主页
← Embodied AI TopConf Index
+
点赞
0
Embodied AI TopConf · ICLR2025
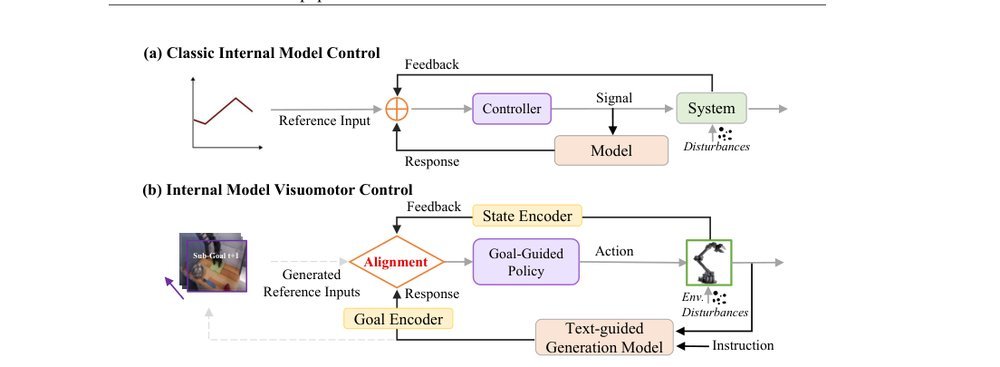
GEVRM: Goal-Expressive Video Generation Model For Robust Visual Manipulation
ICLR2025 / Video
视频
新标签打开 AlphaXiv
AlphaXiv 中文论文页面(可滚动查看)