精读笔记
Problem Setting
本文实际解决的不是“如何让 VLA 更大”,而是“如何让 VLA 在灵巧操作上获得互联网规模的预训练数据”。真正的困难点在于:人类视频与机器人控制之间存在结构性异构(视觉-文本 vs. 3D 物理动作+本体感知),导致以往基于隐式表示学习的方法无法有效迁移。关键矛盾是:人类操作视频数据海量但坐标系、相机、场景杂乱,且与机器人本体不匹配;直接拿来做预训练,模型要么学到的是视觉表面特征,要么被特定视角的伪相关劫持。
Motivation
已有 VLA 路线(基于机器人遥操作数据预训练)受限于数据规模,而基于人类视频的隐式方法(R3M、MAE、latent action)又缺乏明确的跨域迁移机制。作者的核心观察是:LMM 成功靠的是预训练与下游任务的同构对齐(视觉-文本理解直接用于多模态推理),而 VLA 缺的是“物理空间中的同构数据”。关键缺口在于:没有一个显式的、可扩展的中间表示,能同时被人类视频预训练和机器人后训练共享。因此,作者提出把人手当作通用 manipulator template,将其运动显式 token 化为语言模型能消化的离散序列,从而统一预训练与适配的接口。
Core Idea
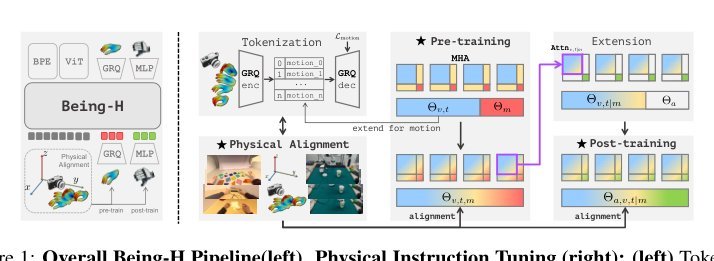
核心思想是“Physical Instruction Tuning”:将人手运动当作一种外语,通过离散 tokenization 纳入自回归 VLA,实现 vision-language-motion 的统一预训练。这改变了传统 VLA 直接端到端输出机器人动作的做法,引入了一个显式、可解释的人类动作中间层。其关键 inductive bias 有三层:第一,人手是进化出的最优灵巧模板,其运动学结构天然编码了抓握类型、接触模式和运动轨迹;第二,part-level tokenizer 将 wrist(全局运动)与 finger(精细操作)分离,匹配了运动学层次,使离散化能在压缩率与毫米级精度之间取得平衡;第三,预训练在统一物理空间内建立视觉-语言-人类动作的三方关联,后训练只需做一个低维的“本体映射”,无需重新学习视觉-动作关联。这本质上是用“显式结构先验+数据 scale”来填平异构鸿沟。
Method
只保留三个关键机制:1. Part-level Motion Tokenization:用 GRQ 分别量化 wrist 和 finger 的 MANO 参数。必要性在于 wrist 全局位姿分布广、finger 关节运动粒度细,统一量化要么浪费码本、要么丢失精细信息;分离量化让语言模型能分别建模“手在哪里”和“手指怎么动”。2. Perspective Spatial Alignment:通过 Weak-Perspective Projection 把所有异构数据源拉到统一坐标系,并用深度缩放+平面内旋转增强。必要性在于防止模型把不同数据集的区别当成任务信号,是大规模多源预训练的基础工程。3. Post-training Action Queries:冻结预训练 VLA,用可学习 query 提取动作 latent,再通过轻量 MLP/flow matching 映射到机器人。必要性在于保护预训练建立的 cross-modal attention 不被破坏,同时验证预训练学到的是高层通用策略而非特定本体技能。
Key Insight / Why It Works
方法真正有效的原因是:它把“人类视频→机器人控制”这个异构迁移问题,拆解成了“视觉-语言-人类动作对齐”和“人类动作→机器人动作映射”两个子问题,而前者可以通过大规模自回归预训练强力拟合,后者是一个低维映射。Part-level tokenizer 的毫米级精度确保了物理信息没有在离散化中流失;spatial alignment 确保了模型学到的是 3D 物理规律而非特定相机的像素统计。后训练只需 MLP 即可工作,是最强的证据——说明预训练模型已经内化了可迁移的物理行为先验。 但应直接指出:性能提升很可能主要来自更好的数据覆盖(UniHand 聚合 11 源)和显式监督信号(MANO 强结构先验),而非模型自发涌现出底层物理推理。Tail split 的显著提升恰恰是数据 scale 在起作用。此外,大模型在 free-format 到 block-format 的结构化生成上表现更好,说明它学到的是强条件生成与序列结构化能力,这与“推理”仍有距离。
Relation To Prior Work
与 GR00T N1.5 等最近的人类视频 VLA 相比,本质差异在于 GR00T 用隐式 latent action,而 Being-H 用显式可解码的手部运动 token,预训练目标更明确,后训练无需重建视觉-动作关联。与 OpenVLA、π0-FAST 等基于机器人遥操作预训练的 VLA 相比,Being-H 走的是“人类视频预训练→真机后训练”路线,用互联网数据解决灵巧操作的数据稀缺,但引入了 human-to-robot 的迁移 gap。 与 MotionGPT 等“motion as language”工作相比,Being-H 将其推进到了物理机器人控制闭环,并补充了 spatial alignment 和 part-level quantization 以应对真实视频的噪声与异构性。整体来看,本文属于“将 LMM 的 instruction tuning 范式推向物理空间”的技术谱系,真正的增量在于验证了该范式在 dexterous manipulation 和异构数据 scale 上的工程可行性,而非提出全新架构。
Dataset / Evaluation
UniHand 聚合 mocap、VR、RGB 视频共 150M 帧,是支撑规模化的关键。评估覆盖手部生成(head/tail split 设计合理,能验证长尾泛化)、仿真(LIBERO/RoboCasa)和真机(Franka+Inspire hand)。真机包含常规抓取与 contact-rich 任务(Spray-Plant),这是验证“灵巧操作”claim 的关键。但 evaluation 有明显局限:真机任务种类偏少(约 6 个),场景受控;LIBERO/RoboCasa 实际是 gripper 任务,不能直接证明 dexterous hand 相对 gripper 的优势;真机成功率仍有较大提升空间(如 Spray-Plant 仅 35%)。Benchmark 足以支撑“预训练优于无预训练”的结论,但尚未充分验证开放世界泛化与真正的 long-horizon 任务。
Limitation
方法成立的前提是 MANO 参数化对人手运动的良好覆盖,对非人形末端执行器迁移路径不明。后训练仍需 50–100 条真机演示,所谓 sample-efficient 只是相对无预训练 baseline,远未达到 zero-shot。真机失败案例集中暴露了两个本质短板:单目 RGB 的 3D 空间感知歧义,以及高层动作先验无法自动转化为低层精细力控(如 Spray-Plant 的触发器操作)。这说明当前框架只是把“从零学习策略”的困难,转移成了“在强先验下修正感知-控制残差”的困难,并未根本解决接触动力学建模问题。此外,性能提升的归因未完全解耦,数据覆盖、tokenizer 结构、alignment 策略各自的贡献不清。
Takeaway
- 1. 显式中间表示是大规模异构数据预训练的关键:将人类动作 token 化为离散语言,比隐式 latent action 更易 scale,且为下游提供了可解释的适配接口。
- 2. Physical Space Alignment 是数据工程的核心:统一坐标系与视角不变增强,比模型结构创新更能释放多源数据的潜力,可迁移到任何视频预训练机器人学习系统。
- 3. 预训练与后训练的职责分离值得遵循:预训练学“做什么”(高层物理行为先验),后训练学“怎么做”(本体映射),这是构建通用机器人策略的可扩展路径。
- 4. 下一步突破点不在更多视频数据,而在如何将触觉、力觉或多模态物理线索纳入 alignment 与 tokenization,以解决当前纯视觉框架在接触丰富操作上的天花板。
一句话总结
本文以人手为通用操作模板,通过显式 part-level 动作 token 化与物理空间对齐,首次实现了基于大规模人类视频的灵巧 VLA 预训练,验证了“物理指令微调”在桥接人类视频与机器人灵巧操作上的有效性,但其真机性能仍受限于单目感知瓶颈与高层先验到低层力控的映射精度。