精读笔记
Problem Setting
真正要解决的问题:为已经训练好的自回归通用机器人导航策略提供**运行时**、**可证明的**、**模型无关的**安全保证。困难点不在于"定义安全规范"(STL早已存在),而在于如何在不重新训练、不破坏预训练分布的前提下,将这些连续状态空间上的形式化约束注入到离散动作空间的解码过程中。传统后验过滤(如Simplex)会在违规时插入默认动作,打断自回归因果链;训练时嵌入(如SafeVLA)无法适应测试时的新规范。关键矛盾是:**安全约束是部署时给定的外部条件,而模型分布是训练时固定的内部属性**,两者需要在一个统一的推理框架中兼容。
Motivation
已有路线的核心不足:1) 重训练/微调成本过高,且随机模型无法通过训练"严格"满足逻辑约束;2) 后验过滤虽然简单,但导致模型内部隐状态与执行动作不匹配(自回归链断裂),任务成功率大幅下降。作者的观察来自NLP社区:约束解码(constrained decoding)能在不修改模型的情况下强制满足正则表达式或文法。关键缺口在于,NLP的约束定义在token字符串上,而机器人的约束定义在物理状态轨迹上。如果能在解码每个动作token时,通过近似动力学"快进"到未来状态,就能像检查token合法性一样检查动作的安全性。这促使作者将"语法约束"推广为"物理安全约束"。
Core Idea
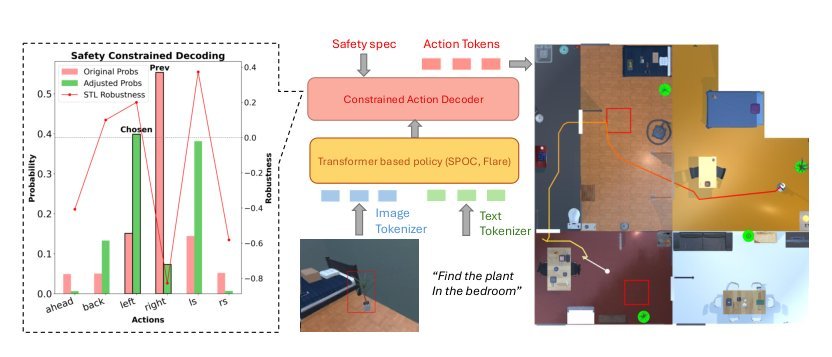
论文的核心思想是将**贝叶斯条件化**从语言token空间迁移到物理轨迹空间:理想的受约束策略应是无约束策略分布在安全轨迹事件上的后验 Q ∝ π · 1[φ]。SafeDec不是在生成完整轨迹后过滤,而是在自回归解码的每一步,基于动力学前向推演来预演动作的未来后果,并据此调整动作的概率质量。与prior的本质区别在于:1) 从"事后拒绝"转向"生成中引导",保留了自回归链的完整性;2) 利用STL的**quantitative robustness**(而非仅布尔满足度)作为连续信号进行软加权(RCD),这比二值化硬约束更能兼容预训练模型的分布特性。理论上,这种干预定义了一个新的、更接近原始分布的受限采样空间,从而在安全与任务性能之间取得更好的权衡。
Method
关键机制有三,均围绕"如何在解码阶段桥接动作token与状态空间"展开: 1. **前瞻式状态推演**:利用近似动力学模型(如unicycle)将候选动作映射到预测状态。这是必要组件,因为没有它,离散的action token无法与定义在连续状态上的STL发生关系。 2. **Hard Constrained Decoding (HCD)**:将STL布尔满足度作为硬掩码,零化违规动作的logits。这直接实现了对不变量规范的严格满足,但可能因动力学近似误差或局部死锁而过度保守。 3. **Robustness Constrained Decoding (RCD)**:将STL robustness分数转化为指数权重并平移logits。必要性在于:硬掩码在近似动力学下是"脆弱"的——一个因模型误差而被判定为边际违规的动作,在真实系统中可能是安全的。RCD通过保留长尾概率提供容错能力,将安全约束从0-1指示函数转化为连续优化信号。
Key Insight / Why It Works
方法有效的根本原因是**在自回归框架内重建了条件分布**,而非简单引入外部规则。HCD是贝叶斯条件化的硬近似,RCD是软近似;干预后的序列仍从一个良定义的分布中采样,因此保留了预训练归纳偏置。然而,必须清醒地看到:RCD相比HCD和过滤基线的优势,很大程度上来自于**更少地扭曲原始策略分布**(没有强制替换默认动作),而非RCD本身具备更深层的规划能力。文中所有实验基于单步lookahead,其"轨迹级"保证本质上是贪心局部决策的累积,无法处理需要多步协同的复杂时序约束。此外,在动力学噪声ablation中表现出的鲁棒性,说明RCD的核心价值是作为**解码阶段的正则化器**,而非精确规划器。如果基础策略本身在特定区域完全无法生成安全动作,SafeDec不具备纠偏能力——它只是重新排列现有动作的概率。
Relation To Prior Work
SafeDec属于**推理时对齐/约束**(inference-time alignment)谱系在机器人FMs上的延伸,与NLP中的Grammar-Aligned Decoding、LLM中的DExperts(分布引导)有方法论上的亲缘关系。与训练时安全方法(如SafeVLA)的本质差异:SafeDec将安全层与训练解耦,实现了测试时规范的可交换性。与SELP(LTL约束解码用于LLM规划器)的差异:SELP处理高层符号计划且依赖LTL的布尔语义;SafeDec处理低层连续状态动作,必须依赖STL的quantitative robustness来rank候选动作,这是问题域和逻辑表达力的实质扩展。与经典Shielding/Simplex的差异:后者是外接监控器+备用控制器,SafeDec则是内生于解码分布的重加权。需要指出的是,RCD用robustness加权logits的思想,本质上是将Control Barrier Function(连续空间的梯度修正)移植到了离散动作空间的softmax加权修正中,是一种跨领域的概念重组。
Dataset / Evaluation
在AI2-THOR的CHORES benchmark上评估,覆盖了三种训练范式迥异的通用导航策略(SPOC纯IL、PoliFormer混合RL+IL、Flare大规模预训练),这有效支撑了"模型无关"(agnostic)的claim。然而,评估存在明显局限:1) 规范类型极度单一,仅包含静态几何不变量(geofence/obstacle avoidance,即G算子),未涉及需要时序组合的复杂安全规范;2) 仅模拟环境,无真实世界或真机验证;3) 动力学模型采用unicycle抽象,虽然做了噪声ablation,但未在高维非线性动力学(如机械臂、足式机器人)上验证;4) 缺少与在线规划方法(如MPC+CBF)的对比——过滤基线已能实现100%安全,RCD的价值主要体现在任务成功率保留上,但这是否优于更精细设计的备用控制器,文中未充分论证。
Limitation
方法成立依赖两个强前提:**精确的状态估计**(规范定义在状态空间)和**近似动力学模型**。在纯视觉、开环、无显式定位的真实部署环境中,这一前提往往不成立;作者自己也承认这是"aerial robotics"等场景外的主要瓶颈。可扩展性上限方面,当前仅处理invariant规范(G算子),引入F/U算子后,单步贪心解码必然产生严重次优或不可满足的结果。更深层的问题在于:SafeDec并未真正"解决"安全问题,而是将问题**转移**给了动力学建模与状态估计;它只具备**选择能力**(在现有动作中挑选更安全的),不具备**纠偏能力**(若基础策略完全不生成安全动作则无能为力)。RCD的高任务成功率可能主要归因于**分布保持**(未强制插入默认动作),而非高级推理,这一点在文中未做充分归因分析。
Takeaway
- 1. 最值得迁移的insight:将形式化规范的**quantitative semantics**(如STL robustness)作为解码时的连续引导信号,比二值化的hard shielding更适合与大规模预训练模型耦合。
- 这种"软对齐"思路可推广至其他需要对foundation model施加物理或逻辑约束的生成任务。
- 2. 未来演化方向:当前 SafeDec 是单步贪心,下一步应自然走向**带鲁棒度评分的beam search/tree search**,将解码过程视为在动作空间中的受限搜索,而非单步重加权。
- 3. 真正值得做的工作:将SafeDec与**学习动力学模型**(world models)和**embedding-based逻辑**(无需显式状态估计)结合,消除当前对人工编写STL和精确状态的强依赖,从而向开放域机器人部署迈进。
一句话总结
SafeDec属于推理时约束对齐谱系,它通过将STL robustness注入自回归解码分布,在不修改模型参数的前提下为通用机器人导航策略提供了形式化安全保证,其核心贡献是证明软约束解码比硬过滤更能保留预训练策略的任务性能,尽管这种优势主要源于分布保持而非深层规划能力的涌现。