精读笔记
Problem Setting
VLA 的核心瓶颈往往不是 action decoder 的容量,而是 condition representation 的质量。大规模 VLM 的嵌入空间对互联网视觉-语言语义高度敏感,但对机器人的 low-level 物理信号(本体状态、控制动作)几乎没有显式结构。这导致策略在跨场景、需要毫米级空间定位(如 pick-and-place)的任务中,过度依赖背景纹理和物体外观,而非机器人自身的物理状态。关键矛盾是:VLM 的“抽象”语义表示与机器人控制的“具身实例化”需求之间存在深层断层。
Motivation
已有路线中,冻结 VLM 直接接 decoder 显然次优;即使端到端微调,action prediction loss 的隐式梯度也远不足以重塑 VLM 表示的全局结构——作者可视化发现,VLM 嵌入仍按场景外观聚类,而非按任务进度或物理状态组织。另一条路线是继续在机器人数据上大规模预训练 VLM(embodied reasoning、action tokenization),但这需要额外 curated 数据与多阶段流程。缺的是一种无需额外语料、兼容现有 pipeline、且能显式将物理状态度量几何注入表示空间的轻量级手段。
Core Idea
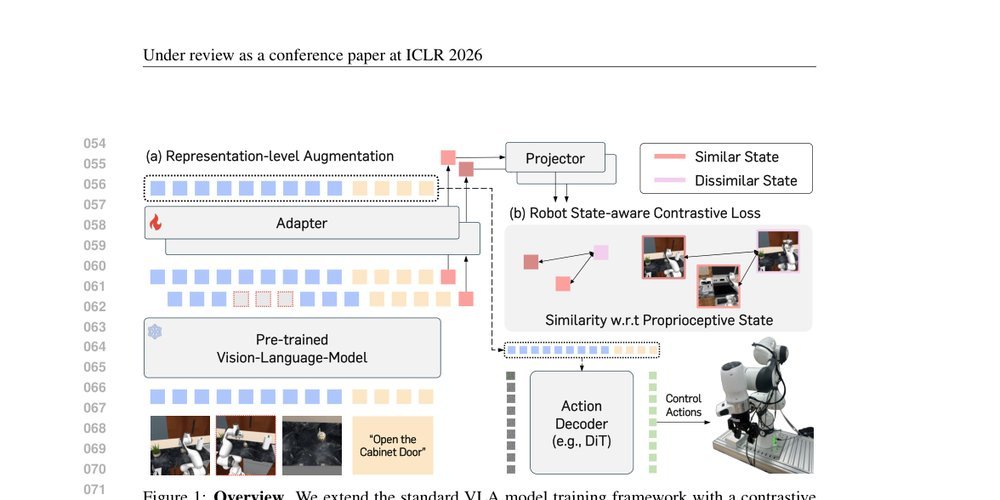
核心思想是把机器人本体状态(proprioceptive state)的度量几何当作“软锚点”,通过对比学习直接重标定 VLM 的 condition embedding 空间。不是让相同时刻或相同样本靠近,而是让“物理状态相近”的样本在嵌入空间中形成连续流形,从而让视觉-语言表示叠加一层控制相关的结构。为此,作者提出两项设计:一是 state-distance weighted contrastive loss,用 proprioception 的相对距离生成软标签,避免硬标签的离散误差;二是 view cutoff,在表示层随机剔除一个相机视角的特征,以零额外前向开销强制表示学习多视角不变性。这本质上是在不改变 VLM 预训练知识的前提下,用机器人自身的物理一致性对其表示空间进行“后校准”。
Method
真正必要的机制只有两点。第一,soft-weighted InfoNCE:权重由本体状态欧氏距离的 softmax 决定,这使得对比学习不再追求语义或时间等价,而是追求物理状态的一致性;它解决了硬对比损失无法表达“部分相似”的问题,允许表示在视觉变化下保持对物理状态的单调映射。第二,view-cutoff augmentation:直接在 VLM 输出的特征切片上 mask 单个视角,构造缺失视角的对比对;它解决了数据层增广需要多次 VLM forward 的计算瓶颈,同时利用机器人多相机设置的冗余性,强制表示解耦于单一视点。Summarization token 和 projector 仅为计算可行性服务,并非核心。
Key Insight / Why It Works
方法有效的根本原因是它把 action decoder 接收到的 condition 从“视觉场景描述符”转变成了“物理状态编码器”。在标准 VLA 训练中,action loss 的梯度对 VLM 深层表示的塑形能力有限,因为动作预测是高度非线性的局部监督;而 RS-CL 提供了一个全局的、基于物理度量的几何约束,迫使表示空间保留跨场景的任务进度结构。文中 CKNNA 和 KNN phase classification 证实,RS-CL 确实将表示对齐到了 proprioceptive manifold 上。不过需要区分:vanilla InfoNCE(无软标签)本身也能带来一定提升,说明“对比正则化”这一大类对 VLA 有益;RS-CL 的真正附加值在于 state-aware weighting 提供了更稳定的对齐信号,避免了将 next action 作为监督时引入的噪声。计算效率优势(相比 TCN)主要来自 view cutoff 的表示层操作,而非算法本质突破。增益在 LIBERO 这类相对简单、batch size 受限的任务上不明显,表明该方法对“视觉干扰强 + 定位精度要求高”的任务最有价值。
Relation To Prior Work
与继续预训练 VLM 的机器人适配路线(RoboBrain, VeBrain, Cosmos-Reason1, GEAR further training)本质不同:后者试图让 VLM“更懂机器人语言/推理”,需要额外数据和阶段;RS-CL 则假设 VLM 语义知识已足够,只需通过轻量级正则化将其“实例化”到物理状态空间。与 π0-FAST 等 action tokenization 路线也不同,RS-CL 不改变 action 建模方式。与 TCN、R3M、VIP 等机器人表示学习相比,RS-CL 不是独立的表示预训练,而是内嵌于 VLA 端到端训练的辅助目标;其“软距离权重”和“view cutoff”是针对多视图 VLA 场景的高效重组。总体上,它属于“利用机器人内部信号对基础模型进行 lightweight grounding”的技术谱系,核心新增信息是 proprioception-aware soft contrastive regularization。
Dataset / Evaluation
仿真覆盖了 RoboCasa-Kitchen(强调 pick-and-place 精确定位)和 LIBERO(多任务套件)。真实世界使用 Franka arm 执行 PnP 和 close-lid,并测试视觉、物理、语言和光照泛化。Evaluation 基本支持了核心 claim:RS-CL 提升的是空间定位精度和视角鲁棒性。但存在明显局限:真实实验任务数量极少(5 个任务),且 close-lid 的 partial success 指标容易模糊真实能力;RoboCasa 的 pick-and-place 增益显著,但其他任务类型增益有限,暗示方法并非万能。没有展示在需要复杂推理或长期规划的开放世界任务上的效果,因此不能推出“RS-CL 提升 VLA 通用性”的结论,只能说它改善了特定类型的控制表示。
Limitation
方法成立的关键前提是 proprioceptive state 与任务进度具有单调或至少平滑的相关性;在接触丰富的装配、形变操作或高度冗余的人形控制中,本体状态可能无法提供足够的任务判别信号。文中 from-scratch 实验的绝对成功率仍然很低(最高 21.3% 或 56.8%),说明 RS-CL 是对强基线的“增益器”,而非“构建器”——它无法弥补 backbone、数据量或 decoder 的根本不足。此外,lambda 的 cosine decay 到 0 意味着后期训练退化为纯 action prediction,表示对齐的持久性未经验证。真实世界的泛化测试仍属于轻度分布偏移(颜色、形状、光照),没有证据表明表示对齐带来了组合泛化或跨本体迁移。
Takeaway
- (1)对于 VLA 研究,condition representation 的“物理几何化”比继续堆砌视觉-语言语料更关键,action loss 的隐式梯度不足以完成这一转换。
- (2)RS-CL 提供了一种“免额外数据、免改动架构”的轻量级方案,适用于工业界在已有 VLA pipeline 上快速迭代。
- (3)View-cutoff 的思想可迁移到任何多视图策略学习:在表示层而非数据层做视角 dropout,是计算与鲁棒性之间的最优折中。
- (4)下一步真正值得探索的是将物体位姿、力/触觉等多模态物理信号纳入软对比框架,而不仅限于本体状态,以突破当前方法的感知上限。
一句话总结
这篇论文属于通过机器人本体状态的软对比正则化将预训练 VLM 语义空间轻量级“具身化”的技术路线,证明了无需额外机器人语料预训练,仅靠表示层对齐即可显著提升 VLA 在精确定位任务上的性能,其核心附加值在于“物理状态距离驱动的对比权重”与“零开销多视角表示增广”的高效结合。