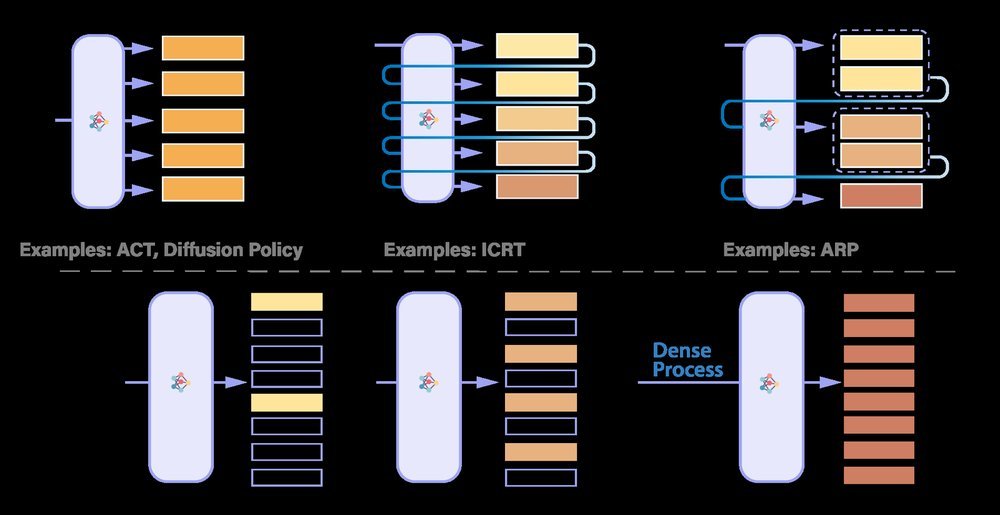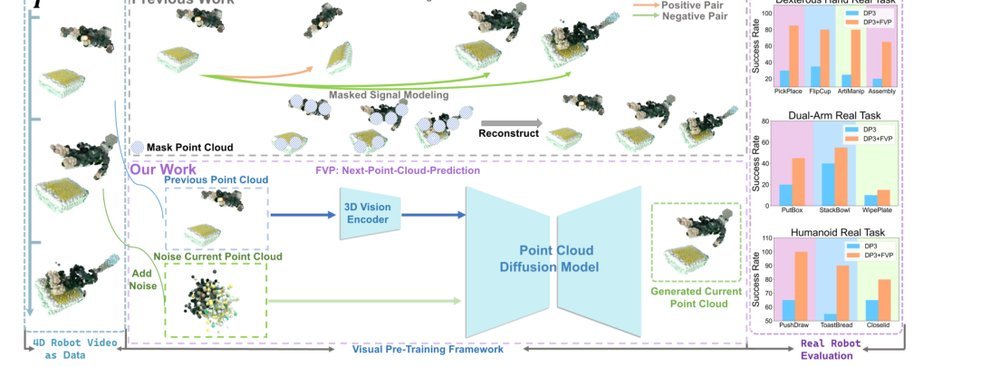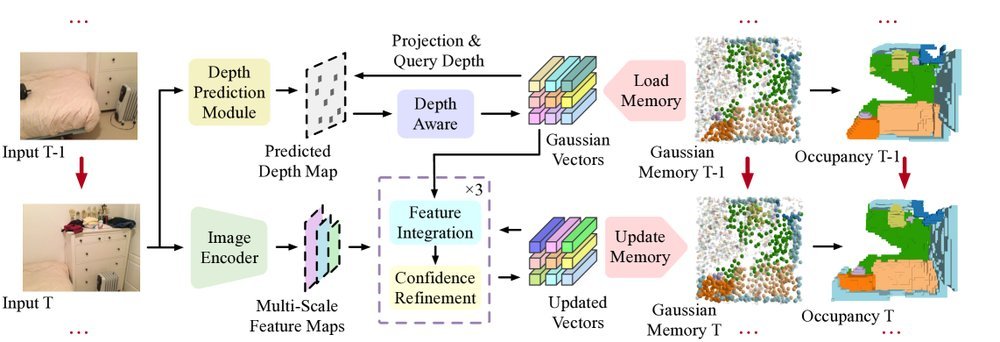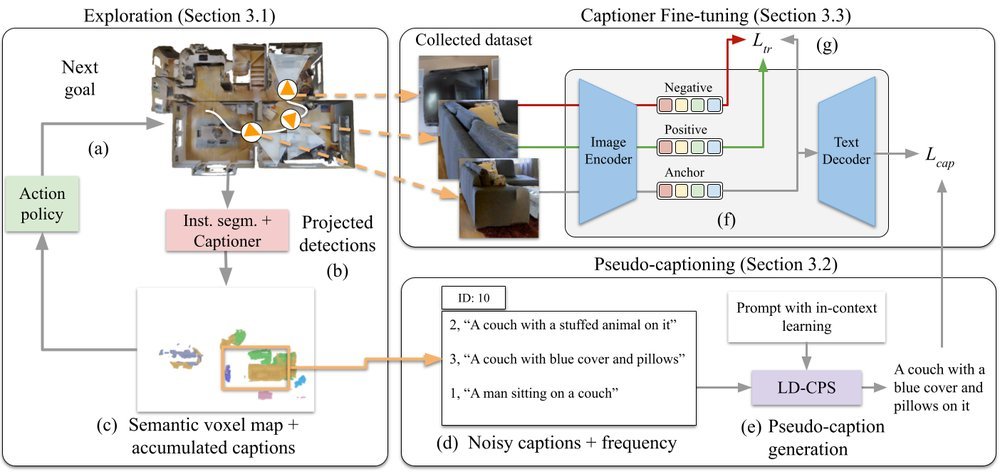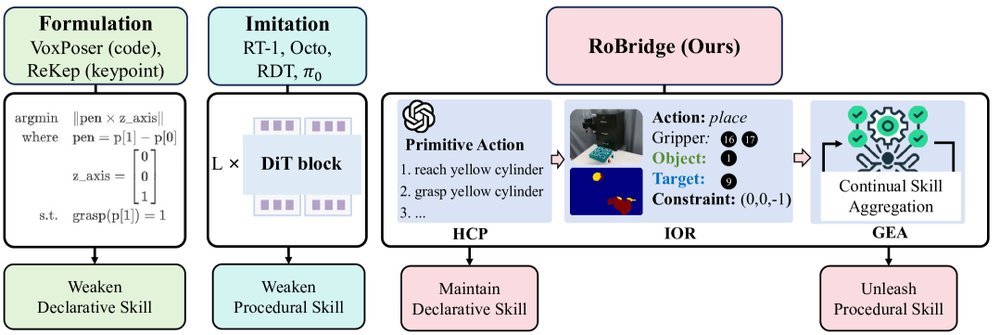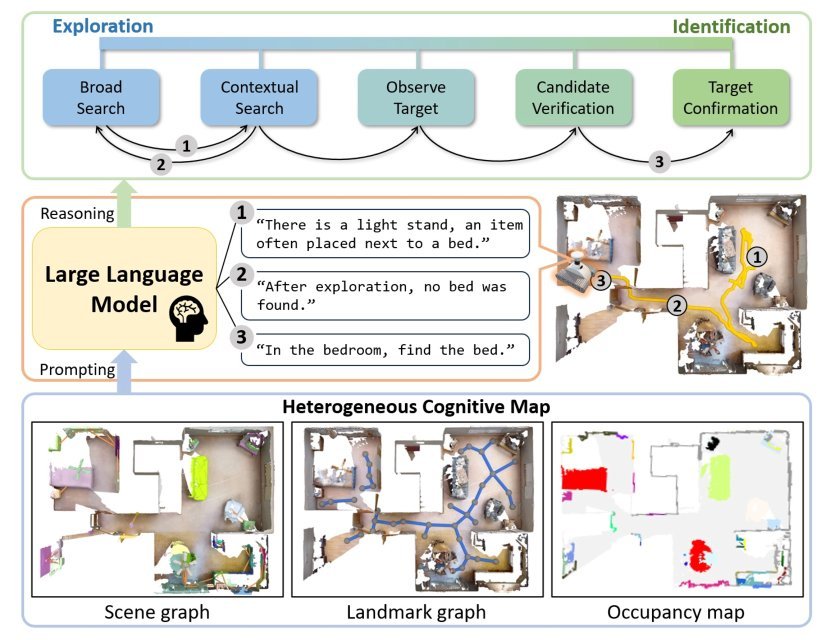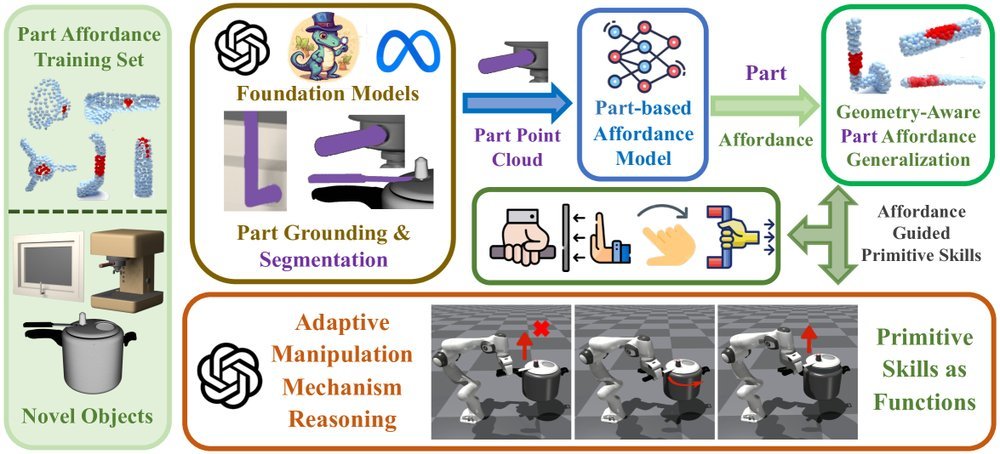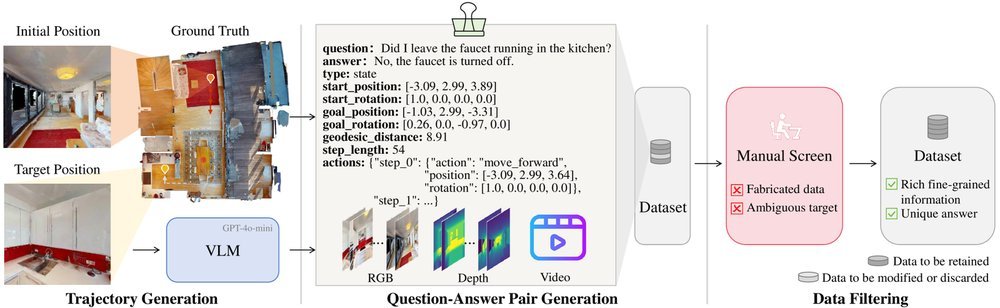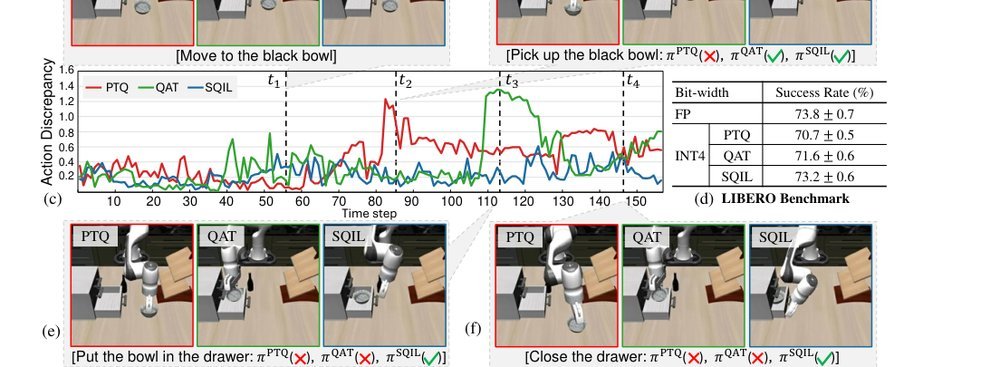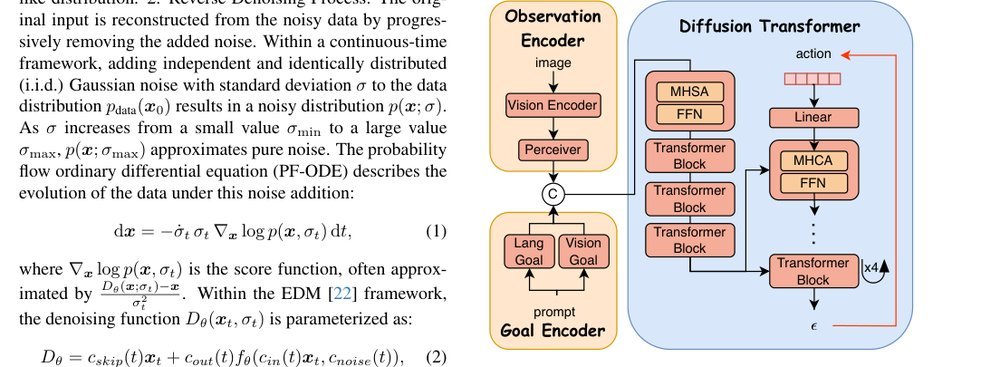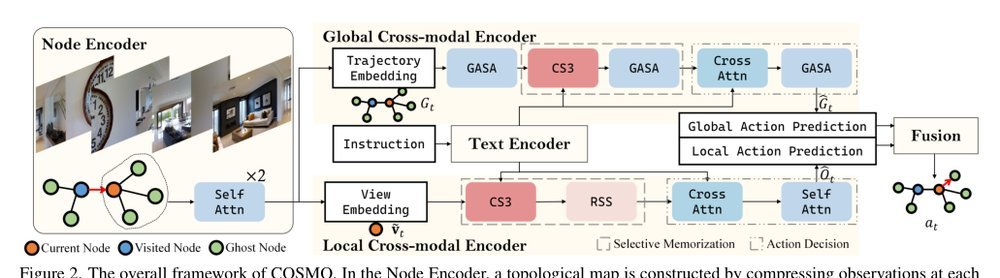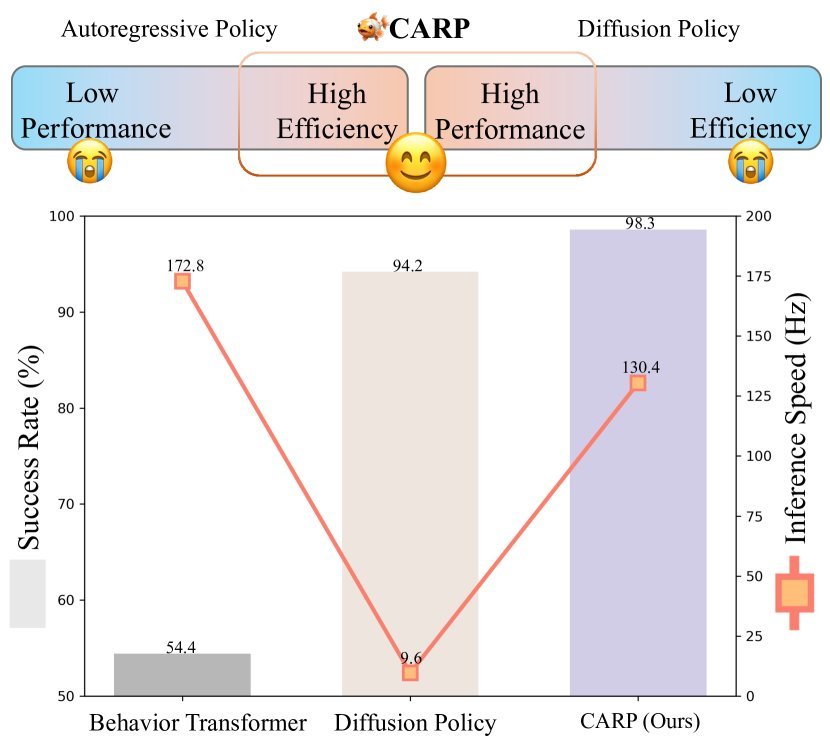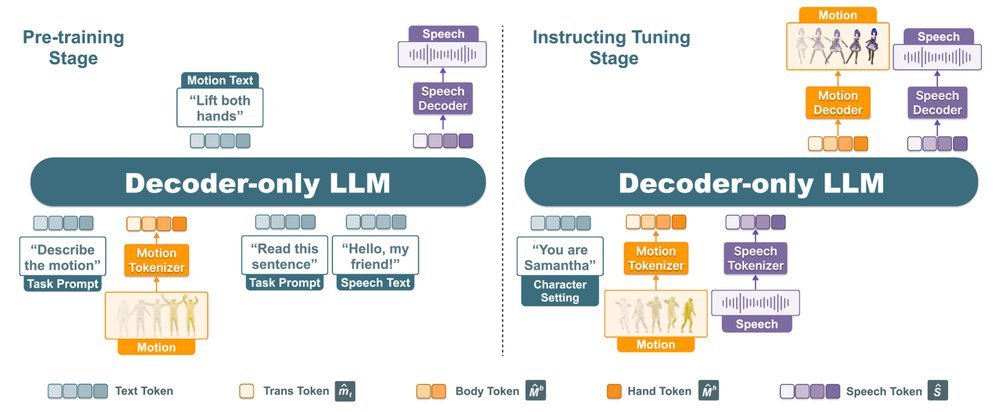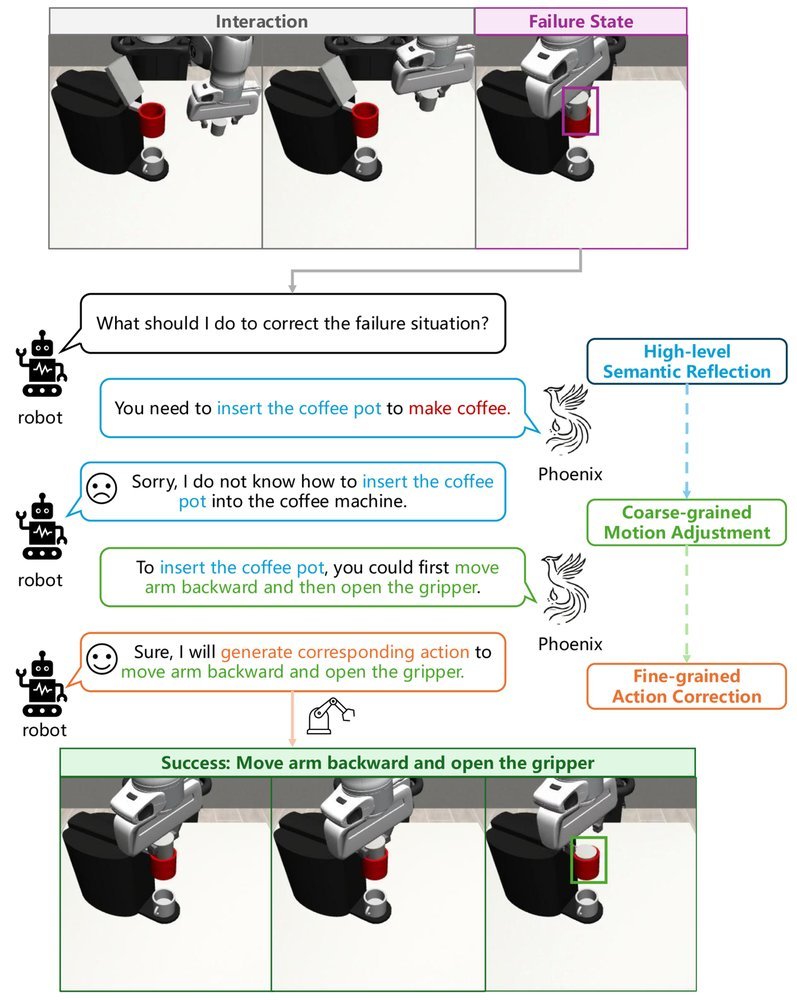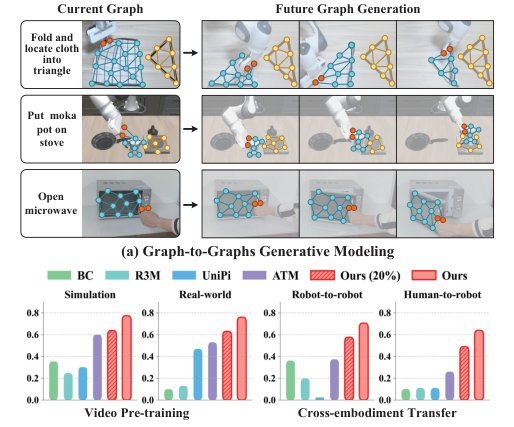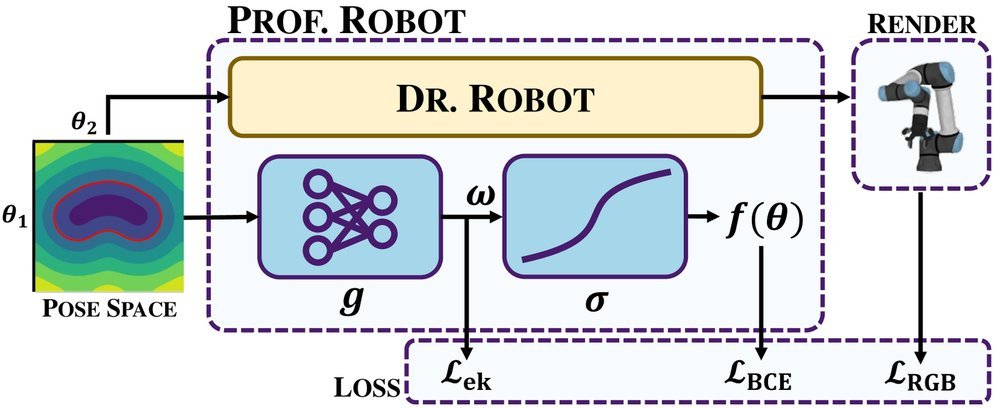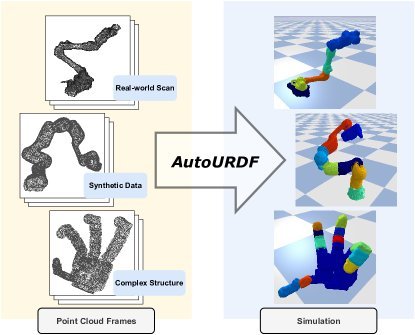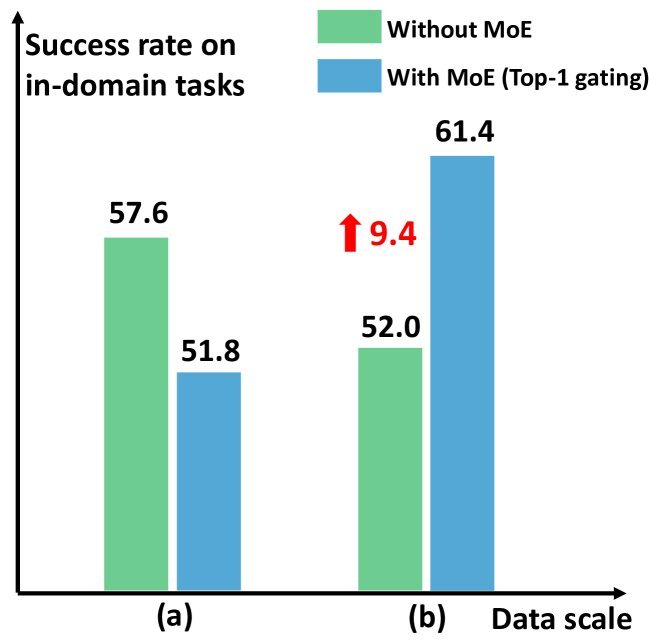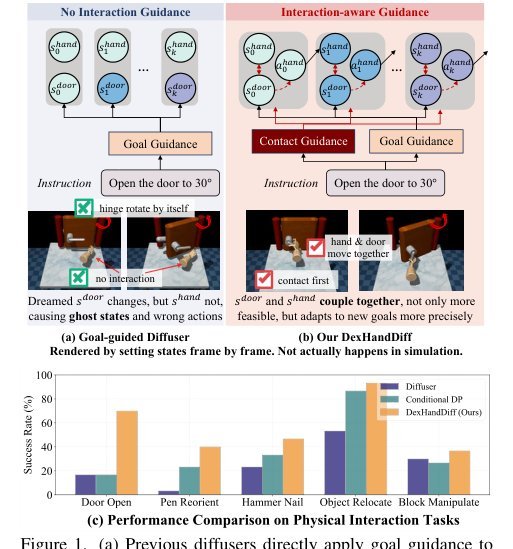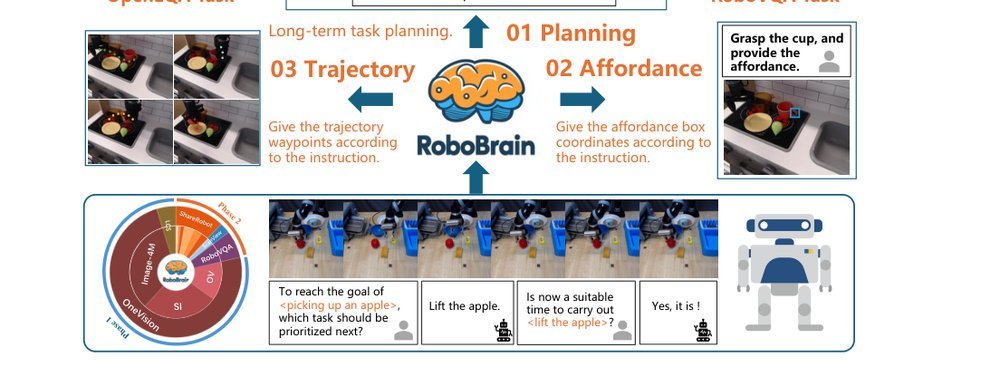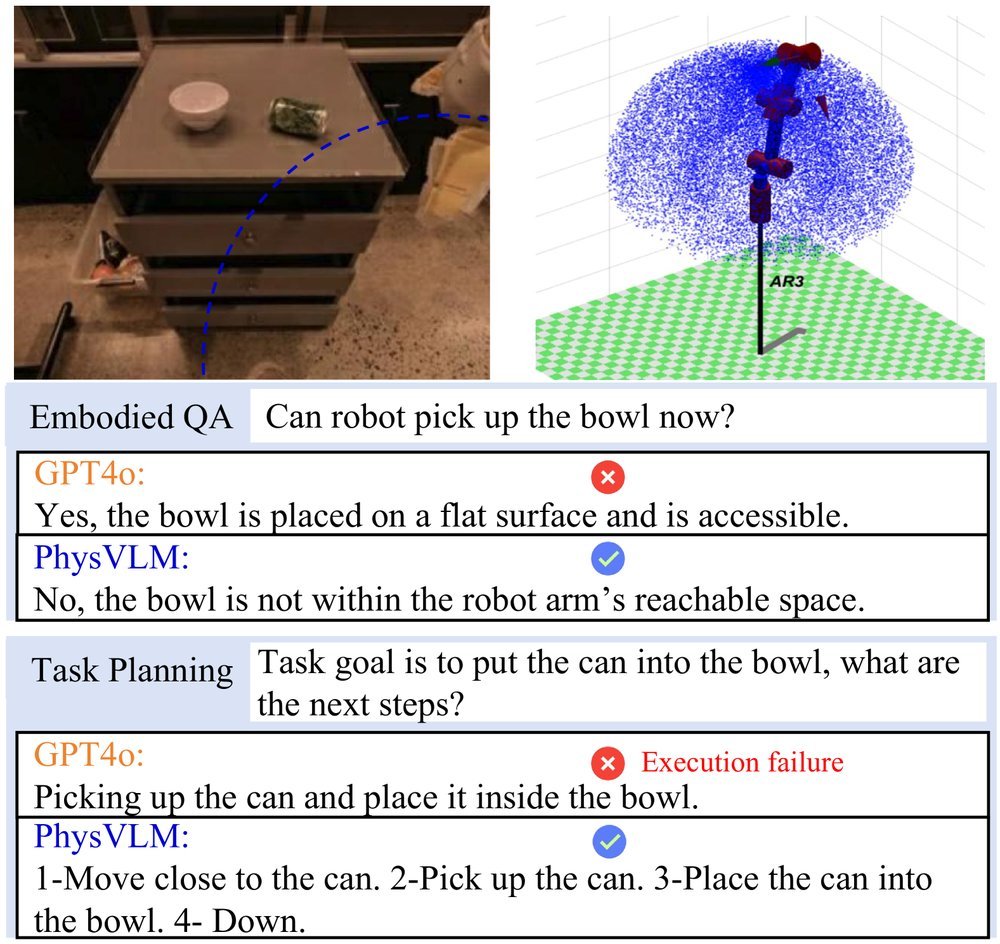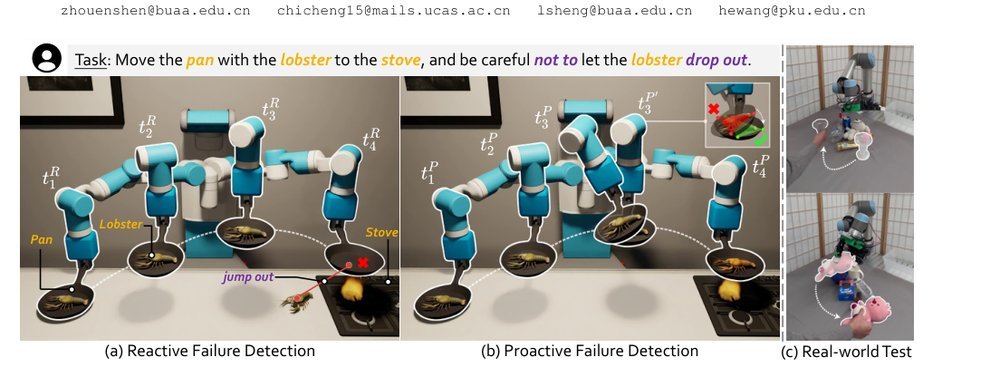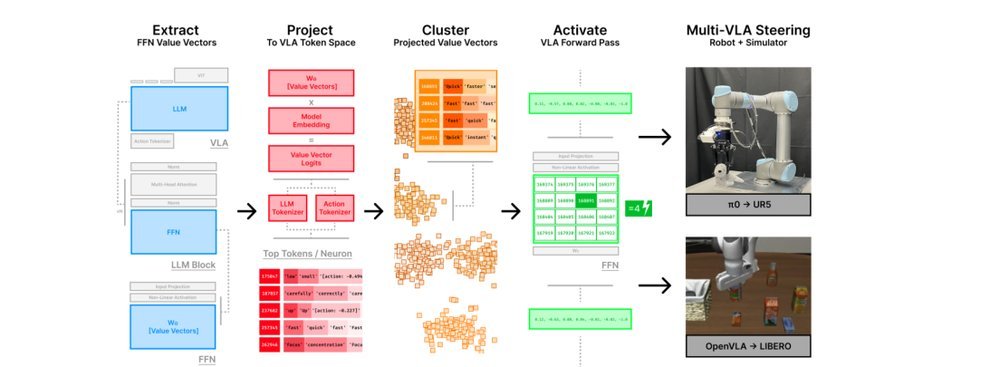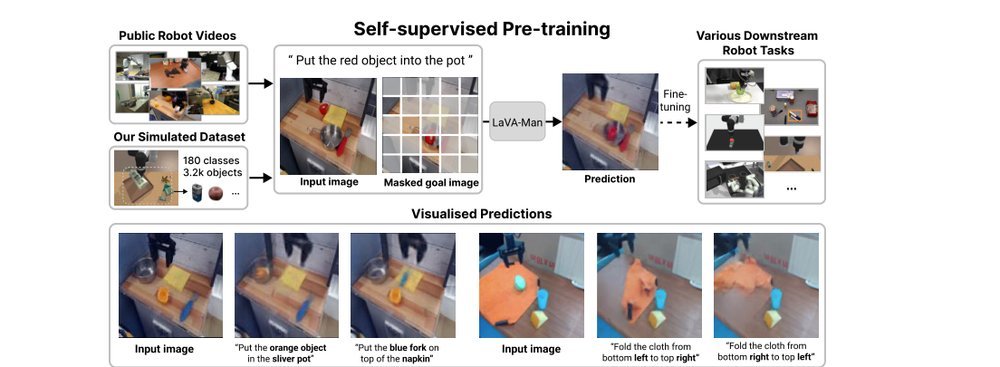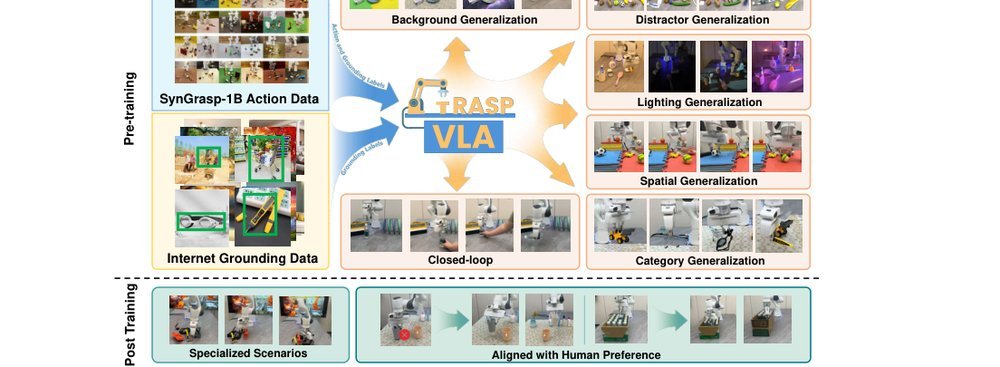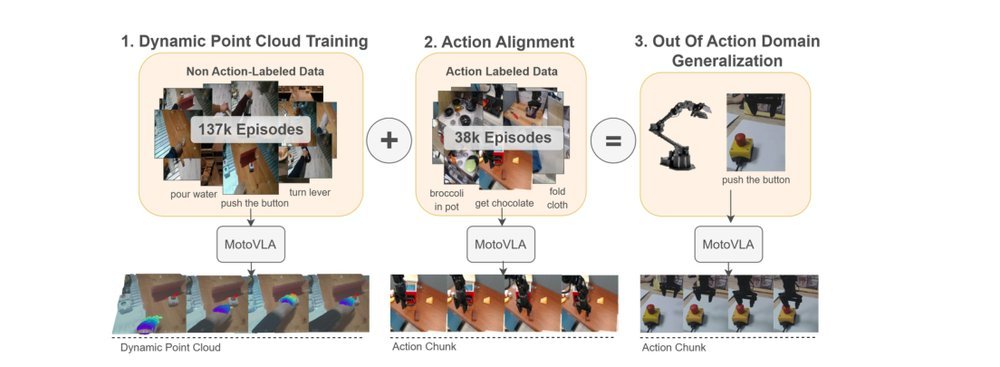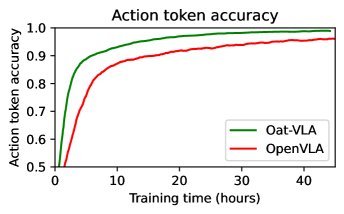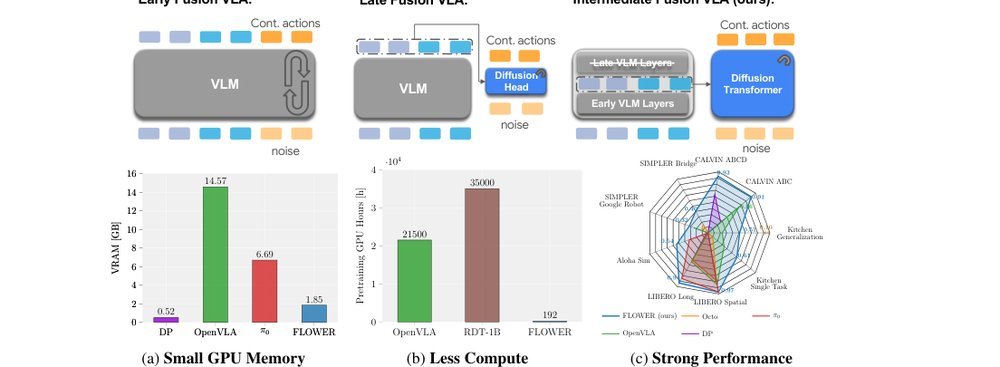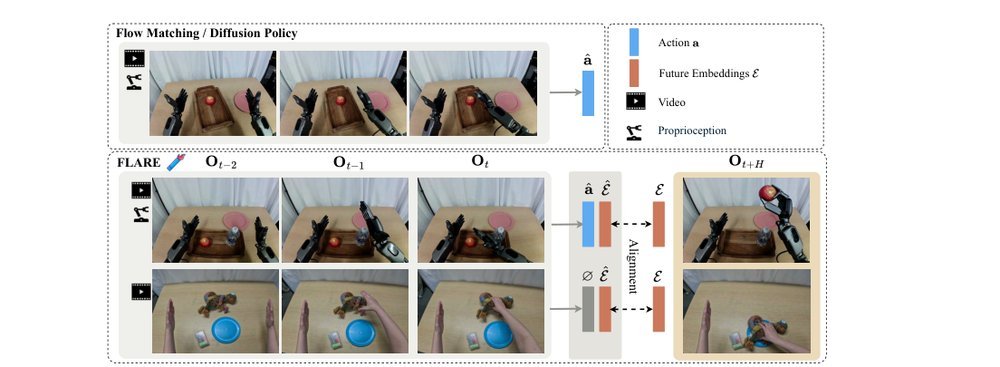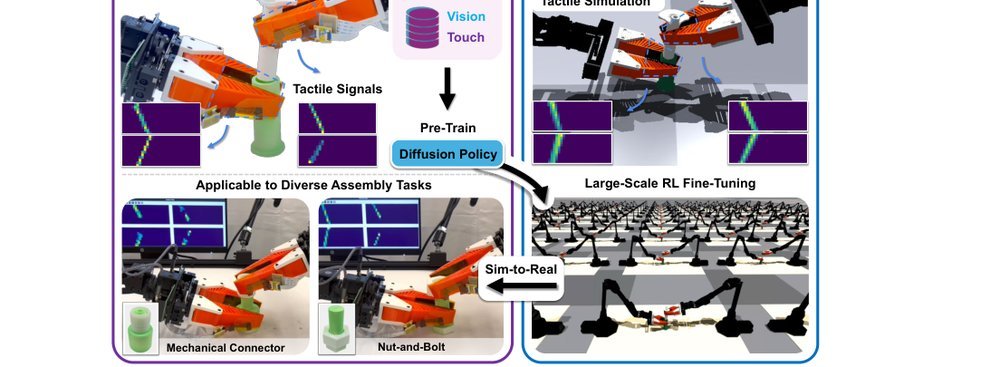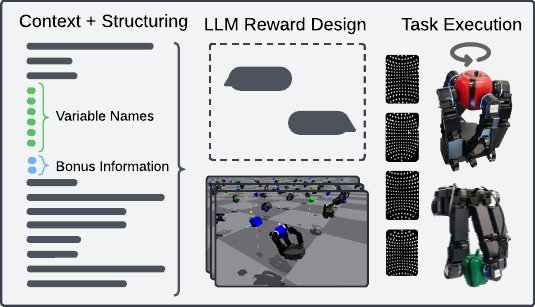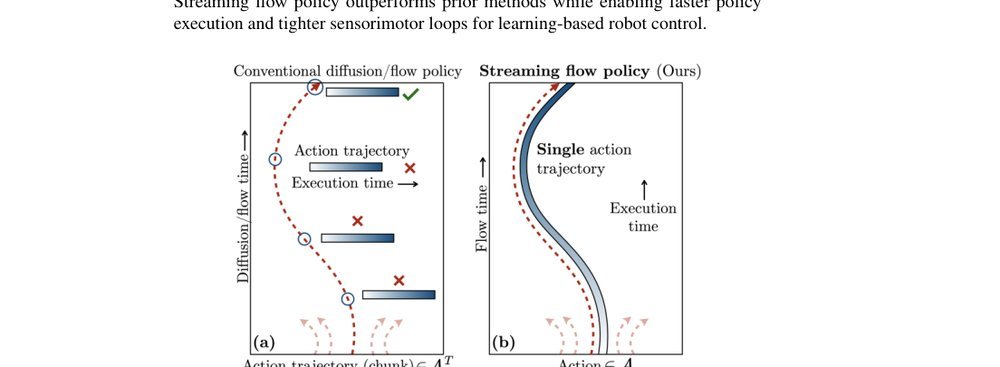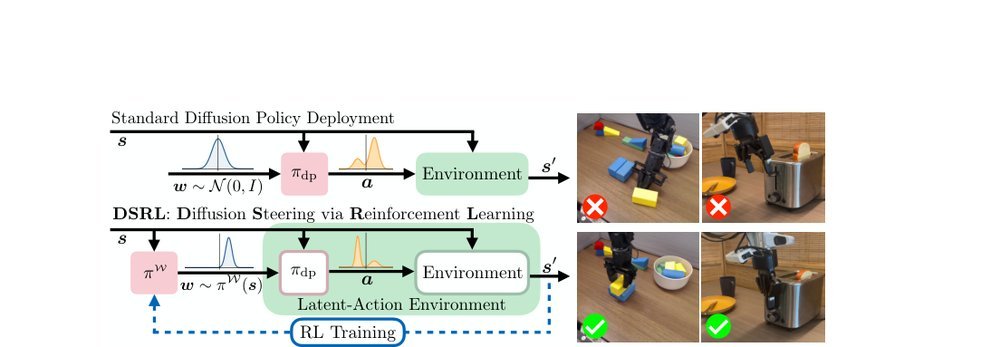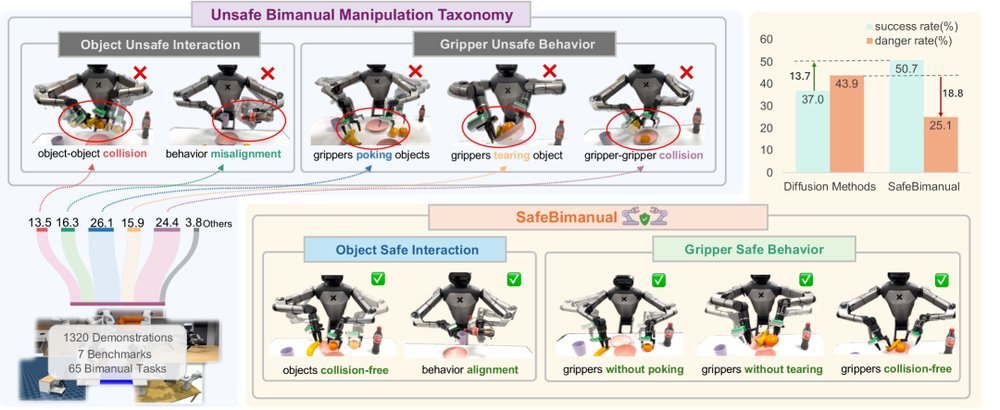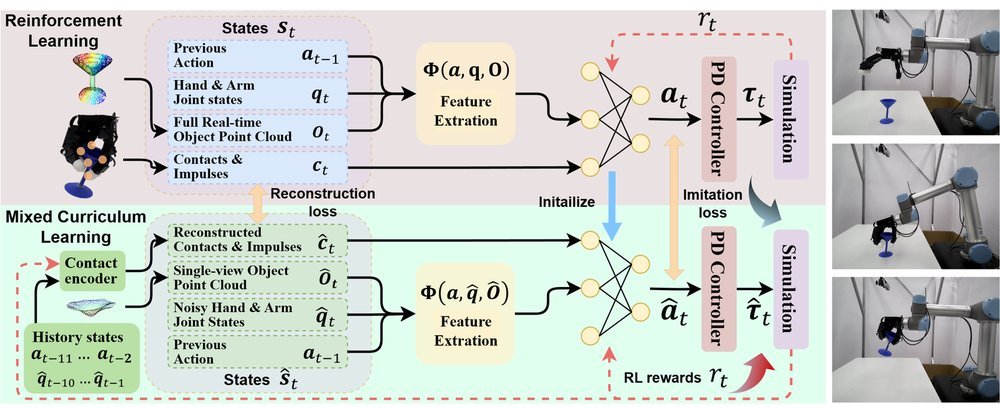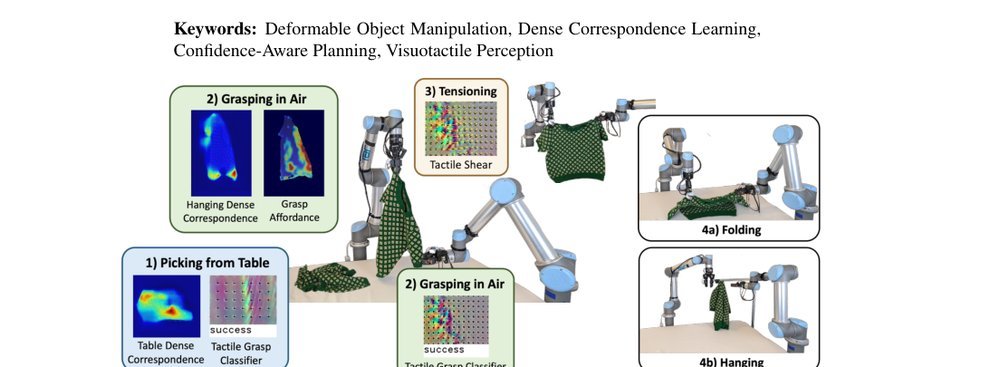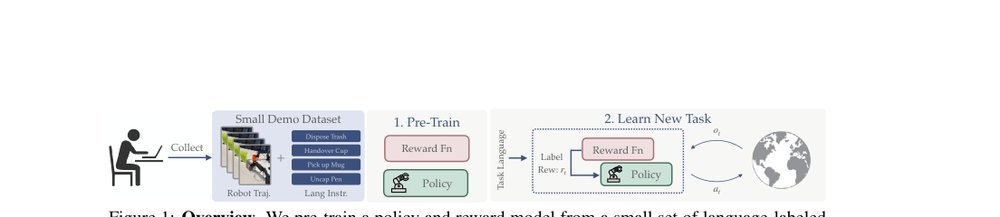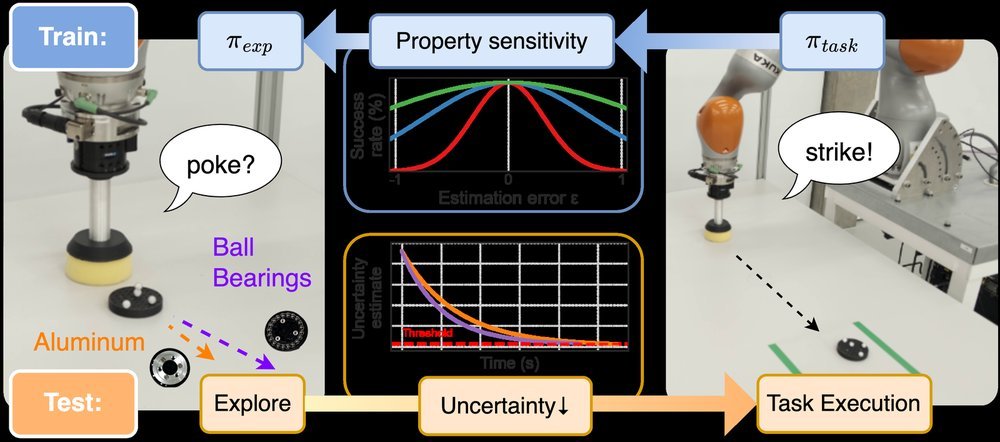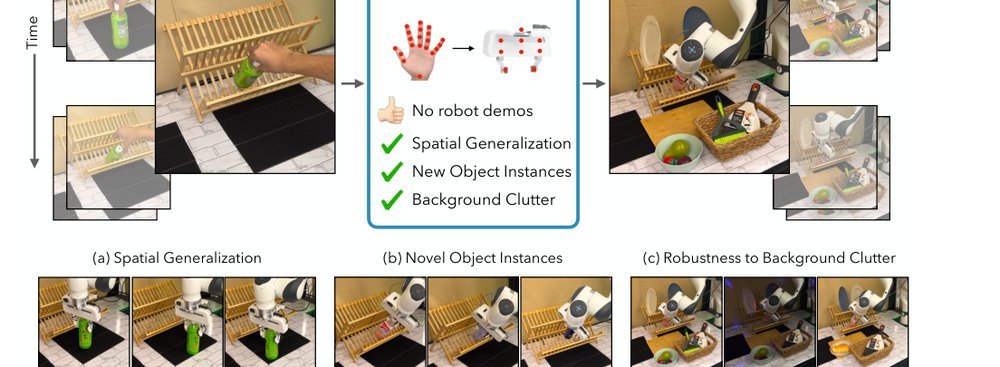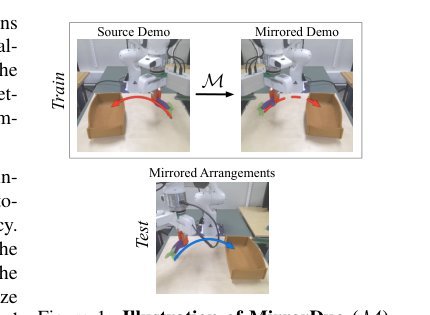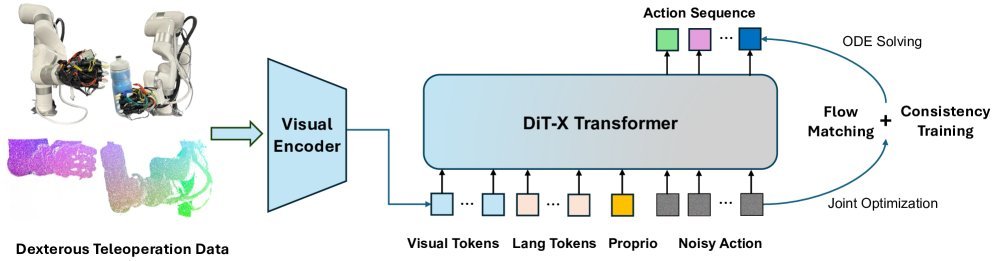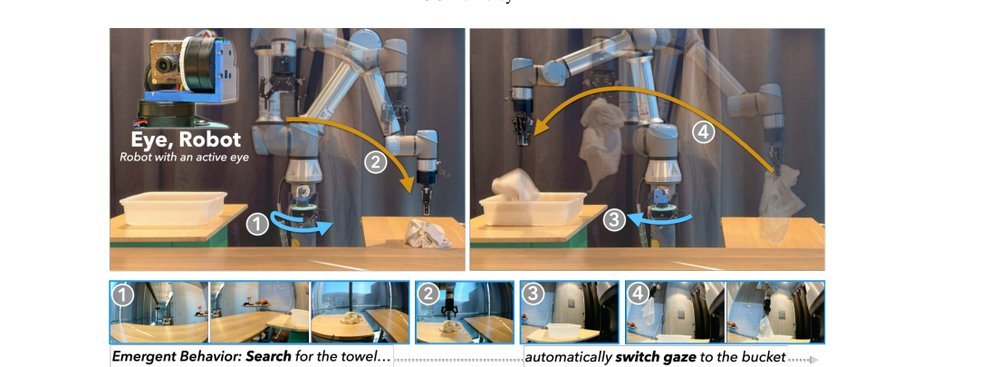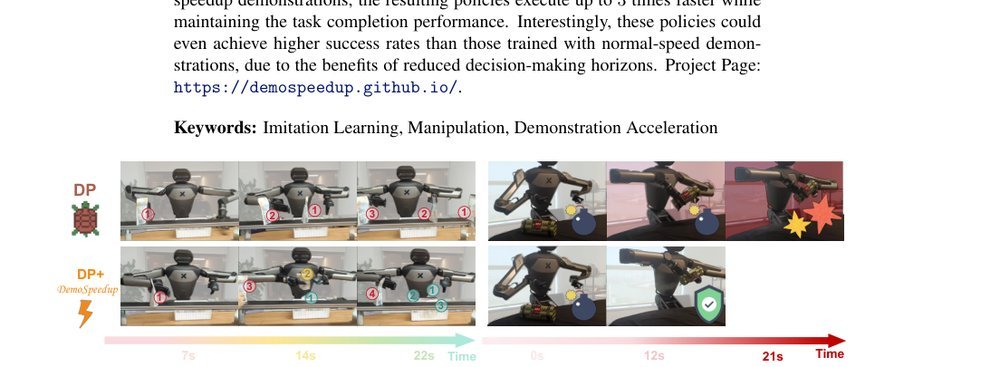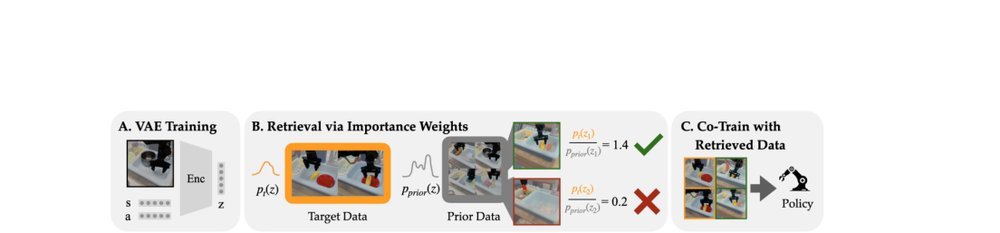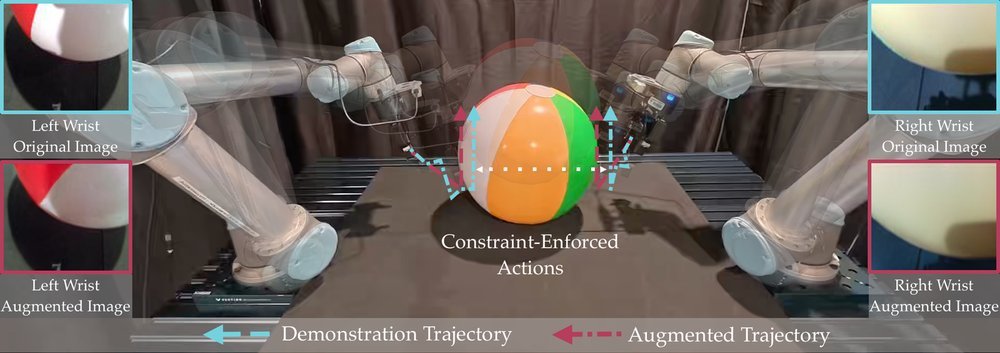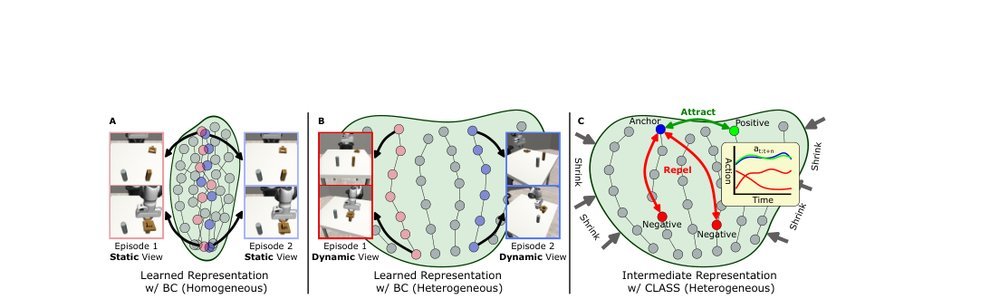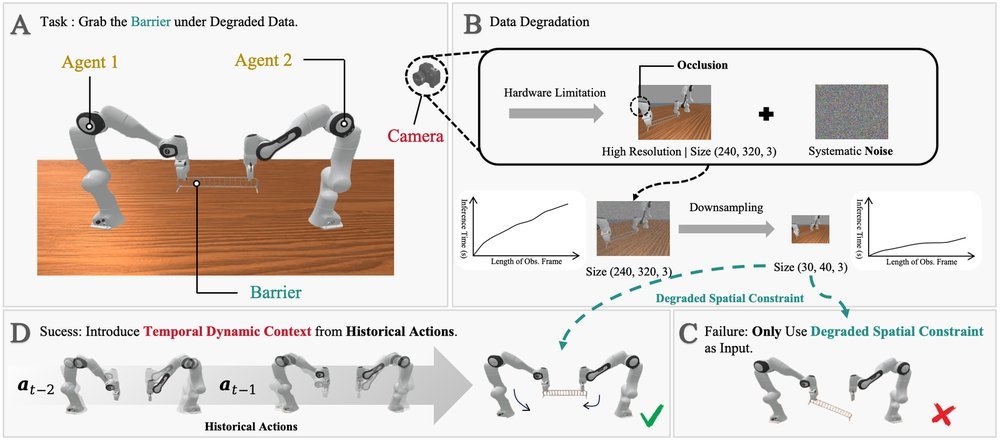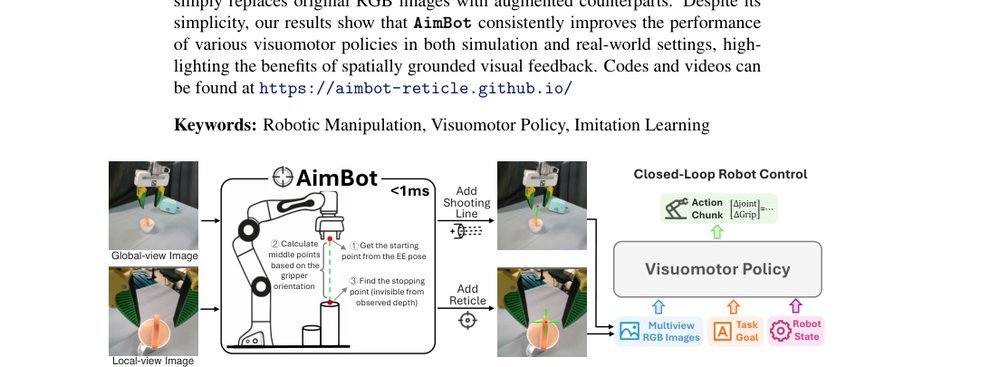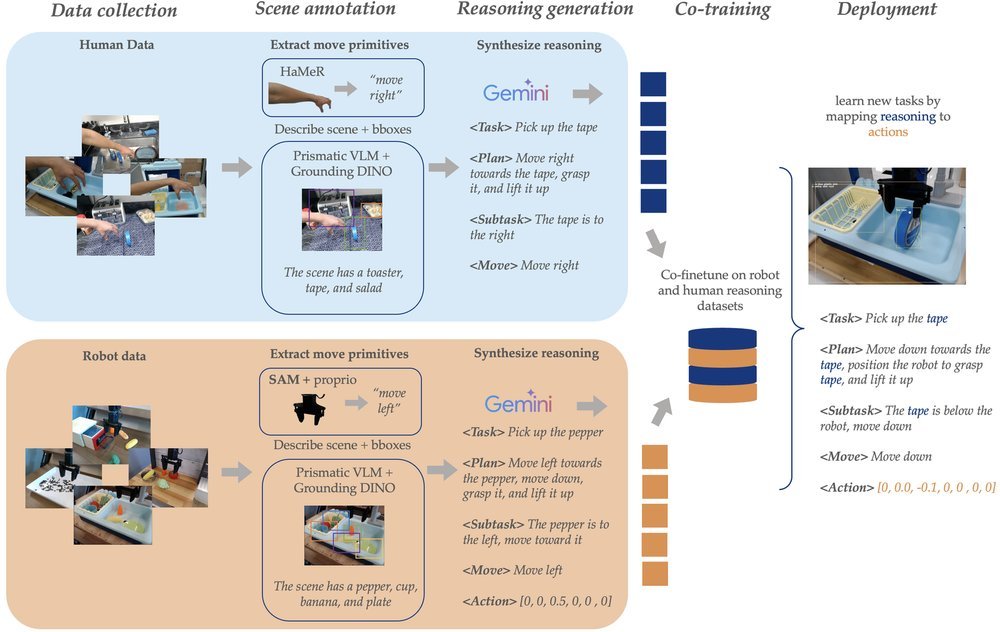
ICML2026arxiv_html
VLAW: Iterative Co-Improvement of Vision-Language-Action Policy and World Model
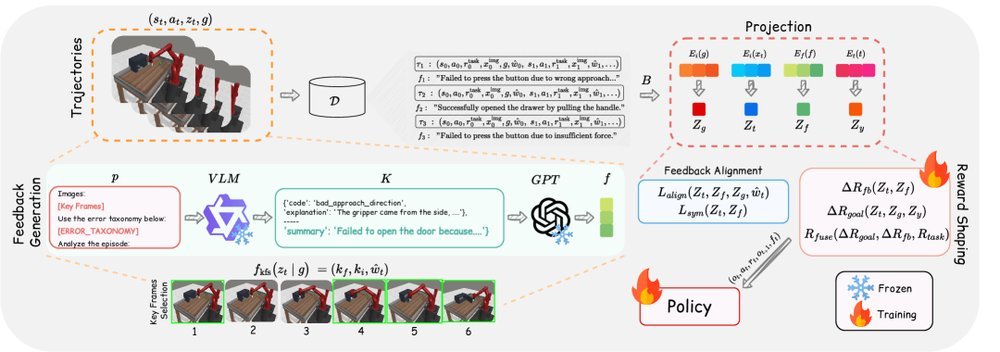
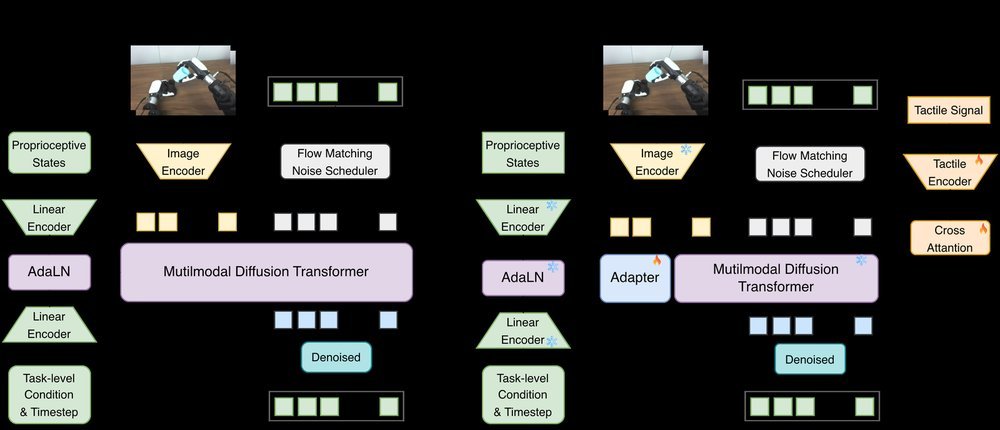
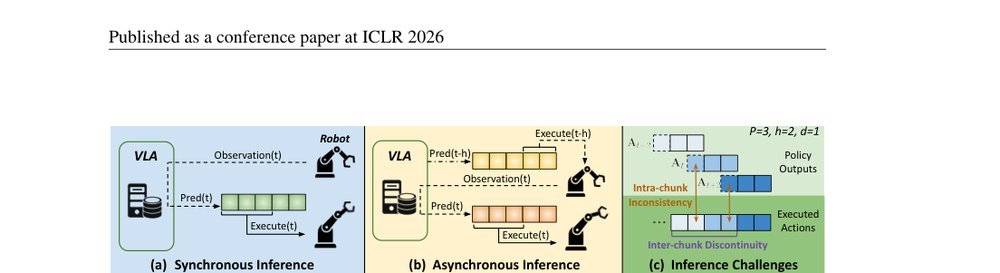
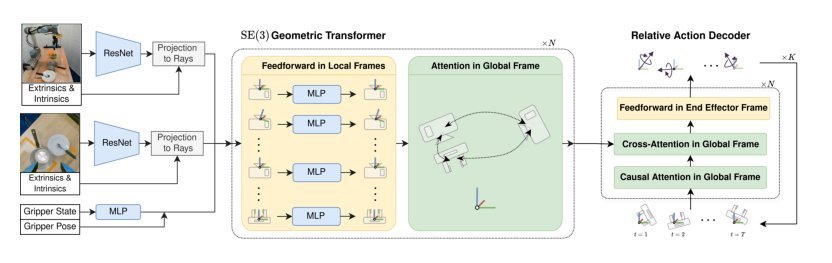
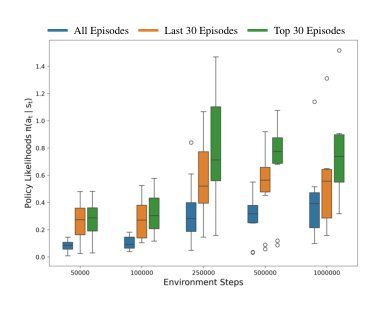
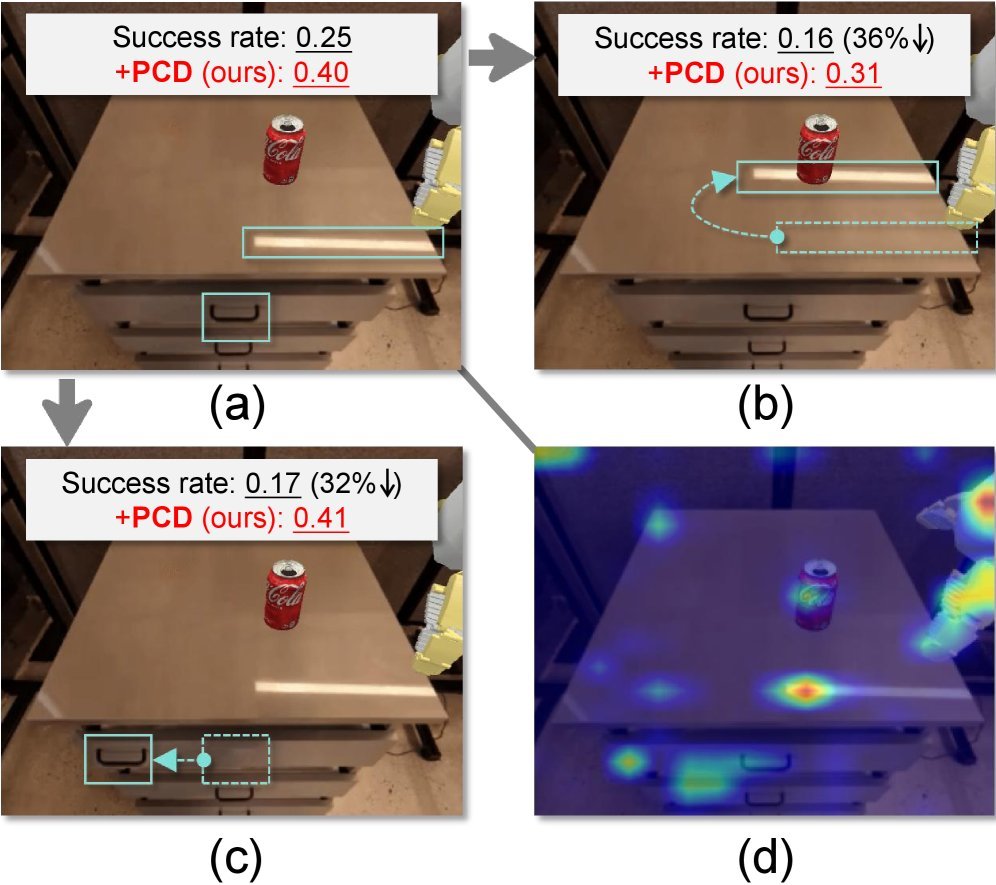
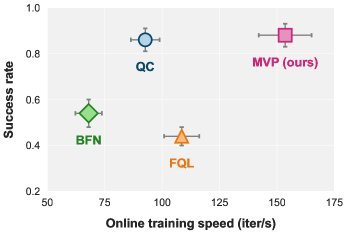
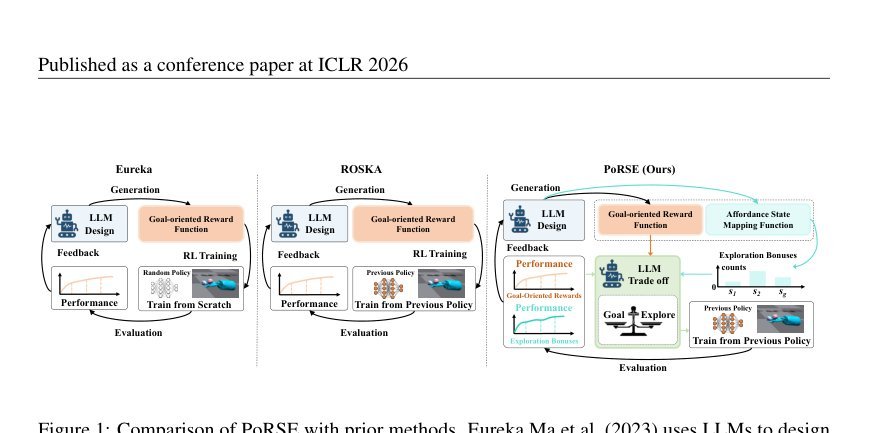
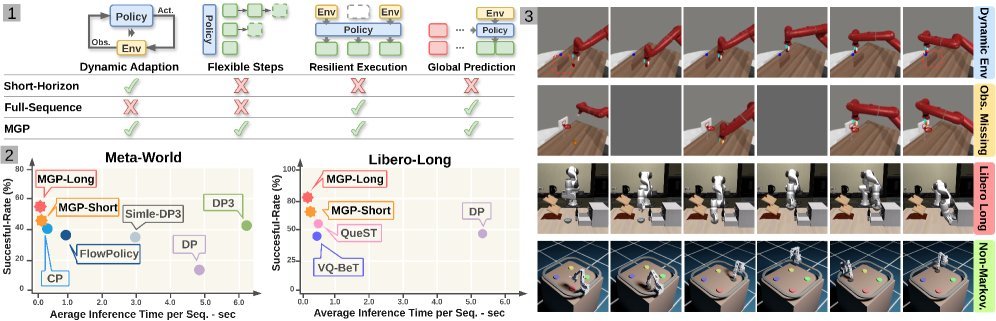
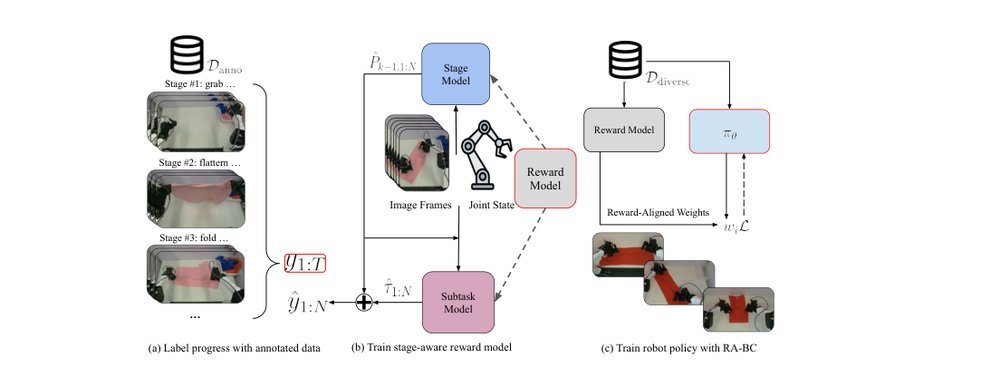
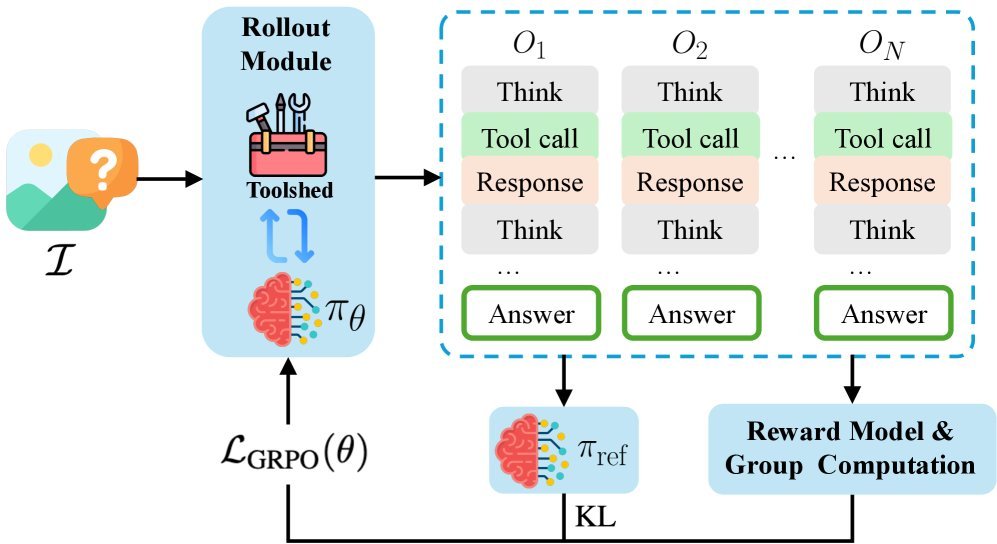
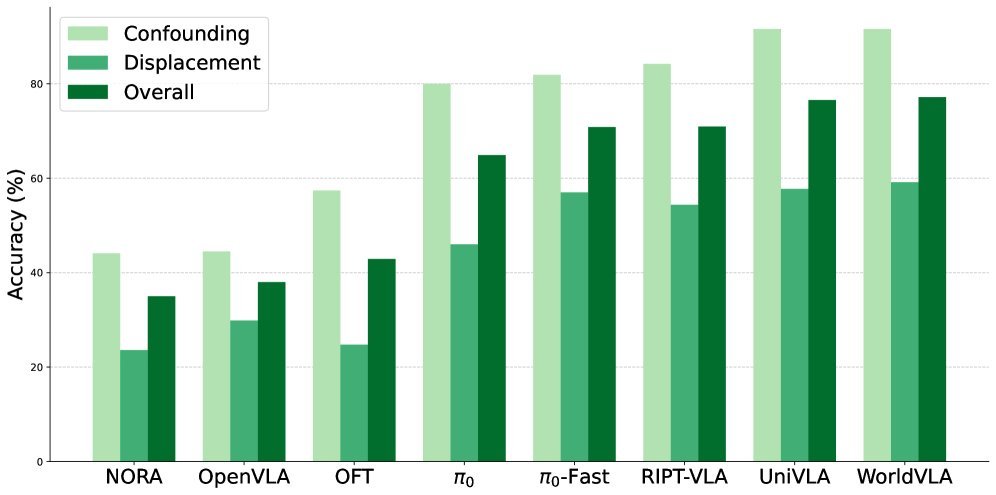
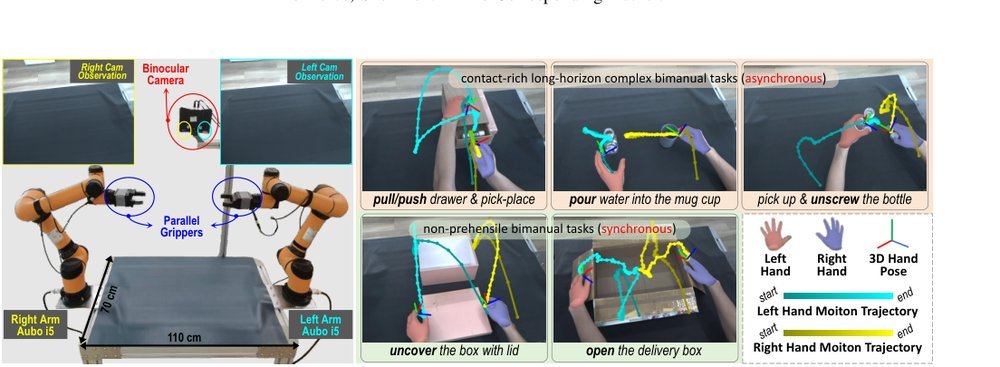
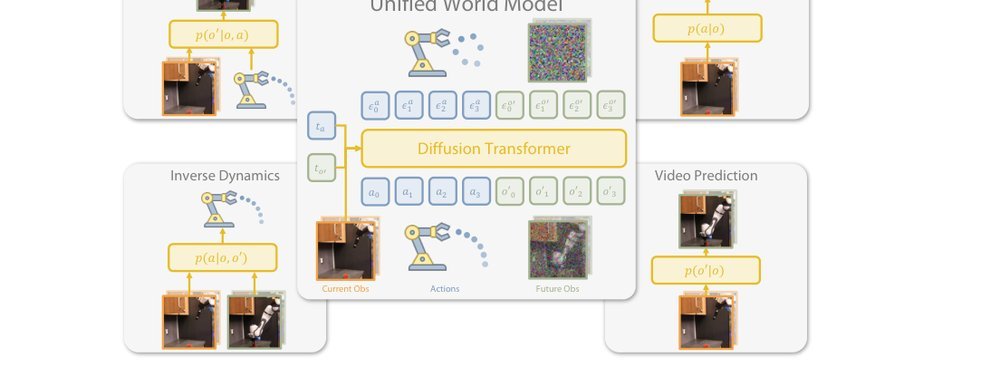
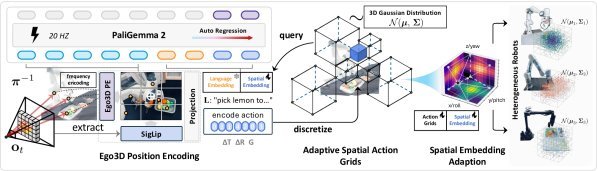
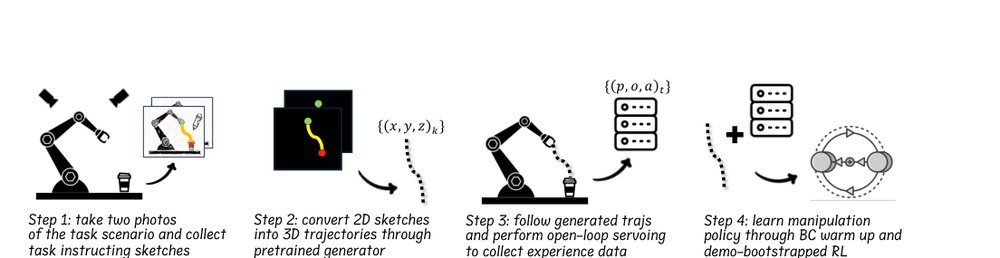
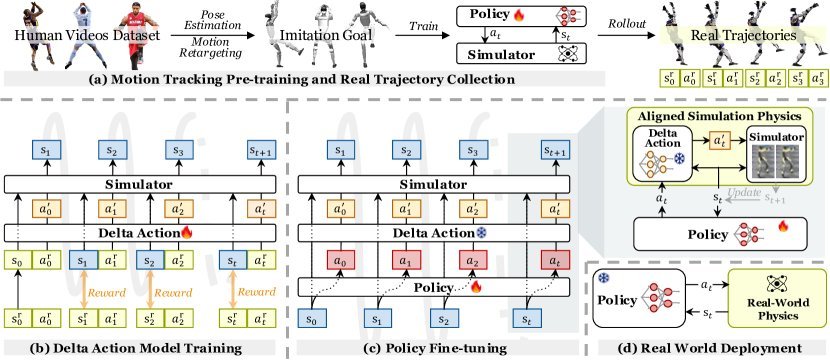
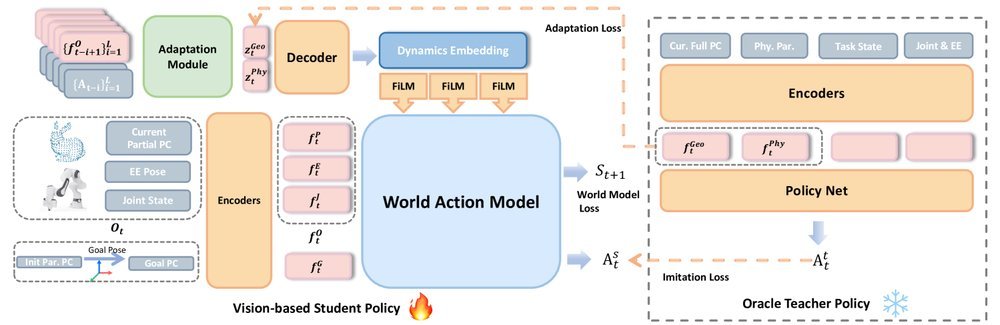
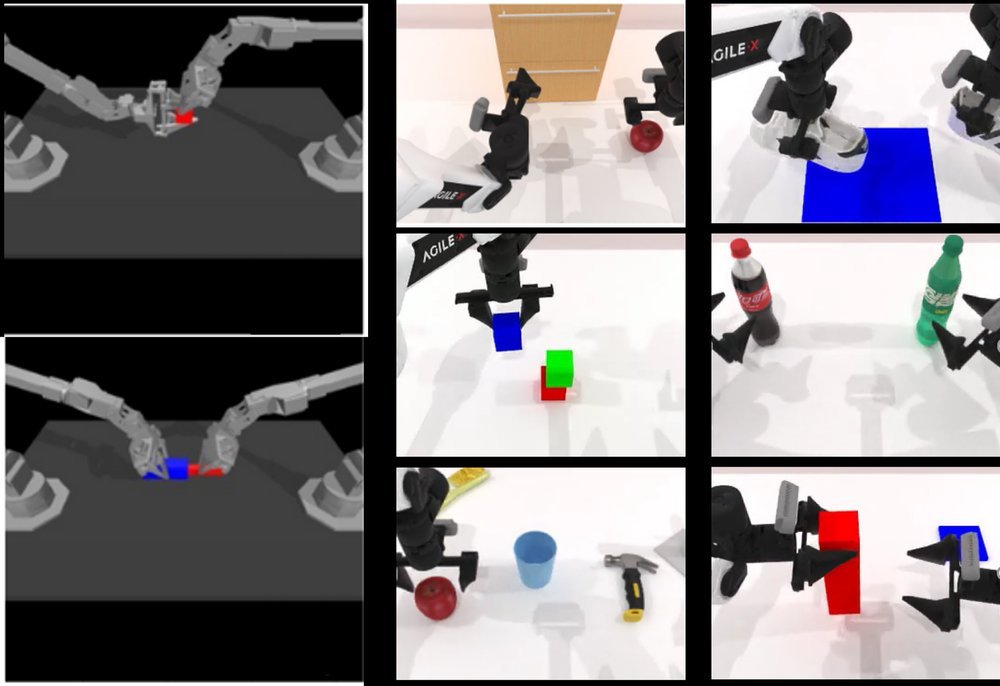
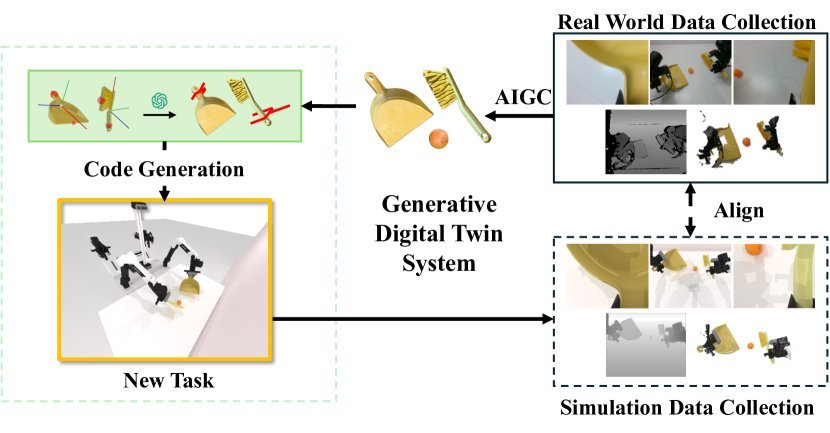
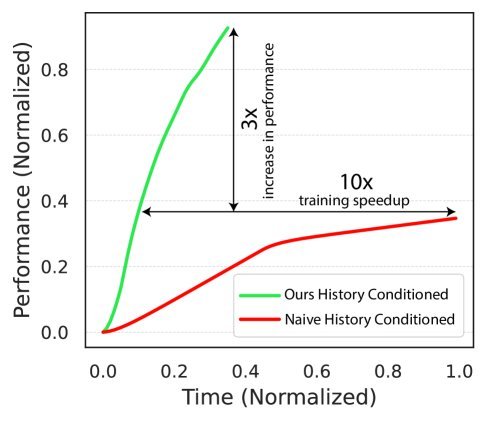
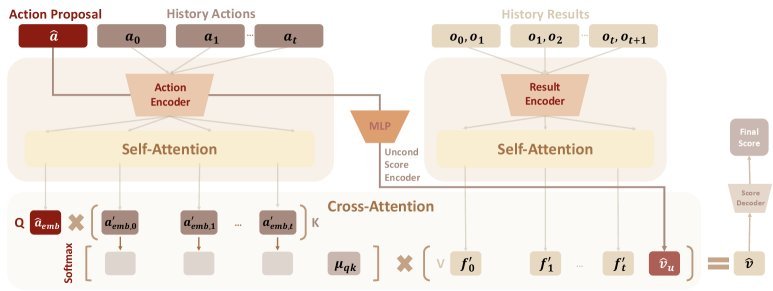
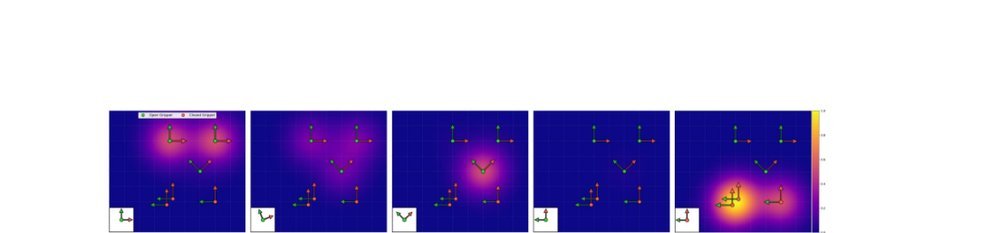
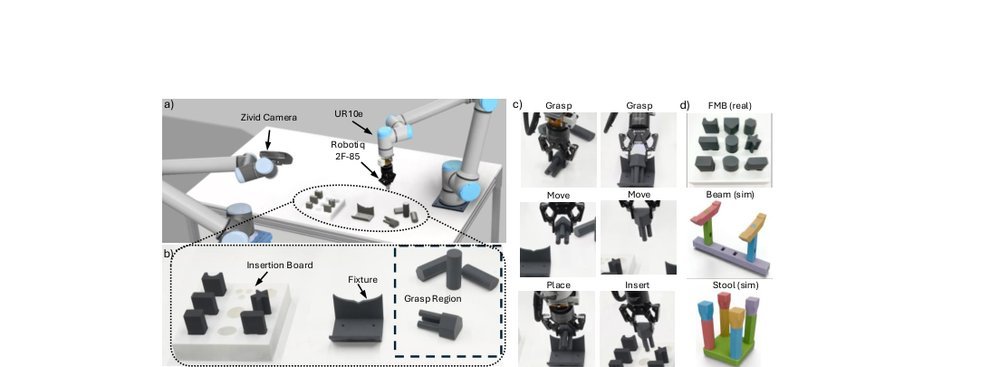
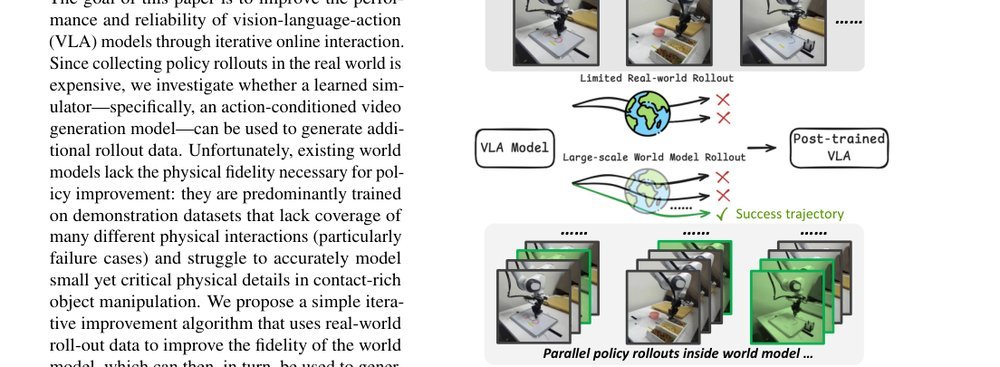
现有视觉-语言-动作(VLA)策略的在线后训练受限于真实世界rollout数据采集成本高昂,而现有世界模型因仅在演示数据上训练、缺乏对失败案例和接触丰富交互的覆盖,物理保真度不足,难以生成有效的合成数据。本文提出VLAW框架,利用少量真实在线rollout迭代微调世界模型以提升其对成功与失败轨迹的建模能力,进而生成大规模高保真合成数据,并结合视觉-语言奖励模型自动标注,通过稳定的监督学习目标优化VLA策略。实验表明,该方法在真实机器人接触丰富操作任务上使基础策略绝对成功率提升39.2%,其中合成数据贡献11.6%的增益。